









前言
MapReduce学习的时候,读取文件夹下的所有文件,出现该报错,这里简单记录解决办法。
问题还原
项目结构
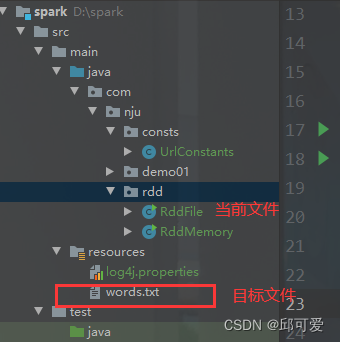
RddFile源码
该代码主要是读取Resource下的所有txt文件汇总成RDD流进行打印输出。
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("file");
try (JavaSparkContext ctx = new JavaSparkContext(conf)) {
JavaPairRDD<String, String> rdd = ctx.wholeTextFiles(new File(PATH).getParentFile().getCanonicalPath() +
File.separator + "*.txt");
rdd.collect().forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
启动之后报如下的错Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativ...
解决办法
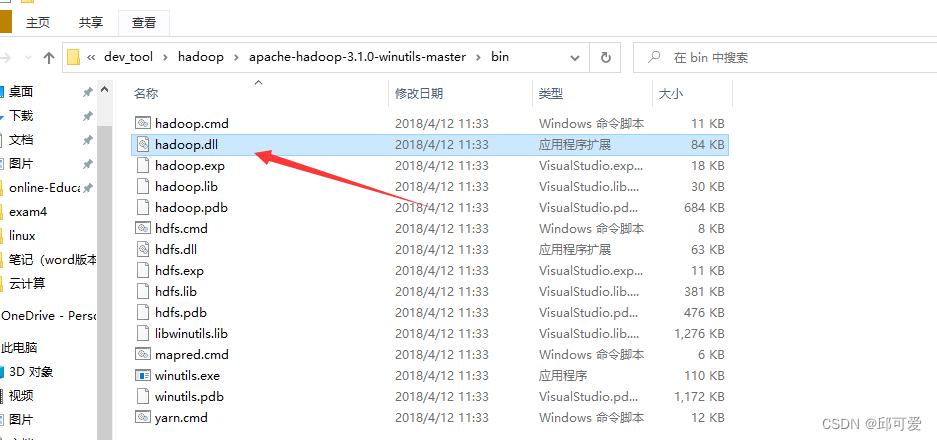
找到箭头所指的文件
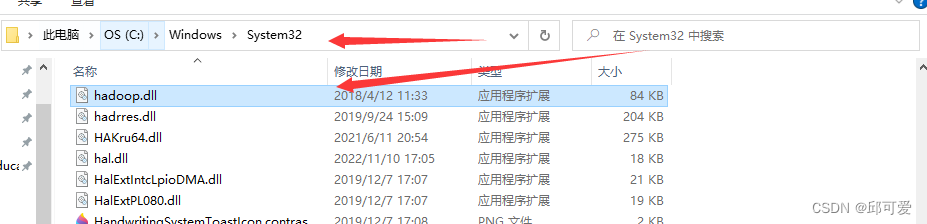
复制到如下文件夹
重新启动程序,问题解决














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









