






总线加锁机制和 MESI 缓存一致性协议
在CPU和主存之间增加缓存,在多线程场景下就可能存在缓存一致性问题,也就是说,在多核CPU中,每个核的自己的缓存中,关于同一个数据的缓存内容可能不一致。
-
总线加锁机制
大概意思是说,某个 CPU 如果要读一个数据,会通过一个总线,对这个数据加一个锁,其他 CPU 就没法去读和写这个数据了,只有当这个 CPU 修改完成以后,其他 CPU可以读到最新的数据,这个总线加锁机制效率太差了,一旦说多个线程出现对某个共享变量的访问之后,机会导致串行化的问题,现在已经弃用了.
-
MESI 缓存一致性协议
MESI 协议,建立了在 CPU 缓存模型下,多线程并发读写变量,可以互相感知到的一整套机制。
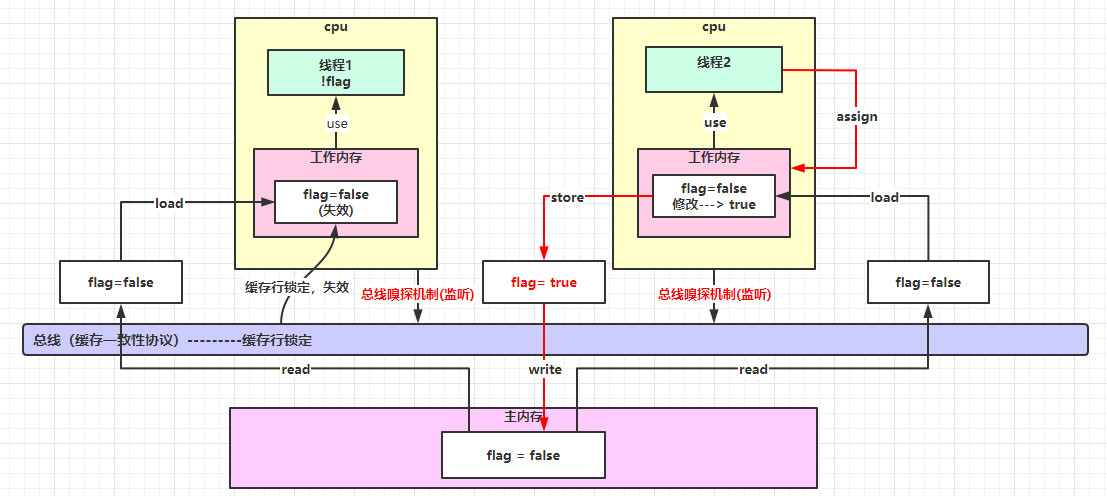
-
read(从主存读取)
-
load(将主存读取到的值写入工作内存)
-
use(从工作内存读取数据来计算)
-
assign(将计算好的值重新赋值到工作内存中)
-
store(将工作内存数据写入主存)
-
write(将store 过去的变量赋值给主存中的变量)
高速缓存结构与MESI协议分析
首先高速缓存的内部结构如下所示:
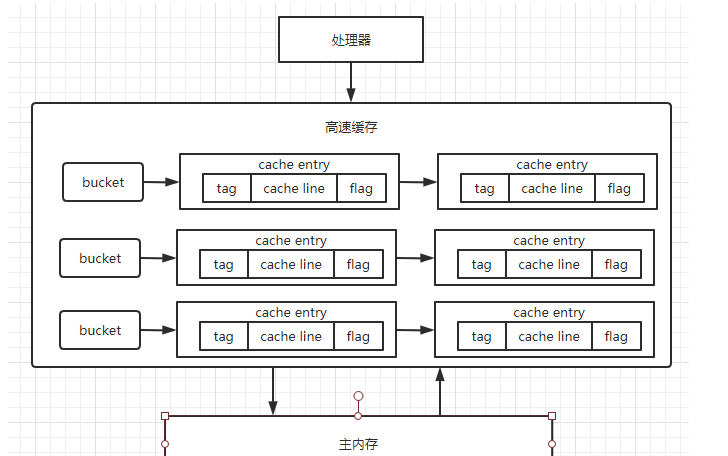
高速缓存内部是一个拉链散列表,是不是很眼熟,是的,和HashMap的内部结构十分相似,高速缓存中分为很多桶,每个桶里用链表的结构连接了很多cache entry,在每一个cache entry内部主要由三部分内容组成:
-
tag:指向了这个缓存数据在主内存中的数据的地址
-
cache line:存放多个变量数据
-
flag:缓存行状态CPU访问内存时,会通过地址解码得到三个数据:index,用于定位数据在哪一个桶中;tag,通过tag确定在哪一个cache entry中;offset,通过偏移量来获取对应的数据。flag一共有四种状态分别是:
-
M(修改,Modified):表示该cache line有效,且刚刚被修改过,与内存及其他高速缓存中数据不一致
-
