









1. 调用百度文字识别接口&识别图片内容
百度识别接口申请地址
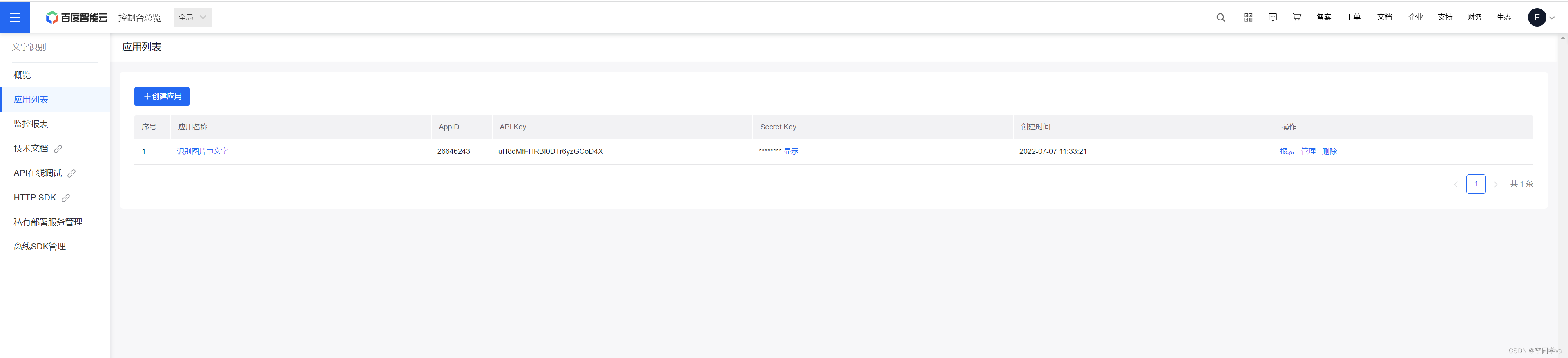
修改MyPath 路径即可
MyPath = 'E:\\pdf-图片\\'
filesoure = MyPath
def baiduduqu(filesoure, filename):
from aip import AipOcr
import re
import os
APP_ID = '26646243'
API_KEY = 'uH8dMfFHRBI0DTr6yzGCoD4X'
SECRET_KEY = ''
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
dakai = open(filename, 'rb')
duqu = dakai.read()
message = client.basicGeneral(duqu)
result = message.get('words_result')
if result is not None:
for duqu in message.get('words_result'):
print(duqu.get('words'))
with open("1pdf.txt", encoding='utf-8', mode="a") as f:
f.write(duqu.get('words') + '\n')
def filename(fielsoure, filetype):
import os
pathDir = os.listdir(filesoure)
for allDir in pathDir:
child = os.path.join('%s%s' % (filesoure, allDir))
print(child)
baiduduqu(filesoure, child)
def run():
import os
os.chdir(filesoure)
for i in os.listdir(os.getcwd()):
postfix = os.path.splitext(i)[1]
if postfix == '.jpeg' or postfix == '.png':
filename(filesoure, postfix)
if __name__ == '__main__':
run()
2. 使用easyocr库识别
2.1 安装Python 3环境
2.2 安装easyocr
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ easyocr
2.3 安装模型
网盘链接:
https://pan.baidu.com/s/1xyPsKORak447jS82Pt-JHg
提取码: onvl
复制到用户目录(python安装路径lib里面搜索) .EasyOCR\model
2.4 安装cv2
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ opencv-python
2.5 代码
model_storage_directory 是模型所在本地路径
import easyocr
def run():
reader = easyocr.Reader(['ch_sim', 'en'], gpu=False, model_storage_directory=r'C:\Users\Work\AppData\Local\Programs'
r'\Python\Python37\Lib\site-packages'
r'\easyocr\model')
context = ''
for i in range(53, 1507):
print('#' * 200 + ' 第{}页'.format(i))
path = r'E:\pdfImage-1\{}.png'.format(i)
result = reader.readtext(path)
print('#' * 200 + '长度:{}'.format(len(result)))
for j in range(5, len(result)):
print(result[j][1])
if __name__ == '__main__':
run()
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











