







0. 慢慢的做梦…
十五.SpringCloud极简入门-Spring Cloud Stream消息驱动(版本有些过时了)
Spring Cloud Stream 进阶配置——高可用(二)——死信队列
rabbitmq-client中文文档
借助bindingRoutingKey属性配置exchange使用的路由键
spring-cloud-stream 整合rabbitmq 消息分区
rabbitmq 消息补偿方案
Rabbitmq 先告一段落吧,后面看看还有没有机会吧 …
1. 先回顾一波Rabbitmq的模型
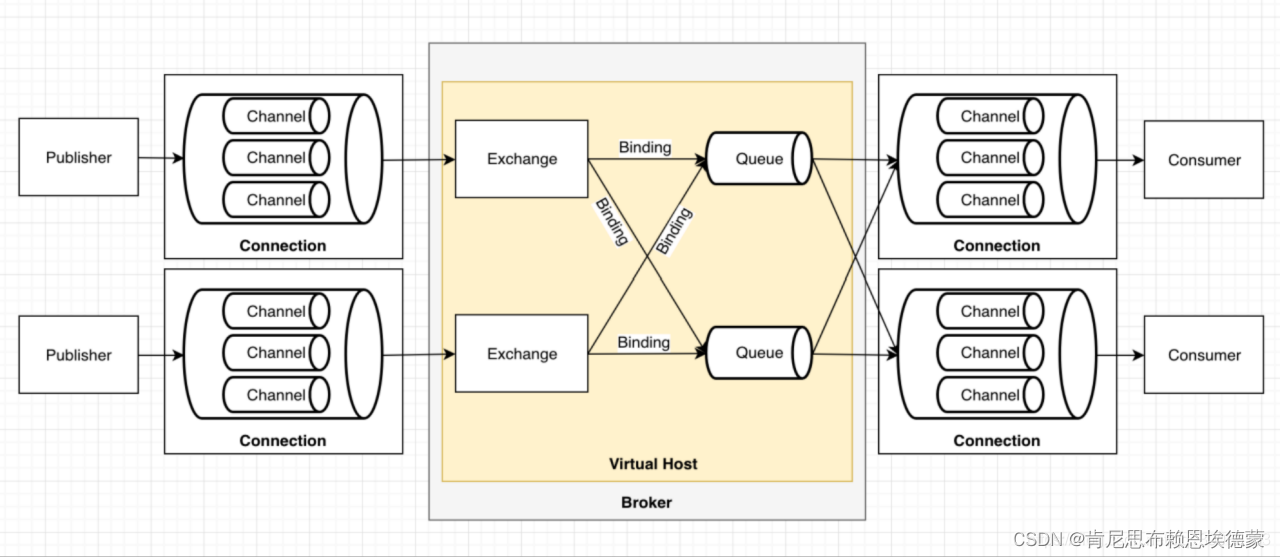
2. spring-cloud-stream 配置走一波
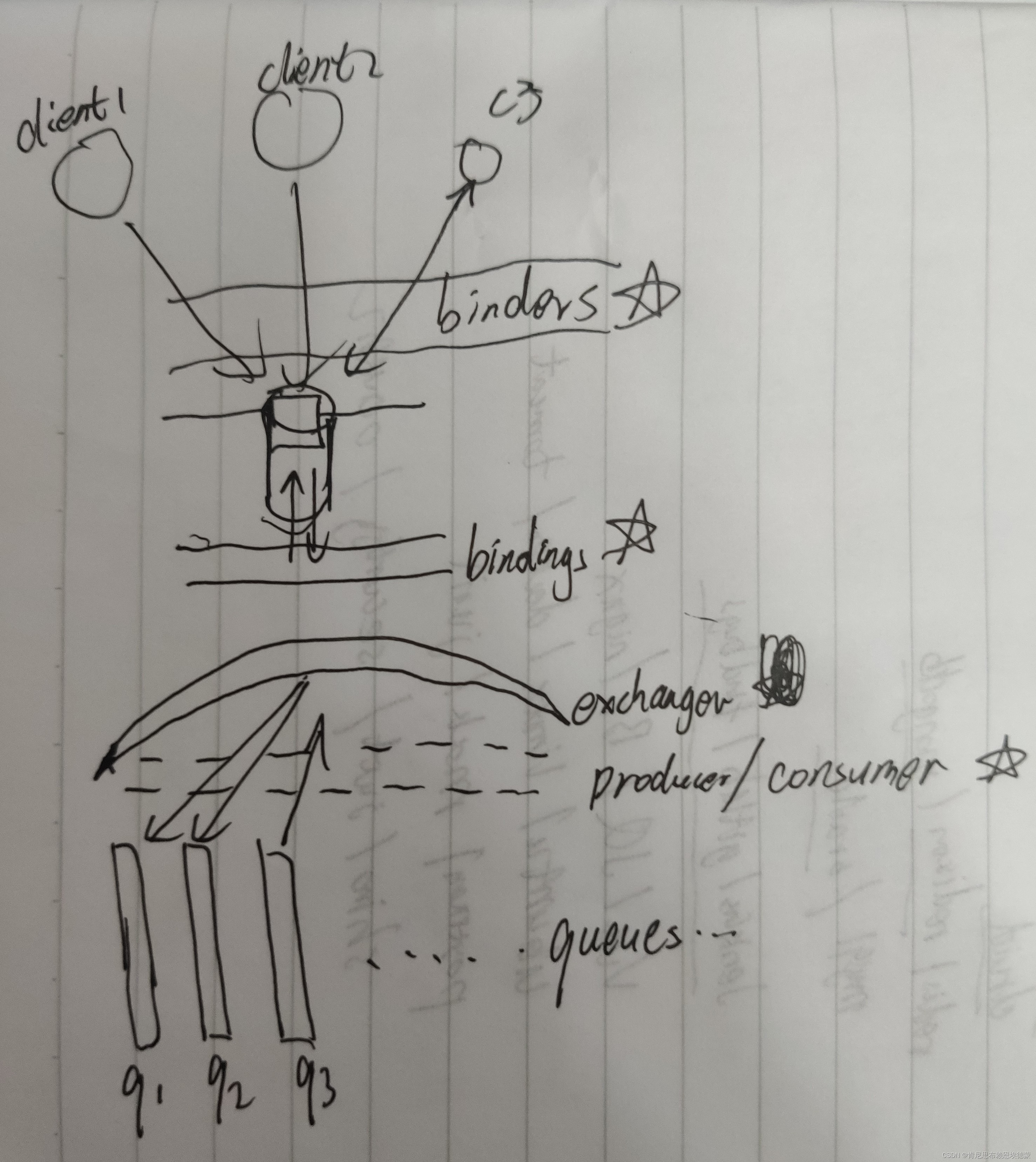
spring-cloud-stream 配置维护的是mq中相互接壤的两个抽象对象之间的关联关系(见图中*)
一般来说,智能的IDE允许配置文件跳转到对应的Properties配置类中,借助这种方式,我们可以确认我们的配置项是否存在(是否写错变量名)
2.1 消费者配置
spring:
cloud:
stream:
binders:
myBinder:
type: rabbit
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
virtual-host: /
bindings:
# 消息输入配置,我们这里是消费者,如果是生成者就用output
# output:
# 我们自定义 Source (output)、Sink(input)
mySource:
# 跟binder建立关系
# 会报红字,虽然不会有影响
binder: myBinder
# content-type: application/json
# #消息目的地 , 会在RabbitMQ创建一个名字叫myStream的Exchange
destination: myExchange
# partitionKeyExpression: headers['partitionKey']
# yml是点进去看——”有没有这个配置项“ 的
producer:
#分区规则表达式配置,从header中获取分区索引
partition-key-expression: headers['partitionKey']
partition-count: 2 # 配置消息分区的数量
# rabbitmq:
# host: localhost
# port: 5672
# username: guest
# password: guest
2.2 生产者
spring:
# rabbitmq:
# host: localhost
# port: 5672
# username: guest
# password: guest
cloud:
stream:
binders:
myBinder:
type: rabbit
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
virtual-host: /
