






考试答题偶然一次需要提取图片中的文字,所以搜索了一下解决方法
测试代码如下:
from PIL import Image
import pytesseract
text=pytesseract.image_to_string(Image.open('../Demo/Chinese.png'),lang='chi_sim')
print(text)
1.第一步首先的话需安装pytesseract和Pillow库
2.然后的话安装识别引擎tesseract-ocr
地址:https://github.com/UB-Mannheim/tesseract/wiki
根据自己的需求选择其中w32表示32位系统,w64表示64位系统下载,对应的版本即可
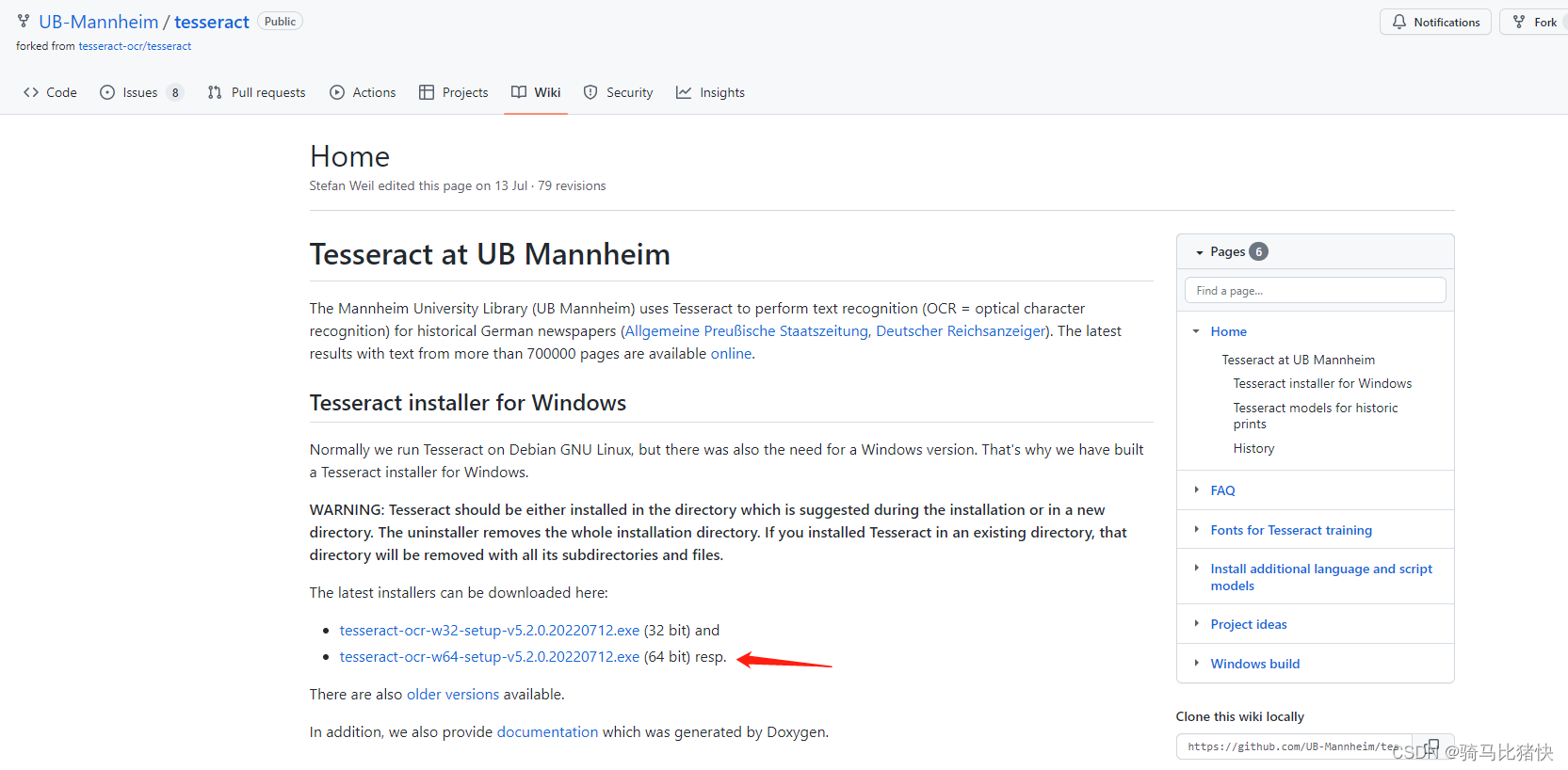
3.下载后安装tesseract-ocr,安装后还需进行环境变量
