







1. awk和sed的区别
-
sed的核心是正则,对于sed, 基本的两个概念是匹配和行为。
1. 匹配是通过区域选择加上正则表达式实现,比如“3到6行以This开头的”
2. 行为是增删改查。可以在某个位置新增或删除一行,可以通过正则表达式进行变量替换,可以显示满足某些条件的行。配合shell的批处理就会很强大, 比如我想把所有文件的开头添加一个注释,比如我想把所有文件的某一个变量进行替换,比如我想把所有文件满足某些条件的行进行合并和拆分。
3. 同时,sed提供了一个保持空间(hold space)可以实现逆序输出等操作。
4. 另外,sed的用法非常灵活,你可以将匹配和行为进行不同的嵌套,举个复杂的例子“将第某行到某行之间的满足A条件的里面满足B条件的行进行C操作和D操作并且将E条件的行进行F操作”这样的灵活组合方式怕是也只有sed了 -
awk,经常用于格式化输出,也就是将数据按照我们想要的方式来显示,并且可以做一些基本的统计工作。
1. 它的运作模式是“预处理+逐行处理+最终处理”。一般我们只用“逐行处理”比如对于满足条件的某些行,我们打印某某列。通过指定分隔符,我们很容易的对列进行操作。
2. 预处理来定义变量,逐行处理来修改变量,最终处理来打印变量。
2. awk使用
awk 'BEGIN{ commands } /pattern/ {commands} END{ commands }'
1、
BEGIN{ commands }开始块就是在程序启动的时候执行的代码部分,并且它在整个过程中只执行一次。一般情况下,我们可以在开始块中初始化一些变量。
注意:开始块部分是可选的,你的程序可以没有开始块部分。
2、/pattern/ {commands}pattern 部分匹配该行内容成功后,才会执行commands 的内容。
3END{ commands }结束块是在程序结束时执行的代码。
注意:结束块部分也是可选的
3. awk基本用法
| 选项 | |
|---|---|
| -F | -F ','或者 -F '正则表达式' -F选项来改变字段分隔符 |
| -v | -va=1赋值一个用户定义变量a的值为1 |
| -f | -f scripfile,从脚本文件中读取awk命令 |
$ cat 1.txt
2 this is a test1
3 Are you like awk1
This's a test1
10 There are orange,apple,mongo
------------------------------------------------------------------------------------------------------------
$ awk '{print $1,$4}' 1.txt # 每行按空格或TAB分割,输出文本中的1、4项
2 a
3 like
This's
10 orange,apple,mongo
------------------------------------------------------------------------------------------------------------
$ awk '{printf "%-8s %-10s\n",$1,$4}' 1.txt # 格式化输出
2 a
3 like
This's
10 orange,apple,mongo
--------------------------------------------------------------------------------------------
