






目录
0、准备一台新服务器
本篇以虚拟机为例,安装好CentOS7系统

1、修改主机名
vim /etc/hostname 2、配置静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33

配置之后进行重启
3、配置xshell登录

登录之后检查hostname和ip、网关是否正常

4、关闭并禁用防火墙
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld5、分发hadoop和jdk文件
scp -r module/* mingyu@hadoop105:/opt/module/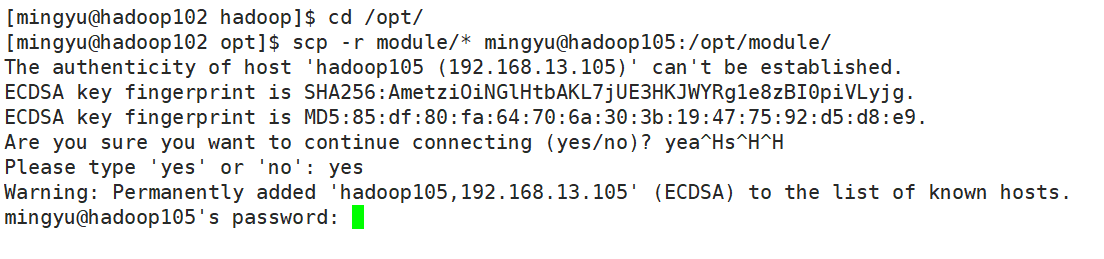
6、分发环境变量文件
sudo scp /etc/profile.d/my_env.sh root@hadoop105:/etc/profile.d/
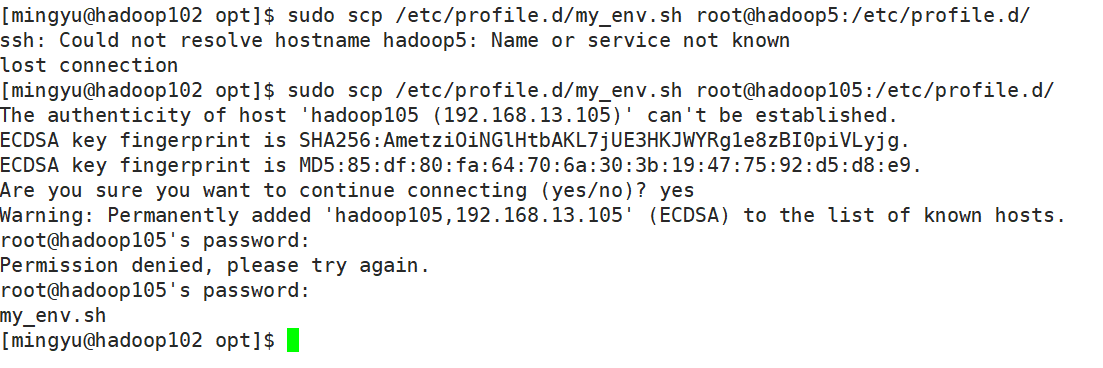
7、source 环境变量
让环境变量生效
source /etc/profile.d/my_env.sh
8、配置ssh
hadoop102里面有namenode
hadoop103里面有ResourceManager
使得通信流畅
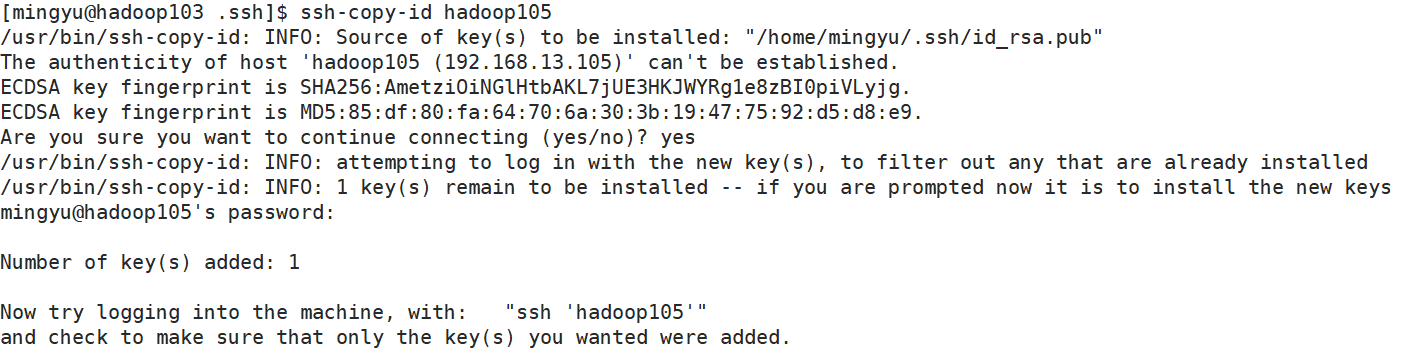
102进入home目录,再进入.ssh目录
cd
cd .ssh/
ssh-copy-id hadoop105输入yes和105的密码即可
9、删除105节点的data、logs文件夹
因为过去生成的clustr id不再适用
rm -rf data/ logs/

10、单节点启动并关联到集群
hdfs --daemon start datanode
yarn --daemon start nodemanager
①在HDFS配置的白名单中放行Hadoop105
vim etc/hadoop/whitelist②将105加入到workers名单
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim workers
xsync workers 
并分发workers
③分发白名单,并在105上面也将105加入白名单
在102中刷新节点
hdfs dfsadmin -refreshNodes