根据自己实际的安装路径即可
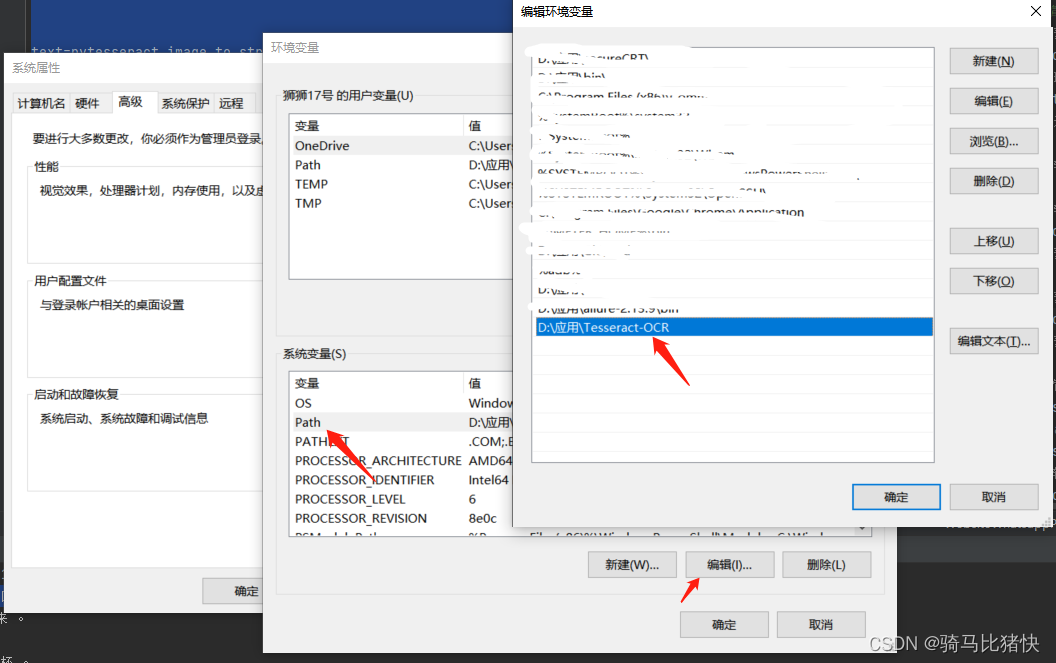
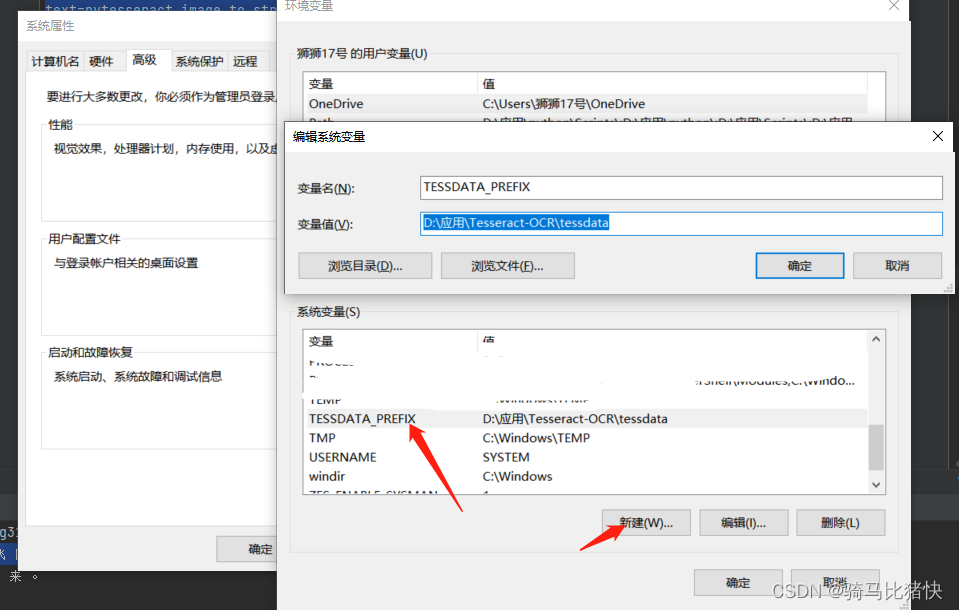
TESSDATA_PREFIX
D:\应用\Tesseract-OCR\tessdata
4.然后还需修改pytesseract.py文件,在python下的Lib\site-packages\pytesseract,找到pytesseract.py并修改其中的tesseract_cmd
tesseract_cmd = r'D:\应用\Tesseract-OCR\tesseract.exe'
之后就可以运行了。
5.如果需识别中文的情况下,还需单独安装上识别引擎是无法识别中文的,需要另外下载一些东西
地址:https://github.com/tesseract-ocr/tessdata
