






base64篇
base64严格意义说并不是一种加密方式,而是一种编码方式,标准的base64有很多的特征例如字符串中常常会看到"+“和”",在末尾也时常看到两个连续的"="
1、原理:
base64将每三个字节分成一组(24bit),再将这一组数据数据按照每6个bit进行切割,这样就切割出了4个小组,在将每个小组高位补0,凑齐8bit,在对应base64转化表,将其转化为新的编码。
这里需要注意的是当字符串不是3的倍数时,需要用0对字符串进行补齐,将其转化为3的倍数,然而最后必然会产生全0值,而base64编码表的0对应的通常是’A’,这样在解码时会造成极大的麻烦,因此引入了’='字符串,对末尾的0进行编码,由于base64的特性可能会导致其末尾出现一个或者最多两个0的情况
示例(1):当字符串为三的倍数时:
| 字符 | 6 | 6 | 6 | 6 | 6 | 6 | * | * |
|---|---|---|---|---|---|---|---|---|
| 16进制表示 | 0x36 | 0x36 | 0x36 | 0x36 | ||||
| 2进制表示 | 00110110 | 00110110 | 00110110 | 00110110 | 00110110 | 00110110 | ||
| 每6位切割处理后 | 001101 | 100011 | 011000 | 110110 | 001101 | 100011 | 011000 | 110110 |
| 对比base64编码表后 | 0xD | 0x23 | 0x18 | 0x36 | 0xD | 0x23 | 0x18 | 0x36 |
| 对应的base64字符 | N | j | Y | 2 | N | j | Y | 2 |
示例(2):当字符串不为三的倍数时:
这个时候就需要用0将不足三个补齐三个
| 字符 | 6 | 6 | * | * |
|---|---|---|---|---|
| 16进制表示 | 0x36 | 0x36 | 0x0(补齐) | |
| 2进制表示 | 00110110 | 00110110 | 00000000 | |
| 每6位切割处理后 | 001101 | 100011 | 011000 | 00000 |
| 对比base64编码表后 | 0xD | 0x23 | 0x18 | 0x0(末尾0) |
| 对应的base64字符 | N | j | Y | = |
2.1、C语言实现(加密):
1.对输入的字符串进行判断并补成3的倍数
unsigned int SixBitGroupSize; //明文6Bit组大小
unsigned char* BitPlainText; //明文Bit组
if (strlen(PlainText) % 3) //不是3的倍数
{
BitPlainSize = (strlen(PlainText) / 3 + 1) * 3;
SixBitGroupSize = (strlen(PlainText) / 3 + 1) * 4;
}
else //是3的倍数
{
BitPlainSize = strlen(PlainText);
SixBitGroupSize = strlen(PlainText) / 3 * 4;
}
这很简单根据实际情况对明文bit组的大小和6bit组的大小进行修正就可以了
2.将已经为3的倍数的字符串(3x8bit)转化成(4x6bit)
int TransitionSixBitGroup(unsigned char *BitPlainText, unsigned char* SixBitGroup, unsigned int SixBitGroupSize)
{
int ret = 0;
//1、每4个6Bit组一个循环
for (int i = 0, j = 0; i < SixBitGroupSize; i += 4, j += 3)
{
SixBitGroup[i] = ((BitPlainText[j] & 0xFC) >> 2);
SixBitGroup[i + 1] = ((BitPlainText[j] & 0x03) << 4) + ((BitPlainText[j + 1] & 0xF0) >> 4);
SixBitGroup[i + 2] = ((BitPlainText[j + 1] & 0x0F) << 2) + ((BitPlainText[j + 2] & 0xC0) >> 6);
SixBitGroup[i + 3] = (BitPlainText[j + 2] & 0x3F);
}
return ret;
}
for循环代码分析:
(1)SixBitGroup[i] = ((BitPlainText[j] & 0xFC) >> 2);
根据&操作符的特性,将8位二进制数据保留前6位,在将前6位数据右移2位实现补零操作

(2)SixBitGroup[i + 1] = ((BitPlainText[j] & 0x03) << 4) + ((BitPlainText[j + 1] & 0xF0) >> 4);
将第一个8位的后两位提出来,左移4位作为第二个6bit的高位和第二个8位的前4位进行相加
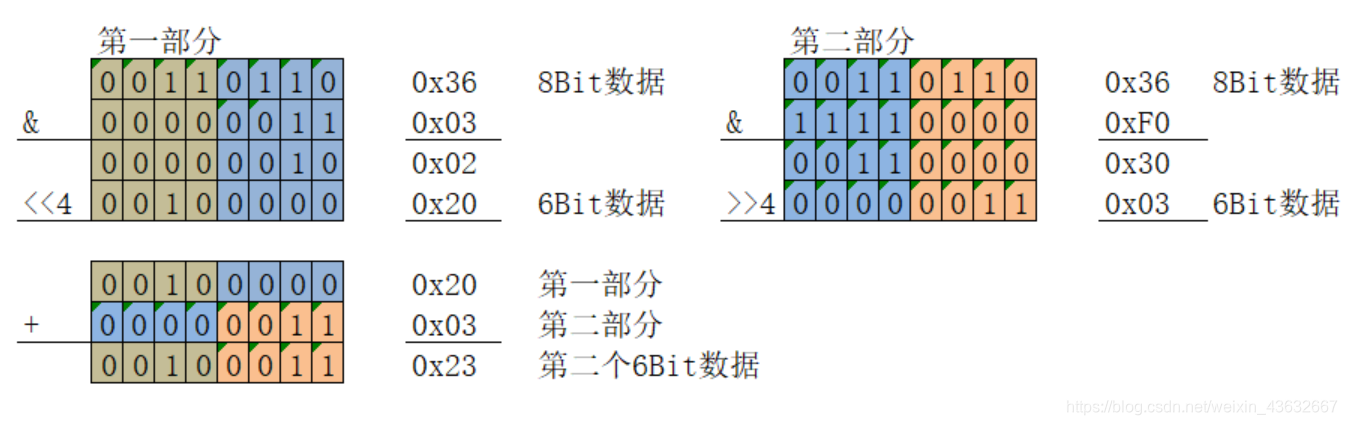
(3)SixBitGroup[i + 2] = ((BitPlainText[j + 1] & 0x0F) << 2) + ((BitPlainText[j + 2] & 0xC0) >> 6);
将第二个8位的后四位提取出来,向左移2位作为高位和第三个8位的前两位右移6位到最低位,后相加
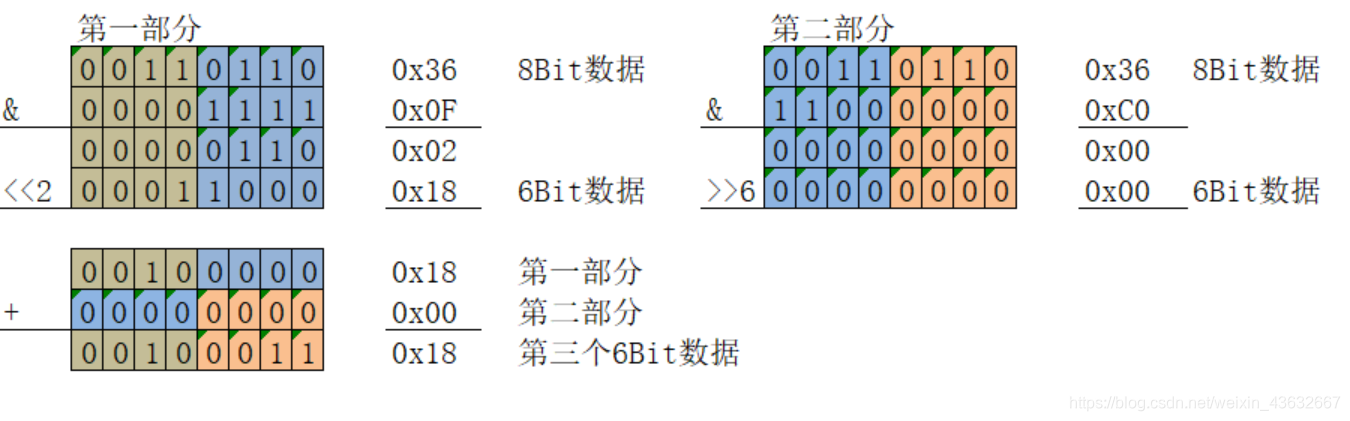
(3)SixBitGroup[i + 3] = (BitPlainText[j + 2] & 0x3F)
将第3个8位的后6位直接提取出来

3.获取6bit转换成功后的字符串
unsigned char Base64Table[64] =
{
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'G', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/'
};
int GetBase64String(unsigned char *CipherGroup, unsigned char *SixBitGroup, unsigned int SixBitGroupSize)
{
int ret = 0;
for (int i = 0; i < SixBitGroupSize; i++)
{
CipherGroup[i] = Base64Table[SixBitGroup[i]];
}
return ret;
}
4.获取6bit转换成功后的字符串最后两位,若为’A’则将其转化为’=’
for (int i = SixBitGroupSize - 1; i > SixBitGroupSize - 3; i--)
{
if (CipherGroup[i] == 'A')
{
CipherGroup[i] = '=';
}
}
2。2、C语言实现(解码):
1.首先将编码的字符串转化为对应的值
int GetBase64Index(unsigned char *CipherText, unsigned char *Base64Index, unsigned int Base64IndexSize)
{
int ret = 0;
for (int i = 0; i < Base64IndexSize; i++)
{
//计算下标
if (CipherText[i] >= 'A' && CipherText[i] <= 'Z') //'A'-'Z'
{
Base64Index[i] = CipherText[i] - 'A';
}
else if (CipherText[i] >= 'a' && CipherText[i] <= 'z') //'a'-'z'
{
Base64Index[i] = CipherText[i] - 'a' + 26;
}
else if (CipherText[i] >= '0' && CipherText[i] <= '9') //'0'-'9'
{
Base64Index[i] = CipherText[i] - '0' + 52;
}
else if (CipherText[i] == '+')
{
Base64Index[i] = 62;
}
else if (CipherText[i] == '/')
{
Base64Index[i] = 63;
}
else //处理字符串末尾是'='的情况
{
Base64Index[i] = 0;
}
}
return ret;
}
其实也可以通过索引Base64Table[64]数组,但是这样做会极大增加时间复杂度,因此在C语言中没有这么做
2.将4X6Bit组转换为3X8Bit组形式
int TransitionEightBitGroup(unsigned char *BitPlainText, unsigned char *Base64Index, unsigned int Base64IndexSize)
{
int ret = 0;
