







 本文详细介绍Tesseract-OCR的配置与使用,涵盖PDF文字识别、图形验证码提取等案例,并探讨文字图片处理技巧。
本文详细介绍Tesseract-OCR的配置与使用,涵盖PDF文字识别、图形验证码提取等案例,并探讨文字图片处理技巧。
阅读提示
本文将提到Tesseract-OCR的简介、配置使用并附带超实用案例,包括pdf文字识别、图形验证码提取等。
目录
在尝试破解12306验证码的时候,提前了解了一下应对各种验证码的解决方案,这里主要是学习到了面对文字图片验证码,例如亚马逊、豆瓣等平台的登录时会遇到的情况,效果还不错。
一、工具介绍
Tesseract-OCR 是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
GitHub 地址:https://github.com/tesseract-…
安装包官方下载地址:https://digi.bib.uni-mannheim…
安装包百度云盘下载地址:https://pan.baidu.com/s/1AOsJ…
二、配置环境变量
2.1 进入环境变量配置界面
右键点击此电脑–属性–高级系统设置–环境变量–系统变量–Path
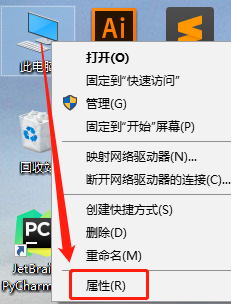
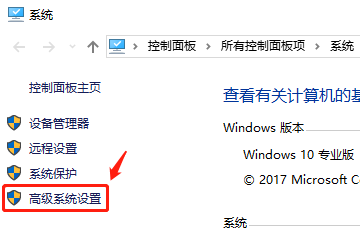
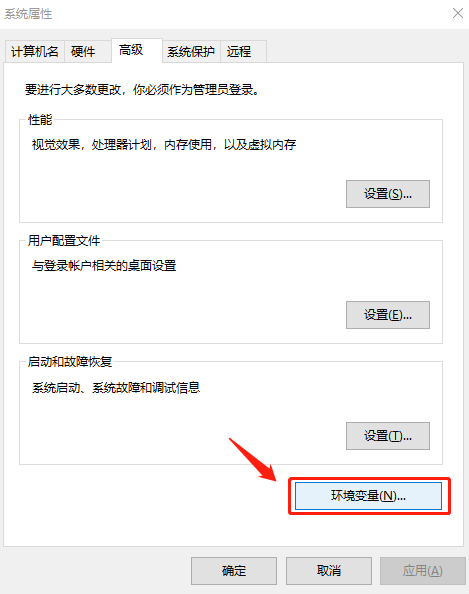
2.2 添加系统变量
找到系统变量的 Path ,将 Tesseract-OCR 的安装目录添加进去:
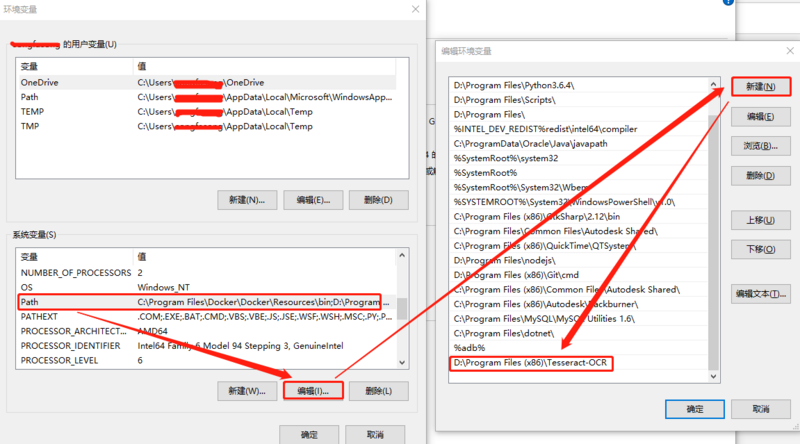
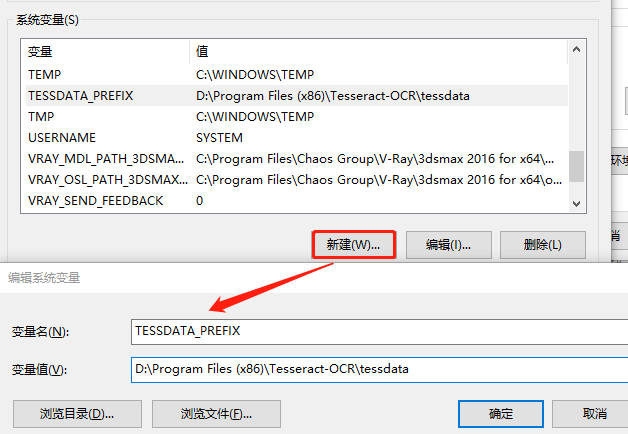
2.3 添加 tessdata 系统变量
如下图新建系统变量 : TESSDATA_PREFIX
变量值为 tessdata 文件夹的路径(在Tesseract-OCR的安装目录下):
三、使用 Tesseract-OCR
3.1 进入cmd 输入下面的命令查看版本,正常运行则安装成功:
tesseract --version

3.2 使用下面命令识别图片

tesseract 图片路径 输出文件

查看输出的 result.txt文件:
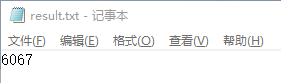
结果正确!
四、处理给规范的文字
处理的大多数文字最好都是比较干净、格式规范的。格式规范的文字通常可以满足一些需求,通常格式规范的文字具有以下特点:
- 使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体)
- 即使被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
- 排列整齐,没有歪歪斜斜的字
- 没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
文字的一些格式问题在图片预处理时可以进行解决。例如,可以把图片转换成灰度图,调整亮度和对比度,还可以根据需要进行裁剪和旋转(详情需要了解图像与信号处理)等。
4.1 格式规范文字的理想示例
识别结果很准确,不过符号^和*分别被表示成了双引号和单引号。大体上可以让你很舒服地阅读。
4.2 通过Python代码实现
import pytesseract
from PIL import Image
image = Image.open('test.jpg')
text = pytesseract.image_to_string(image)
print text
运行结果:
This is some text, written in Arial, that will be read by
Tesseract. Here are some symbols: !@#$%"&*()
4.3 对图片进行阈值过滤和降噪处理(了解即可)
随着背景色从左到右不断加深,文字变得越来越难以识别,Tesseract 识别出的 每一行的最后几个字符都是错的。
遇到这类问题,可以先用 Python 脚本对图片进行清理。利用 PIL 库,我们可以创建一个阈值过滤器来去掉渐变的背景色,只把文字留下来,从而让图片更加清晰,便于 Tesseract 读取:
from PIL import Image
import subprocess
def  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