bindings:
# 消息输入配置,我们这里是消费者,如果是生成者就用output
# input:
mySink:
binder: myBinder
# content-type: application/json
# #消息目的地 , 会在RabbitMQ创建一个名字叫myStream的Exchange
destination: myExchange
# #指定组,多个消费者在同一个组,那么一个消息就只会给到一个消费者
group: myGroup
# 开启分区
# partitioned: true
consumer:
partitioned: true
#重试次数,默认3次
max-attempts: 2
# 下面这俩配置是在消息topic分区下使用的
# 消费者实例个数
instance-count: 2
# 消费者实例的下标
instance-index: 0
# 太逆天了...rabbit专项配置需要单独配置(spring-cloud-stream整合的并不是那么美好)
# https://cloud.tencent.com/developer/ask/sof/330702
rabbit:
bindings:
mySink:
consumer:
#开启死信队列
# 当MQ消费失败达到最大重试次数就会把消息加入 死信队列 , 我们可以通过把死信队列中的消息再移动到 正常队列重复消费
# auto-bind-dlq: true
autoBindDlq: true
#死信队列消息存活时间 ,有些数据过时了就没意义了
# dlq-ttl: 50000
# 默认不做限制,即无限。消息在队列中最大的存活时间。当消息滞留超过ttl时,会被当成消费失败消息,即会被转发到死信队列或丢弃.
ttl: 10000
#把失败原因也推送到死信队列
republish-to-dlq: true
#指定队列名称
deadLetterQueueName: myExchange.myGroup-0.dlq
#重新排队拒绝消息的简称失败的消息将重新提交给同一处理程序并连续循环
requeue-rejected: true
# 手动确认(默认自动签收)
acknowledge-mode: manual
3. 调优配置
3.1 吞吐量
3.1.1 消费者数量
最简单的提高消费端吞吐量的方式就是增加消费者数量。
# 初始/最少/空闲时 消费者数量。默认1
spring.cloud.stream.bindings.<channelName>.consumer.concurrency=[Integer]
动态增加消费者:应用启动时创建的消费者数量可能只是暂时的,并不是最终的数量。
3.1.2 弹性的消费者数量
增加消费者数量,但具体增加到多少是很难确定的,因为各种各样的因素都会导致消费者数量冗余或不足,比如在用户访问高峰期,消费者数量肯定需要比较多,而在平时或凌晨,访问量降到低谷,消费者数量肯定就冗余了,甚至,一个队列只在某个定时任务才会用到,那么在平时多消费者基本就只有占用系统资源的作用了。
