









0. 希望后面可以写一些有趣的代码
《数据结构与算法分析(Java语言描述) 第三版》第4章 树 4.7 B树
1.索引的物理存储
几种最小存储单元:

磁盘IO=寻道+旋转:
内存IO基于电位的特性
物理层面来看,像是在一块二维空间中寻址
效率之高,几乎可以说是线性的
两次读取可以不考虑之间的"距离",即两块物理地址之间的连续性
磁盘IO主要依赖于机械运动(寻道+旋转)
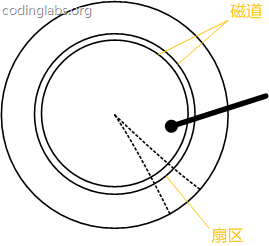
寻道:移动磁头到指定的物理空间(一片磁盘的某一个同心环),相对来说,这个过程比较耗费时间
旋转:旋转该片磁盘以读取一段连续的存储空间(同心环中的某一段扇区,也是磁盘IO最小存储单元),相对来说是非常快的
最小存储单元
物理层面:
计算机存储:扇区
逻辑层面:
InnoDB存储引擎:页page
文件系统(例如XFS/EXT4):块block
虽然以上的字节大小不尽相同,但实际的数据交换时并不冲突
举个栗子:硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(所以IO一次就是读一页的大小)
索引文件的体积很大&内存IO的效率是远高于磁盘IO的
索引文件存储在磁盘中
需要使用到的索引从磁盘中按页读取并缓存到内存中
预读=>磁盘IO的局部性原理:如果一个存储器的某个位置被访问,那么将它附近的位置也会被访问
2. 快速索引的瓶颈——磁盘IO
一般而言内存访问的时间约为 50 ns,而磁盘在 10 ms 左右。速度相差了近 5 个数量级,磁盘读取时间远远超过了数据在内存中比较的时间。这说明程序大部分时间会阻塞在磁盘 IO 上。
因此,我们需要一种可以迎合磁盘顺序存储、局部读取特征的数据结构来存储索引
从性能的代价角度出发:处理器的计算代价远比磁盘IO来的小的多=>可以尝试更多计算,从而减少磁盘IO次数=>增加树的分支,减少树的高度=>而又因为磁盘按页进行数据交换=>增加树节点上的索引个数(节点中索引当然也是连续的,这就不解释了)
2. 为什么不是AVL?
最主要的,树深度太大,没有充分利用磁盘读取的局部性,将招致非常糟糕的磁盘IO次数,不适合磁盘IO的特征
平衡二叉树是通过旋转来保持平衡的,而旋转是对整棵树的操作,若部分加载到内存中则无法完成旋转操作
3.为什么是b树?
B-树每次将范围分割为多个区间,区间越多,定位数据越快越精确。那么如果节点为区间范围,每个节点就较大了
多叉的好处非常明显,有效的降低了B-树的高度,为底数很大的 log n
3.1 b- 树

3.2 b+ 树
作为许多数据库默认的索引策略,相比较b-树,针对磁盘IO次数做了更多思考和优化

内节点并不存储 data,所以一般B+树的叶节点和内节点大小不同,而B-树的每个节点大小一般是相同的,为一页(这样一来,可以有效减少磁盘IO)。
由于B+树的叶子节点的数据都是使用链表连接起来的,而且他们在磁盘里是顺序存储的,所以当读到某个值的时候,磁盘预读原理就会提前把这些数据都读进内存,使得范围查询和排序都很快
B+树只有叶子节点存data,非叶子节点都只是索引值(算法书上也叫"关键字"),没有实际的数据,这就时B+树在一次IO里面,能读出的索引值更多。从而减少查询时候需要的IO次数
3.2.1 插入
如上所述,操作的节点数可以等同于磁盘IO次数
考虑叶子节点最大的字节空间,可能出现节点分裂的情况,详见算法书,书里有图,非常简单,这里就不放了,脑补即可
如果父节点允许再插入一个叶子节点,那么将额外多出2此磁盘写
如果父节点已经"装满"了,那么父节点将分裂,这将带来额外的a次磁盘写(a=父节点最大叶子节点数),并将更新这两个父节点及其叶子节点的值
如果父节点的父亲也不能再容许更多的儿子节点,那么树高度+1
3.2.2 删除
同理,删除最小值,兄弟叶子节点则“领养”其叶子结点的值,并更新
如果父节点没有叶子了,则树高度-1
















 756
756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











