







Learning Journey2.3
第二周DAY3
今日思考
忧郁的心啊,你为何不肯安息,
是什么刺得你双脚流血地奔逃,
你究竟期待着什么? - 尼采
《查拉图斯特拉如是说》—— 列入想读清单。
多数之弱者为少数之强者所压迫,
或
少数之优者为多数之劣者所牵制?
Naive Bayes 7.0(Test)
新代码,这是在测试,输入一些词汇,来判断是abusive or not abusive。
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
实验结果:
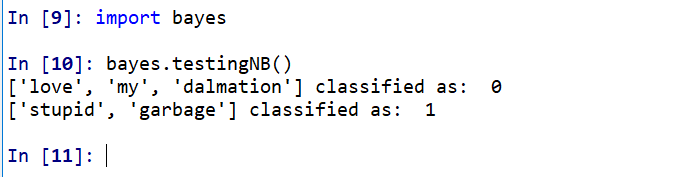
1 代表这些词汇是带有侮辱性的,而0,则不带有侮辱性。
代码的逻辑,明天做个流程图,好好理解一下,加油!














 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