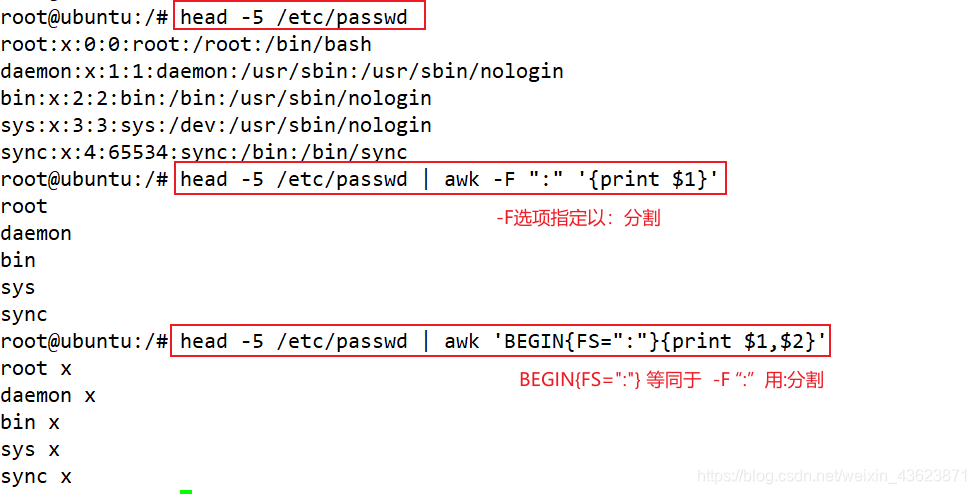
$ awk -F, '{print $1,$2}' 1.txt # 使用","分割。-F相当于内置变量FS, 指定分割字符
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
---------------------------------------------------------------------------------------------
$ awk 'BEGIN{FS=","} {print $1,$2}' 1.txt # 或者使用内建变量
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
-----------------------------------------------------------------------------------------------------
$ awk -F '[ ,]' '{print $1,$2,$5}' 1.txt # 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割
2 this test
3 Are awk
This's a
10 There apple
-----------------------------------------------------------------------------------------------------
$ awk -va=1 '{print $1,$1+a}' 1.txt # -v 设置变量
2 3
3 4
This's 1
10 11
$ awk -va=1 -vb=s '{print $1,$1+a,$1b}' 1.txt
2 3 2s
3 4 3s
This's 1 This'ss
10 11 10s
-----------------------------------------------------------------------------------------------------
$ awk -f cal.awk log.txt # awk -f {awk脚本} {文件名}
4. awk常用系统变量
| 变量 | 描述(列举常用的,还有很多其他的没怎么常用) |
|---|---|
| $n | $1当前记录的第1个字段的内容。和sed中的$1不同,sed表示第一个参数 |
| $0 | 整行数据的内容 |
| FS | 字段分隔符 (默认是空格) |
| OFS | 输出字段的分隔符(默认是空格) |
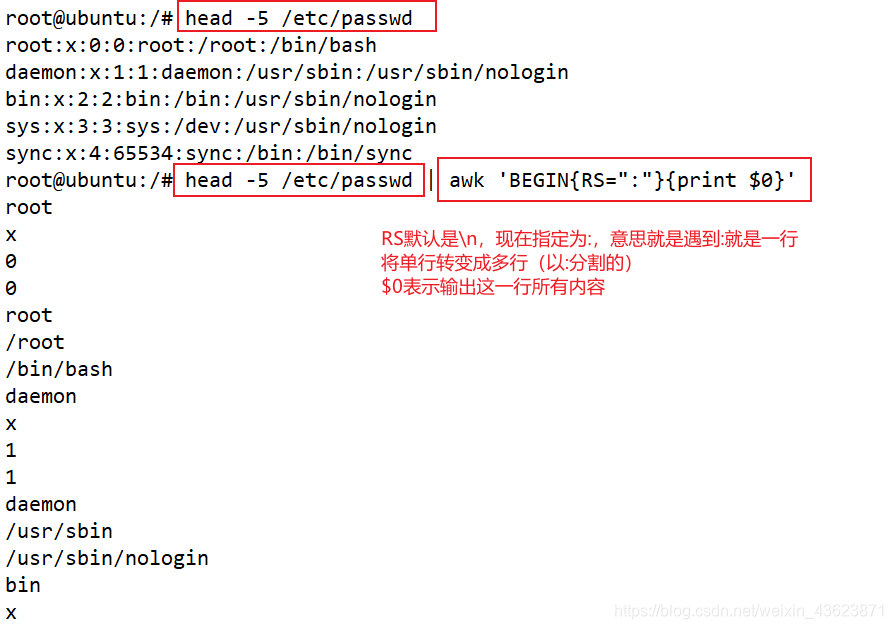
| RS | 行分隔符(默认以\n作为一行的结尾),单行分割成多行用到 |
| NR | 行号,从1开始,多文件时候也是连续接着计数 |
| FNR | 各文件分别计数的行号,多文件的时候会和NR不同,它会重新计数 |
| NF | 一行中字段数量,最后一个字段内容可以用$NF取出 |
| ARGC | 命令行参数的数目 |
| ARGV | 包含命令行参数的数组,第一个参数是命令awk |



$ cat log.txt
2 this is a test1
3 Are you like awk1
This's a test1
10 There are orange,apple,mongo