此时在hdfs中就存在hadoop105了
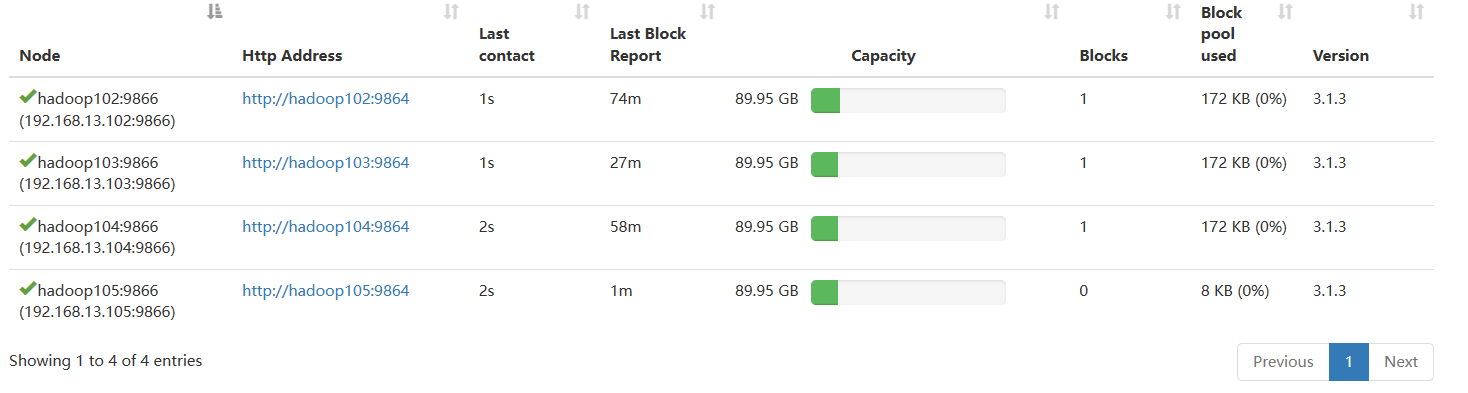
11、验证新节点是否有效
从hadoop105节点上传文件到HDFS系统
hadoop fs -put README.txt / 可以看到上传成功
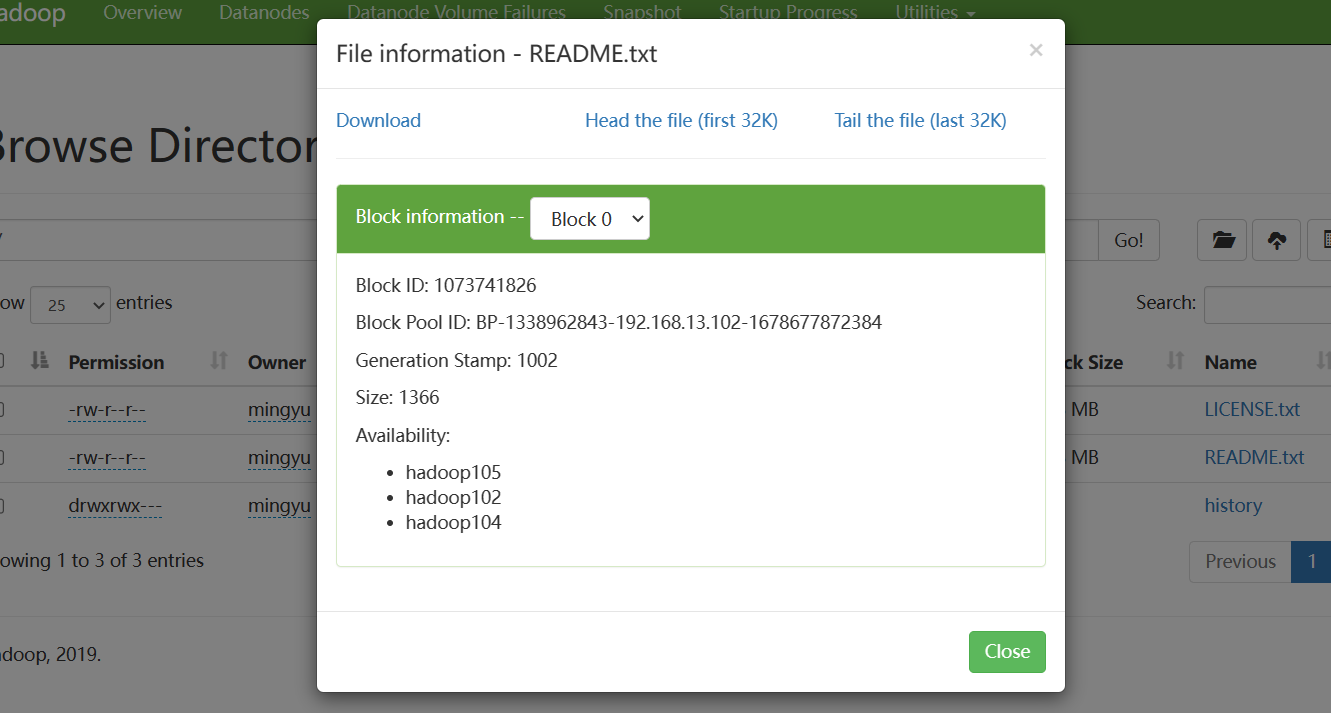
由于优先上传本地节点,在105中必有文件块,当105节点上传较多,导致文件不均衡,下一篇进行解决















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