for (int i = 0, j = 0; j < Base64IndexSize; i += 3, j += 4)
{
BitPlainText[i] = (Base64Index[j] << 2) + ((Base64Index[j + 1] & 0xF0) >> 4);
BitPlainText[i + 1] = ((Base64Index[j + 1] & 0x0F) << 4) + ((Base64Index[j + 2] & 0xFC) >> 2);
BitPlainText[i + 2] = ((Base64Index[j + 2] & 0x03) << 6) + Base64Index[j + 3];
}
F
return ret;
}
这个跟前面一样也是相关的位移、取出指定位的操作
3、python:
import base64
#加密
s = '66'
a = base64.b64encode(s.encode('utf-8'))
print(a)
#解密
print (base64.b64decode(a))
补充:
ctf题可能出现base64变码的情况这个时候就需要进行一些转化:
import base64
table_tmp = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'N', 'M','O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b','c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p','q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '9', '1', '2', '3','4', '5', '6', '7', '8', '0', '+', '/']
table_original = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
table_tmp_str = ''
str1 = ''
for i in table_tmp:
table_tmp_str += i
print(table_tmp_str)
print(base64.b64decode(str1.translate(str.maketrans(table_tmp_str,table_original))))
4.java
思路和C语言基本相同
public class Base64Realize {
//进行base64映射的字符数组
private final static char[] str = {'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z',
'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z',
'0','1','2','3','4','5','6','7','8','9','+','/'};
/**
* 获取解码器
* @return
*/
public static Base64Realize getDecoder(){
return new Base64Realize();
}
/**
* 解码
* @param code
* @return
*/
public String decode(String code){
//对字符串的长度进行计算
int length = code.length();
//判断长度的合法性
if(length == 0 || length % 4 != 0)
return null;
//获取字符串末尾的'='号数目
int endEqualNum = 0;
if(code.endsWith("=="))
endEqualNum = 2;
else if(code.endsWith("="))
endEqualNum = 1;
//对末尾的=号进行替换
code.replace('=','0');
StringBuilder sb = new StringBuilder(length);
//解码
int blockNum = length / 4;
String afterDecode = "";
for(int i = 0;i < blockNum;i++){
afterDecode = decodeDetail(code.substring(i * 4,i * 4 + 4));
sb.append(afterDecode);
}
//返回字符串