$ awk '/re/ ' log.txt # 输出包含 "re" 的行
---------------------------------- -----------
3 Are you like awk
10 There are orange,apple,mongo
$ awk 'BEGIN{IGNORECASE=1} /this/' log.txt #忽略大小写
---------------------------------------------
2 this is a test
This's a test
$ awk '$2 ~ /th/ {print $2,$4}' log.txt # 输出第二列包含 "th",并打印第二列与第四列 ~代表模式
---------------------------------------------
this a
$ awk '$2 !~ /th/ {print $2,$4}' log.txt #模式取反
---------------------------------------------
Are like
a
There orange,apple,mongo
$ awk '!/th/ {print $2,$4}' log.txt #模式取反(和上面一个是一样的效果)
---------------------------------------------
Are like
a
There orange,apple,mongo
$ ls -l *.txt | awk '{sum+=$5} END {print sum}' #计算文件大小
--------------------------------------------------
666581
$ awk 'length>80' log.txt #从文件中找出长度大于 80 的行
$ seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}' #打印九九乘法表
5. awk循环和数组
awk '{for(c=2;c<=NF;c++) print $c}' 1.txt
awk '{sum=0;for(c=2;c<NF;c++) sum+=$c; print sum/(NF-1)}' 1.txt #求每行的平均值
awk '{sum=0;for(c=2;c<NF;c++) sum+=$c;average[$1]=sum/(NF-1)} END{for(user in average) print user,average[user]}' 1.txt #用数组的方式求每行的平均数
awk '{sum=0;for(c=2;c<NF;c++) sum+=$c;average[$1]=sum/(NF-1)} END{for(user in average) sum2+=average[user];print sum2/NR}' 1.txt #求总数的平均值

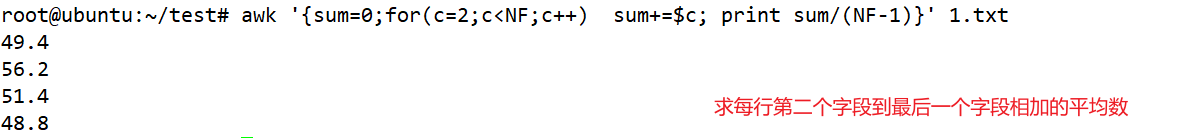
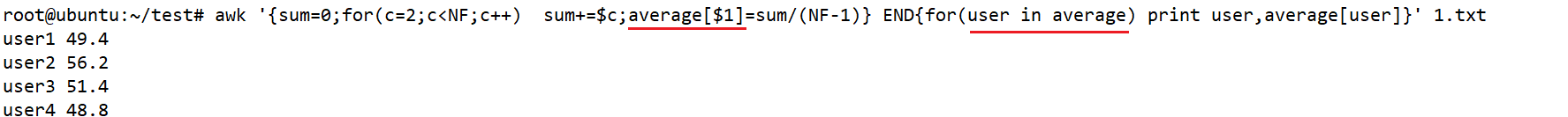
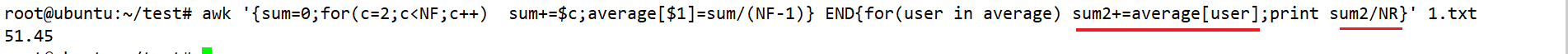
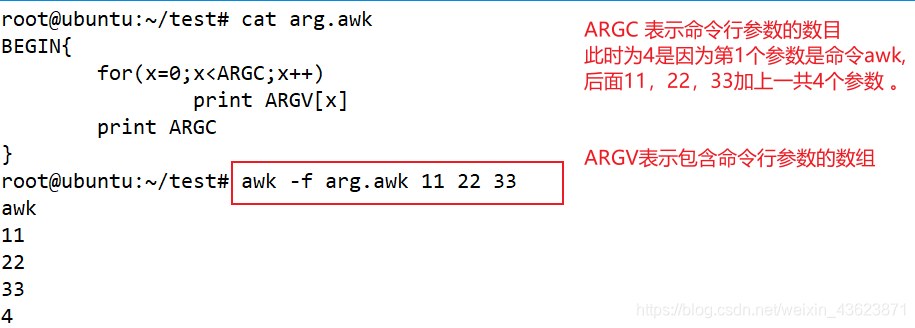
命令行参数数组
ARGC 命令行参数的数目
ARGV 包含命令行参数的数组














 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