E(独占,Exclusive):表示该cache line有效,且正在被独占进行修改,其他处理器不能对它进行修改
-
S(共享,Shared):表示该cache line有效,且数据与内存及其他高速缓存中一致
-
I(无效,Invalid):表示该cache line无效
-
由此引出了MESI缓存一致性协议,MESI协议对所有处理器有如下约定:
各个处理器在操作内存数据时,都会往总线发送消息,各个处理器还会不停的从总线嗅探消息,通过这个消息来保证各个处理器的协作。
同时MESI中有以下两个操作:
-
flush操作:强制处理器在更新完数据后,将更新的数据(可能写缓冲器、寄存器中)刷到高速缓存或者主内存(不同的硬件实现MESI协议的方式不一样),同时向总线发出信息说明自己修改了某一数据
-
refresh操作:从总线嗅探到某一数据失效后,将该数据在自己的缓存中失效,然后从更新后的处理器高速缓存或主内存中加载数据到自己的高速缓存中
接下来我们来说明在两个处理器情况下,其中一个处理器(处理器0)要修改数据的整个过程。假定数据所在cache line在两个高速缓存中都处于S(Shared)状态。
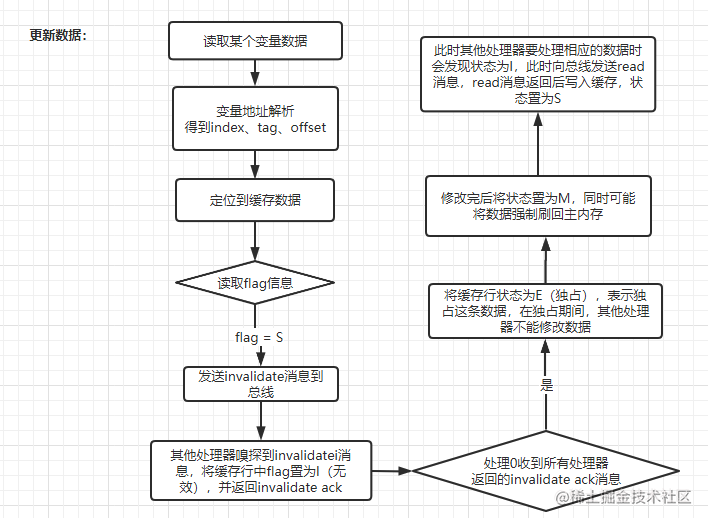
MESI协议能保证各个处理器间的高速缓存数据一致性,但是同样带来两个严重的效率问题:
-
当处理器0向总线发送invalidate消息后,要等到所有其他拥有相同缓存的处理器返回invalidate ack消息才能将对应的cache line状态置为E并进行修改,但是在这过程中它一直是处于阻塞状态,这将严重影响处理器的性能
-
当处理1嗅探到invalidate消息后,会先去将对应的cache line状态置为I,然后才会返回invalidate ack消息到总线,这个过程也是影响性能的。 基于以上两个问题,设计者又引入了写缓冲器和无效队列。 在上面的场景中,处理器0,先将要修改的数据放入写缓冲器,再向总线发出invalidate消息来通知其他有相同缓存的处理器缓存失效,处理器0就可以继续执行其他指令,当接收到其他所有处理器的invalidate ack后,再将处理器0中的cache line置为E,并将写缓冲器中的数据写入高速缓存。处理器1从总线嗅探到invalidate消息后,先将消息放入到无效队列,接着立刻返回invalidate ack消息。这样来提高处理的速度,达到提高性能的目的。加入写缓冲器和无效队列后,高速缓存结构如下图所示:
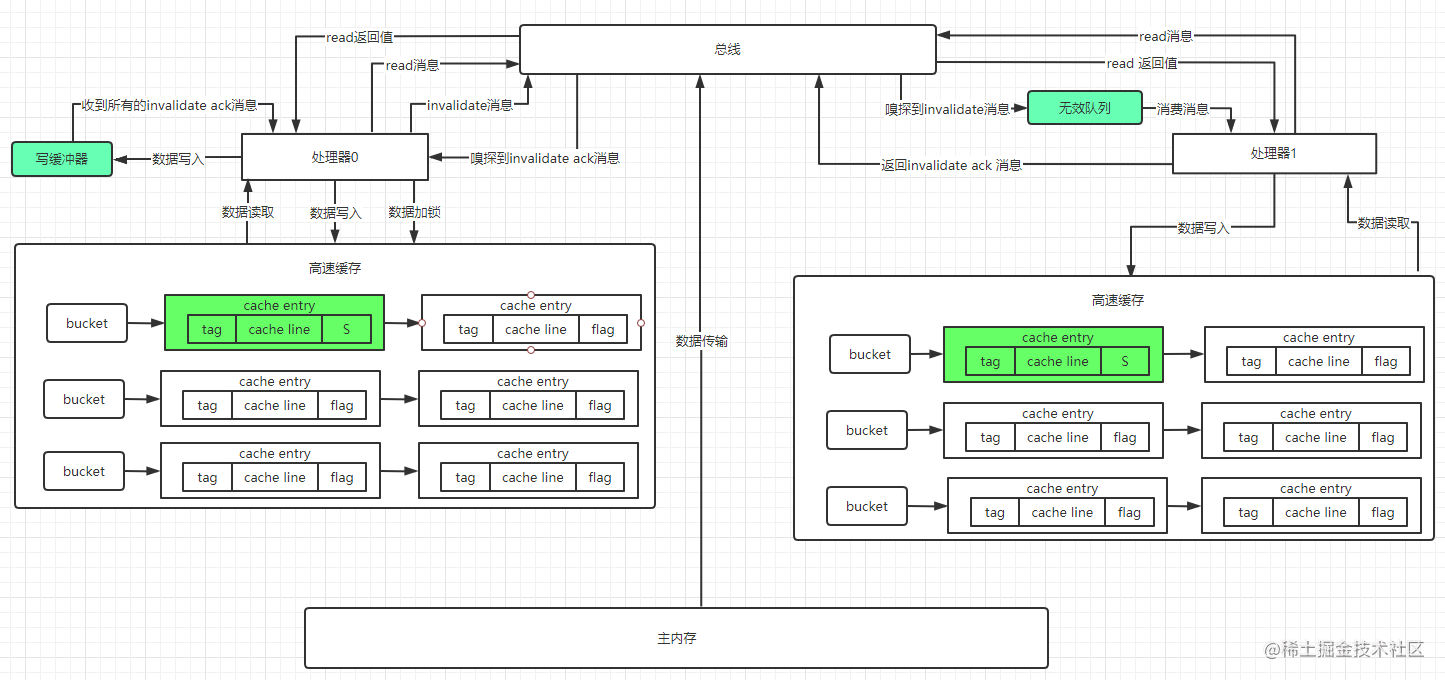
写缓冲器和无效队列带来的问题:
写缓冲器和无效队列提高MESI协议下处理器性能,但同时也带来了新的可见性与有序性问题如下:
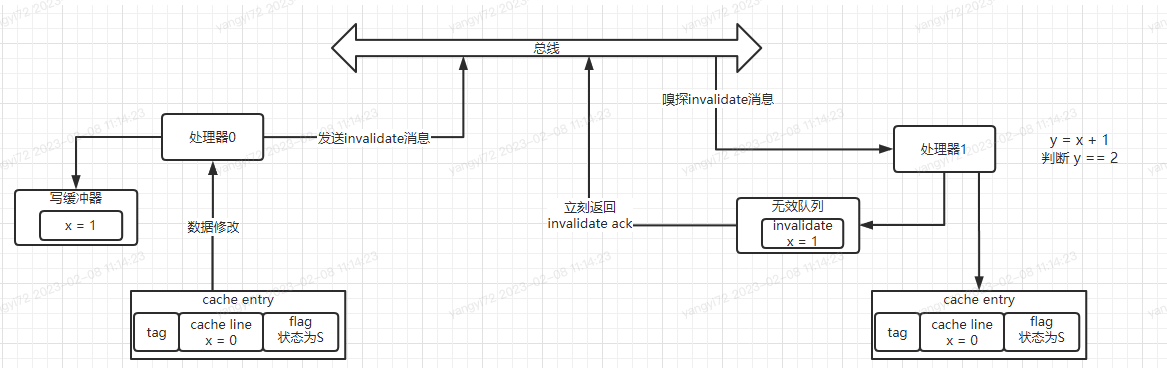
如上图所示:假设最初共享变量x=0同时存在于处理0和处理1的高速缓存中,且对应状态为S(Shared),此时处理0要将x的值改变成1,先将值写到写缓冲器里,然后向总线发送invalidate消息,同时处理器1希望将x的值加1赋给y,此时处理器1发现自身缓存中x=0状态为S,则直接用x=0进行参与计算,从而发生了错误,显然这个错误由写缓冲器和无效队列导致的,因为x的新值还在写缓冲器中,无效消息在处理1的无效队列中。
为了解决这个问题出现了写屏障(Store Barrier)和读屏障(Load Barrier)两种内存屏障。
-
写屏障:强制将写缓冲器中的内容写入到高速缓存中,或者将屏障之后的指令全部写到写缓冲器直到之前写缓冲器中的内容全部被刷回缓存中,也就是处理0必须等到所有的invalidate ack消息后,才能执行后续的操作,相当于flush操作;
-
读屏障:处理器在读取数据前,必须强制检查无效队列中是否有invalidate消息,如果有必须先处理完无效队列汇总的无效消息,再进行数据读取,相当于refresh操作。
通过加入读写屏障保证了可见性与有序性。之所以说保证了有序性,是因为指令乱序现象就是写缓冲器异步接收到其他处理器中的invalidate ack消息后,再执行写缓冲器中的内容,导致本应该执行的指令顺序发生错乱。通过加入写屏障后保证了异步操作之后才能执行后续的指令,保证了原来的指令顺序。















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