# 弹性 queue的消费者的最大数量,默认:1
# 当前消费者数量不足以及时消费消息时, 会动态增加消费者数量, 直到到达最大数量, 即该配置的值.
spring.cloud.stream.rabbit.bindings.<channelName>.consumer. maxConcurrency=[Integer]
如果不增加消费者数量的话,而消息发布的吞吐量又居高不下,该怎么办呢?实际上,增加消费者数量,其最终目的就是提升消费端的消费力,那我们可以从别的方式入手,比如增加应用实例数量,其实这也是另一种增加消费者数量的方式,只是在其他机器而已;而如果暂时没有增加机器的预算,那么可以考虑批量消费数据
3.1.3 一次性批量消费
spring-cloud-stream 并不支持 轮询的 批量分发模式(虽然简单,但存在很大的隐患:系统资源(特别是堆内存)被浪费);
另一种被支持的 批量分发模式 —— 公平分发:消费快的,分担多一点,量力而行(消费者每次只从队列获取一定数量的消息,当所有消息消费完了,再接着从队列获取相同数量的消息。
这样一来,消费快的消费者,向队列获取消息的频率就高,反之,频率就低)
# 限制consumer在消费消息时,一次能同时获取的消息数量,默认:1。
spring.cloud.stream.rabbit.bindings.<channelName>.consumer.prefetch=[Integer]
3.2 可用性
3.2.1 重试
失败重试可以解决短暂性的消费失败的情况
# 当消息消费失败时,尝试消费该消息的最大次数(消息消费失败后,发布者会重新投递)。默认3
spring.cloud.stream.bindings.<channelName>.consumer.maxAttempts=[Integer]
# 消息消费失败后重试消费消息的初始化间隔时间。默认1s,即第一次重试消费会在1s后进行
spring.cloud.stream.bindings.<channelName>.consumer.backOffInitialInterval=[Integer]
# 相邻两次重试之间的间隔时间的倍数。默认2,即第二次是第一次间隔时间的2倍,第三次是第二次的2倍
spring.cloud.stream.bindings.<channelName>.consumer.backOffMultiplier=[Integer]
# 下一次尝试重试的最大时间间隔,默认为10000ms,即10s。
spring.cloud.stream.bindings.<channelName>.consumer.backOffMaxInterval=[Integer]
事实上,消息确实被丢弃了,但是这样不好吧,这样会存在丢失部分消息的隐患,于是不得不引入另一个概念——死信队列
3.2.2 死信队列
消息被队列丢弃后,会变成死信,如果队列不声明死信队列,那么这些消息将被永久丢弃
spring:
cloud:
stream:
rabbit:
bindings:
packetUplinkInput:
consumer:
# 是否自动声明死信队列(DLQ)并将其绑定到死信交换机(DLX)。默认是false。
autoBindDlq: true
' # 默认prefix + destination + group + .dlq。DLQ的名称。
