






目录
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的master-slave 模式。
集群规划:

1 解压缩文件
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
2 修改配置文件
- 进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
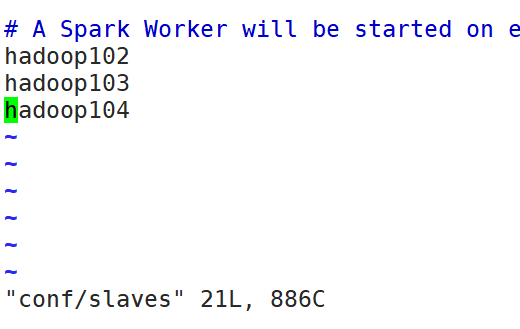
mv slaves.template slaves - 修改slaves文件
- 修改 spark-env.sh.template 文件名为 spark-env.sh
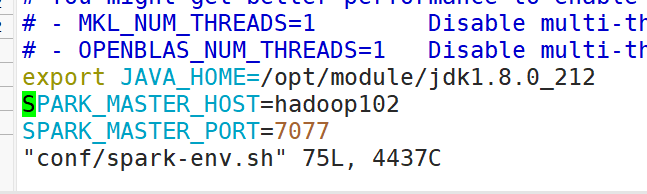
mv spark-env.sh.template spark-env.sh- 修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
- 分发standalone文件夹
xsync spark-standalone3 启动集群
sbin/start-all.sh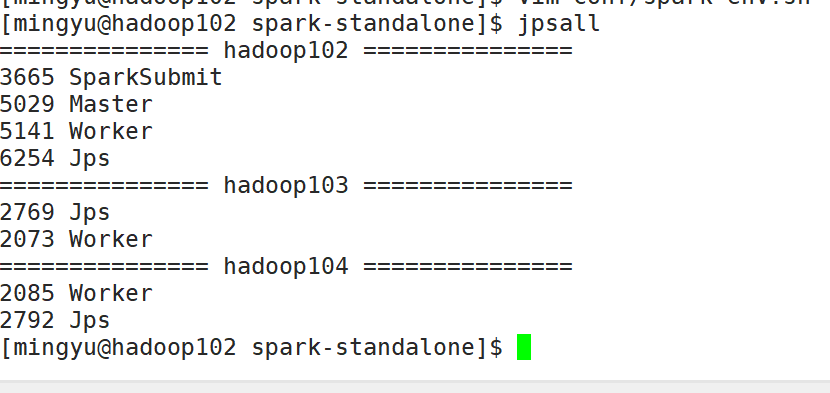
运行一下Pi程序
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
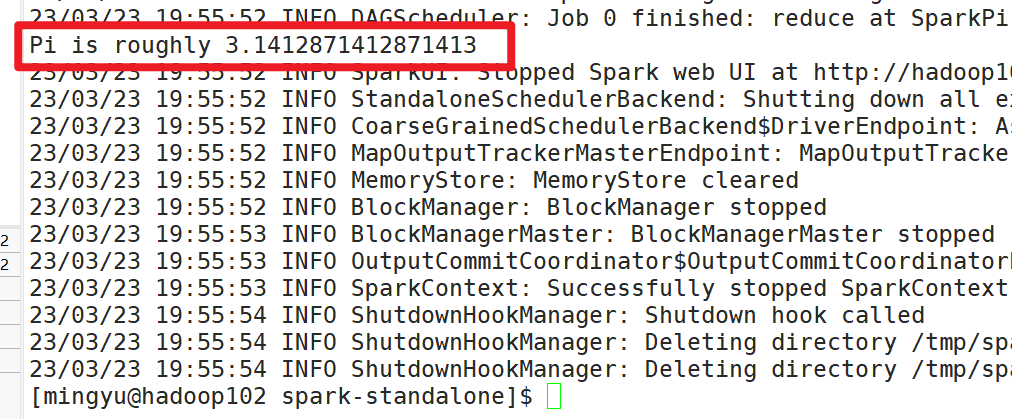
配置成功















 1867
1867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









