 fhqTreap:无旋平衡树与操作详解
fhqTreap:无旋平衡树与操作详解





 本文介绍了fhqTreap,一种弱平衡的二叉搜索树,通过结合搜索树和堆的性质,避免了二叉搜索树退化为链。文章详细讲解了fhqTreap的定义、核心操作如分裂和合并,以及基本操作如插入、删除和查询。
本文介绍了fhqTreap,一种弱平衡的二叉搜索树,通过结合搜索树和堆的性质,避免了二叉搜索树退化为链。文章详细讲解了fhqTreap的定义、核心操作如分裂和合并,以及基本操作如插入、删除和查询。
fhq Treap 也叫无旋Treap (好像?我也不知道)
反正我带旋 Treap 是不会滴,其他的平衡树也不会(但是会平板电视)
fhq Treap 好写,码量小,缺点是常数比较大
定义
二叉搜索树
二叉搜索树是一种二叉树的树形数据结构,其定义如下:
-
空树是二叉搜索树。
-
若二叉搜索树的左子树不为空,则其左子树上所有点的附加权值均小于其根节点的值。
-
若二叉搜索树的右子树不为空,则其右子树上所有点的附加权值均大于其根节点的值。
-
二叉搜索树的左右子树均为二叉搜索树。
至于二叉搜索树怎么写我也不知道
但是由于可以构造数据使得二叉搜索树退化成一条链所以平衡树就应运而生了
平衡树是通过左旋和右旋各种奇怪的操作使左子树和右子树的高度最多相差 1 的二叉搜索树
Treap 就是一种弱平衡的平衡树
Treap 顾名思义就是 Tree + Heap 是加入了堆来防止二叉搜索树退化(说白了就是随机化)
其中,二叉搜索树的性质是:
左子节点的值( val \textit{val} val)比父节点大
右子节点的值( val \textit{val} val)比父节点小(当然这也是可以反过来的)
堆的性质是:
子节点值( key \textit{key} key)比父节点大或小(取决于是小根堆还是大根堆)
不难看出,如果用的是同一个值,那这两种数据结构的性质是矛盾的,所以我们再在搜索树的基础上,引入一个给堆的值 key \textit{key} key。对于 val \textit{val} val 值,我们维护搜索树的性质,对于 key \textit{key} key 值,我们维护堆的性质。其中 key \textit{key} key 这个值是随机给出的。
搬个 OI-Wiki 的图片
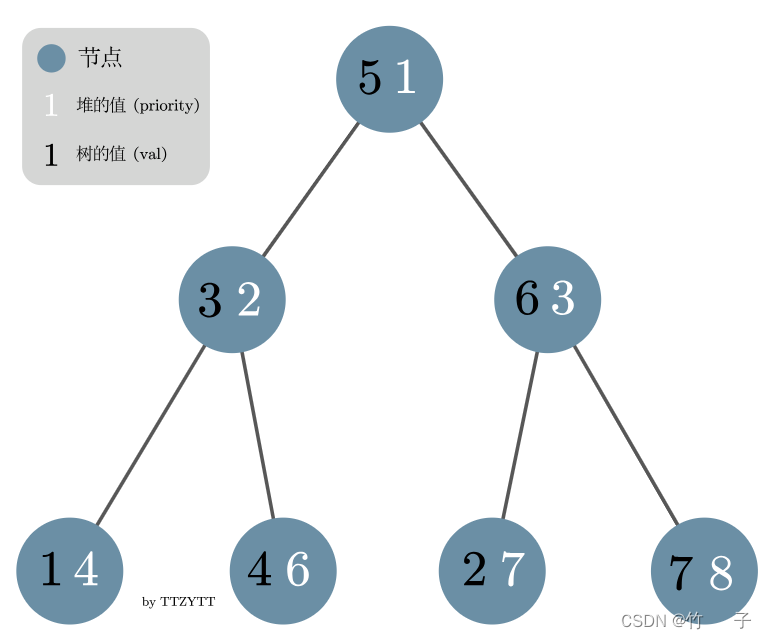
Treap 的核心操作是左旋和右旋 而 fhq Treap 则是不带旋的 Treap,很多情况下会一些操作好写很多
fhq Treap
fhq Treap 的核心操作是分裂 ( s p l i t split split) 和 合并 ( m e r g e merge merge)
节点信息
一个节点中的信息应该很好想罢,值 v a l val val ,键值 k e y key key, 左儿子 l l l ,右儿子 r r r 以及子树大小 s i z siz siz
struct treap{
int val,key,siz,l,r;
}fhq[N << 1];
建立新节点
建立一个新节点其实就是把一个节点初始化掉
int new_treap(int val){
fhq[++cnt].val = val;
fhq[cnt].key = rand();
fhq[cnt].siz = 1;
return cnt;
}
很好理解对吧
更新父节点信息
其实就和线段树的 p u s h _ u p push \_ up push_up操作是一样的
void push_up(int pos){
fhq[pos].siz = fhq[fhq[pos].l].siz + fhq[fhq[pos].r].siz + 1;
}
分裂
分裂操作有两种,一种是按值分裂,把所有值小于等于 v a l val val 的分裂成一颗树,把值 大于 v a l val val的分裂成一颗树;一种是按大小分裂,把小于等于给定大小的分裂成一棵树,大于给定大小的分裂成一颗树
一般把 fhq Treap 当正常平衡树使用的时候都是用按值分裂
直接看代码理解罢
void split(int pos, int val, int& x, int& y){
//因为是一棵树分裂成两颗树,返回pair会比较麻烦,所以直接引用一下
if(!pos) {
//到底了不能分裂
x = y = 0;
return 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