deadLetterQueueName: 'packetUplinkDlxTopic.scas-data-collection.dlx.dlq
# 默认prefix + DLX。DLX的名称
deadLetterExchange: 'DLX'
# 默认destination + group
deadLetterRoutingKey: 'packetUplinkDlxTopic.scas-data-collection.dlx'
# 队列所有 customer 下线, 且在过期时间段内 queue 没有被重新声明, 多久之后队列会被销毁, 注意, 不管队列内有没有消息. 默认不设置.
dlqExpires: 30000
# 是否声明为惰性队列(Lazy Queue).默认false
dlqLazy: false
# 队列中消息数量的最大限制. 默认不限制
dlqMaxLength: 100000
# 队列所有消息总字节的最大限制. 默认不限制
dlqMaxLengthBytes: 100000000
# 队列的消息可以设置的最大优先级. 默认不设置
dlqMaxPriority: 255
# 队列的消息的过期时间. 默认不限制
dlqTtl: 1000000
# 默认false。当为true时,死信队列接收到的消息的headers会更加丰富,多了异常信息和堆栈跟踪。
republishToDlq: true
# 默认DeliveryMode.PERSISTENT(持久化)。当republishToDlq为true时,转发的消息的delivery mode
republishDeliveryMode: DeliveryMode.PERSISTENT
消费过程中肯定也会产生死信,那么死信队列产生的死信,有该何去何从?所以有了死信队列的死信队列
4. spring-cloud-stream的partition-key & Rabbitmq
我当时的脑回路:
- partition 不是 分区 的意思吗?
- rabbitmq所实现的 amqp协议 并没有提及对 分区 的支持吧?
- 为什么spring-cloud-stream可以支撑 rabbitmq 的 分区?
4.1 消息分组 & 消息分区
- 消息分组->针对消息的 消费 者而言的,即 消费者组
- 消息分区->针对broker,即 mq server而言的,每个topic可以有多个分区->这也使得kafka获得了很强的水平扩展能力+减小每个broker的IO压力(也就是常说的吞吐量,即消息 接收 的能力)
总的来说,这俩设计都是为了均衡消息的负载,差别在发生的位置(或者说阶段)不一样
4.2 spring-cloud-stream 为何需要为rabbitmq整合 分区
场景:多条同一类型的数据发送过来,为保证同一类型消息始终由同一个消费者实例消费。
可以设想到只是 控制分组,是不足以满足上述场景的,因为消息可能写入broker时候,就已经不在一个分区下面了















 6689
6689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









