






这里写目录标题
一、目标检测,分割数据集
1.COCO 数据集
COCO是一个可用于object detection, segmentation and caption的大型数据集。有以下特点:
- 目标分割
- 上下文关系识别
- 超像素分割
- 330K图像(> 200K已标记)
- 150万个目标
- 80个分类
- 91种目标
- 包含250,000个人(已标记)
- 大小:约25 GB(压缩包)
- 数量: 330K张图像,25万个人(已标记)
COCO2014
百度云链接
链接:https://pan.baidu.com/s/1wLFpT7DFNBXGeJugEYwxxg
提取码:s90c
官网地址
http://images.cocodataset.org/zips/train2014.zip
http://images.cocodataset.org/annotations/annotations_trainval2014.zip
http://images.cocodataset.org/zips/val2014.zip
http://images.cocodataset.org/annotations/image_info_val2014.zip
http://images.cocodataset.org/zips/test2014.zip
http://images.cocodataset.org/annotations/image_info_test2014.zip
COCO2017
百度云链接
链接:https://pan.baidu.com/s/1jY1Zno5yRNz_Kt-AIFad_w
提取码:v5rm
官网地址
http://images.cocodataset.org/zips/train2017.zip
http://images.cocodataset.org/annotations/annotations_trainval2017.zip
http://images.cocodataset.org/zips/val2017.zip
http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
http://images.cocodataset.org/zips/test2017.zip
http://images.cocodataset.org/annotations/image_info_test2017.zip
这个是下载地址。不要直接点击。linux可以用wget -c http下载,不需要翻,比如
wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip
推荐多线程下载工具aria2
apt install -y aria2
aria2c -s 5 链接
例如
aria2c -s 5 http://images.cocodataset.org/zips/train2014.zip
2.PASCAL VOC数据集
官网链接:http://host.robots.ox.ac.uk/pascal/VOC/
该比赛在2005~2012共举办8年,使用数据集为VOC(Visual Object Classes,视觉对象类别),每一年数据集都会更新,数据集以VOC加年份命名,如VOC 2007、VOC 2012。所有数据集均可在官网下载。
2005年,数据集为4类;2006年为10类;从2007年起,固定为20类。
这20个类别为:
Person:person
Animal:bird, cat, cow, dog, horse, sheep
Vehicle:aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor:bottle, chair, dining table, potted plant, sofa, tv/monitor
翻译成中文就是:
1.人: 人
2.动物: 鸟,猫,牛,狗,马,羊