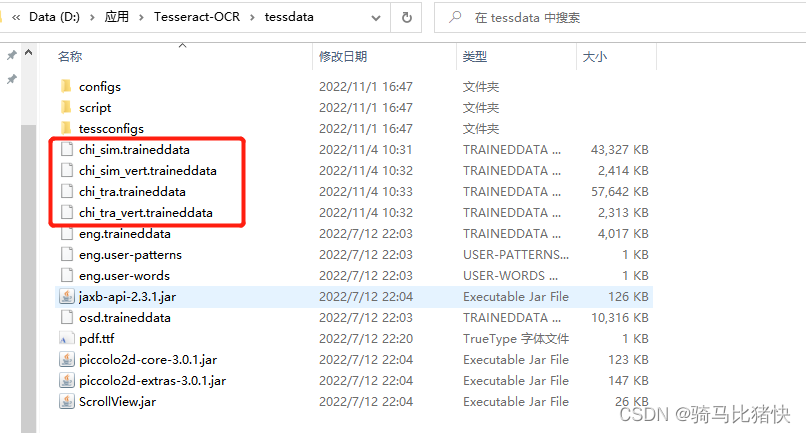
将里面的 chi_sim.traineddata、chi_sim_vert.traineddata、chi_tra.traineddata和chi_tra_vert.traineddata文件放入tesseract-ocr的tessdata目录下
找了个图片实验了一下
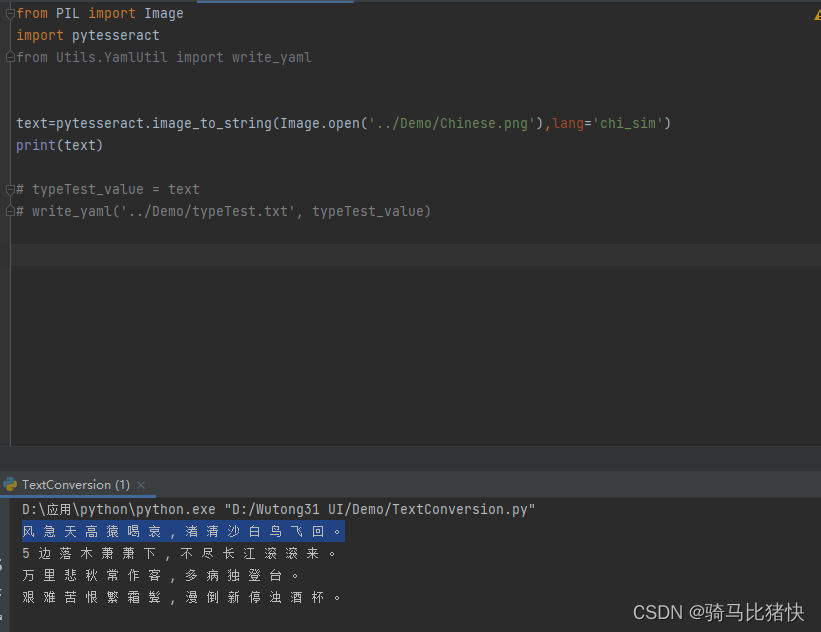
总的来说不是很准确,Tesseract对手写体、行楷等飘逸的字体识别不准确,对一些复杂的字识别也有待提升。但是宋体、印刷体等笔画严谨的字体识别准确率很高。另外如果图片的倾斜大于一定的角度,识别结果也会有很大差别。















 5142
5142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