String result = sb.toString();
return result.substring(0,result.length() - endEqualNum);
}
/**
* 编码
* @param code
* @return
*/
public String encode(String code){
//初始化判断
if (code == null || code.equals(""))
return null;
//获取需编码字符串的长度
int length = code.length();
StringBuilder sb = new StringBuilder(length * 2);
//转化为char型数组
char[] code1 = code.toCharArray();
//获取长度对3的取余
int mod = length % 3;
//获取长度对3的倍数的
int div = length / 3;
//编码
for(int i = 0;i < div;i++){
int temp = i * 3;
sb.append(encodeDetail(code1[temp],code1[temp + 1],code1[temp + 2]));
}
//对超出的进行额外的编码
if (mod == 1) {
String str = encodeDetail(code1[length - 1], '\0', '\0');
sb.append(str.substring(0,str.length() - 2) + "==");
}
if(mod == 2) {
String str = encodeDetail(code1[length - 2], code1[length - 1], '\0');
sb.append(str.substring(0,str.length() - 1) + "=");
}
return sb.toString();
}
/**
* 编码的详细步骤
* @param a1
* @param a2
* @param a3
* @return
*/
private String encodeDetail(char a1,char a2,char a3){
char[] b = new char[4];
b[0] = str[((a1 & 0xFC) >> 2)];
b[1] = str[(a1 & 0x03) << 4 | (a2 & 0xF0) >> 4];
b[2] = str[(a2 & 0x0F) << 2 | (a3 & 0xC0) >> 6];
b[3] = str[(a3 & 0x3F)];
return String.copyValueOf(b);
}
/**
* 解码的详细步骤
* @param str
* @return
*/
private String decodeDetail(String str){
int len = str.length();
if(len != 4)
return null;
char[] b = new char[3];
int a1 = getIndex(str.charAt(0));
int a2 = getIndex(str.charAt(1));
int a3 = getIndex(str.charAt(2));
int a4 = getIndex(str.charAt(3));
b[0] = (char) (a1 << 2 | (a2 & 0x30) >> 4);
b[1] = (char) ((a2 & 0x0F) << 4 | (a3 & 0x3C) >> 2);
b[2] = (char) ((a3 & 0x03) << 6 | a4);
return String.copyValueOf(b);
}
/**
* 获取字节的映射位置
* @param c
* @return
*/
private int getIndex(char c){
for(int i = 0;i < str.length;i++){
if(str[i] == c)
return i;
}
return -1;
}
/**
* 获取编码器
* @return
*/
public static Base64Realize getEncoder(){
return new Base64Realize();
}
}
参考链接:https://bbs.pediy.com/thread-253433.htm















 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