3.交通工具: 飞机,自行车,船,公共汽车,汽车,摩托车,火车
4.室内: 瓶子,椅子,餐桌,盆栽,沙发,电视/显示器
voc2007数据集:
百度云链接
链接:https://pan.baidu.com/s/1Q9j2yeTeyNcOqXulhCXhhA
提取码:ne7k
官网链接
1.先下载:
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
2.再解压:
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
tar -xvf VOCdevkit_08-Jun-2007.tar
最终的结构:
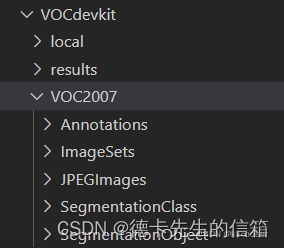
voc 2012数据集:
百度云链接
链接:https://pan.baidu.com/s/1dJQ63wUtBKf0Fmo2Qo36Pw
提取码:0sc6
官网链接
1.同样的,先下载:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget http://pjreddie.com/media/files/VOC2012test.tar
2.再解压:
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOC2012test.tar
最终的结构:
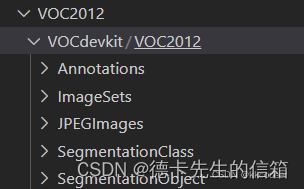
注:
Annotations下面放的是图片的标注文件
ImageSets下面是txt文件,对目标检测来说只会用到Main文件夹下的内容
JPEGImages下面就是图片啦
二、自动驾驶数据集
1. BDD100K 数据集
目前,自动驾驶的公开数据集主要由视频和图片组成,近两年也增加了许多雷达数据。今天将介绍的数据集为加州大学伯克利分校发布的 BDD100K 数据集,该数据集为迄今规模最大、最多样的自动驾驶数据集之一。
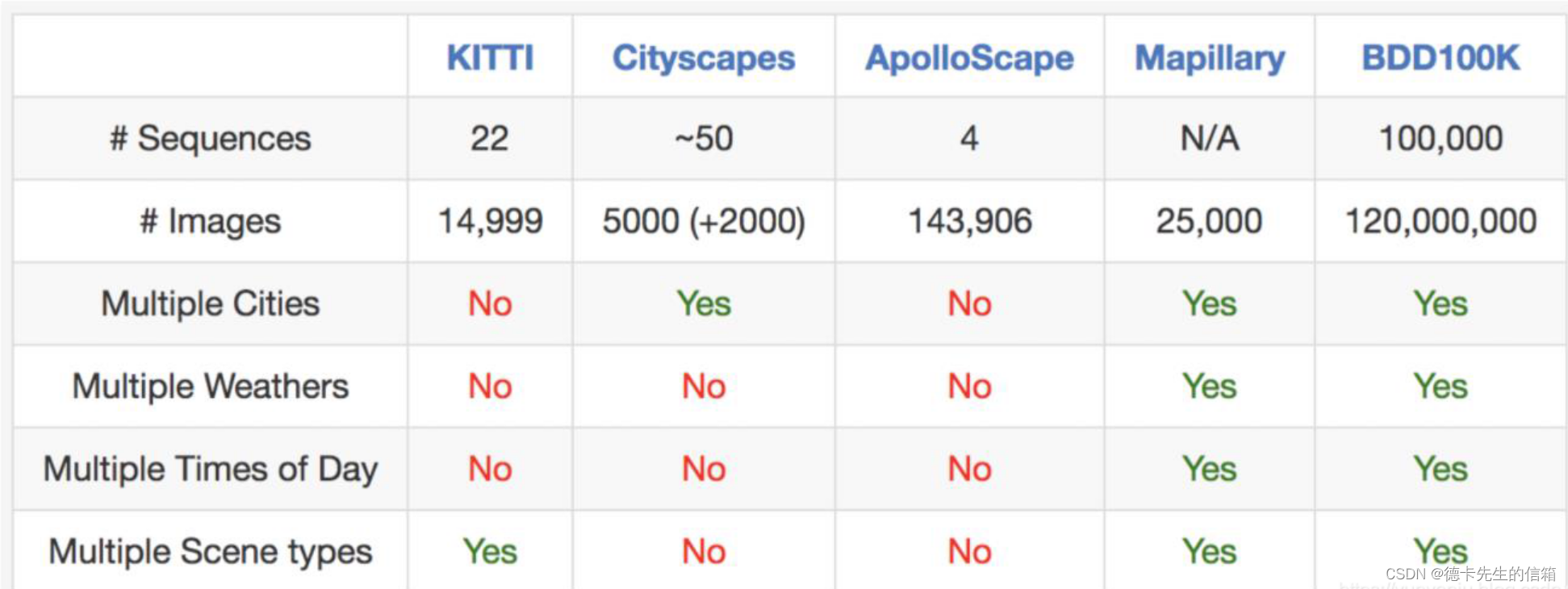
BDD100K 数据集,是加州大学伯克利分校 AI 实验室(BAIR)于 2018 年发布的,迄今为止最大规模、内容最具多样性的公开驾驶数据集之一。其包含的 10 万个高清视频序列,时长超过 1100 小时。其中,每个视频大约 40 秒长、720p、30 fps,还附有手机记录的 GPS/IMU 信息和时间戳,以显示大概的驾驶轨迹。BAIR 还对每个视频的第 10 秒对关键帧进行采样,得到 10 万张图片(图片尺寸:1280*720 ),并进行标注。这些图片还被标记了:图像标记、道路对象边界框、可驾驶区域、车道标记线和全帧实例分割。这些注释有助于理解不同场景中数据和对象统计的多样性。数据集中的视频是从美国各地收集的,涵盖不同时间、不同天气条件(包括晴天、阴天和雨天,以及白天和晚上的不同时间)和驾驶场景。收集数据集的地理位置分布在纽约、伯克利、旧金山等地。数据集中,道路目标检测是为公共汽车、交通灯、交通标志、人、自行车、卡车、摩托车、汽车、火车和乘车人等 100000 张图片上标注 2D 边界框;实例分割被用于探索具有像素级和丰富实例级注释,相关图像超过 10000 张;引擎区域是从 10 万张图片中学习复杂的可驾驶决策;车道标记是在 10 万张行车指南图片上的多种车道标注。车道标记类图片中,标注了实线、虚线、双线、单线等。该数据集由相关论文有《BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling》,该项目由伯克利 DeepDrive 产业联盟组织和赞助,该联盟研究计算机视觉和机器学习在汽车应用上的最新技术。
2.Nuscenes
数据集的详细结构参数介绍Nuscenes 数据集浅析



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











