






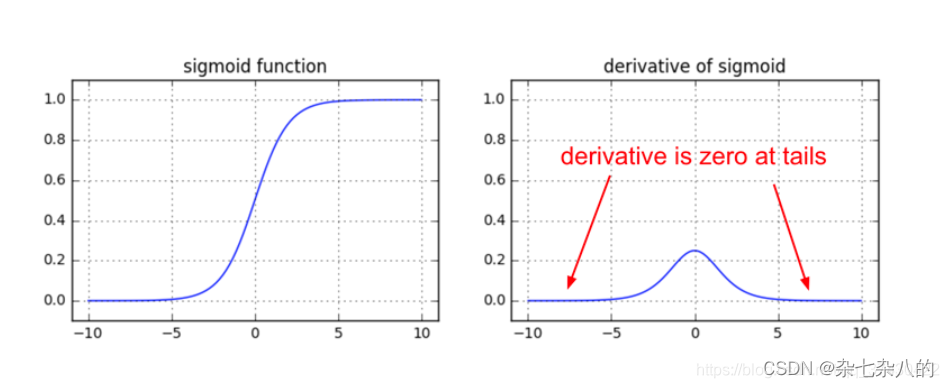
全连接批量归一化
- 目的: 一般的激活函数在0附近的分布是梯度良好区域,把数据的范围压缩在梯度良好区域,在反向传播中更有利于收敛
- 方式: 每个节点上增加 γ \gamma γ, β \beta β
- 关键: 在全连接层中,可以认为每个 x i x_i xi独立分布,所以归一化是作用在 x i x_i xi上的

例子:
sigmoid函数
y
=
1
1
+
e
x
y=\frac{1}{1 + e^x}
y=1+ex1
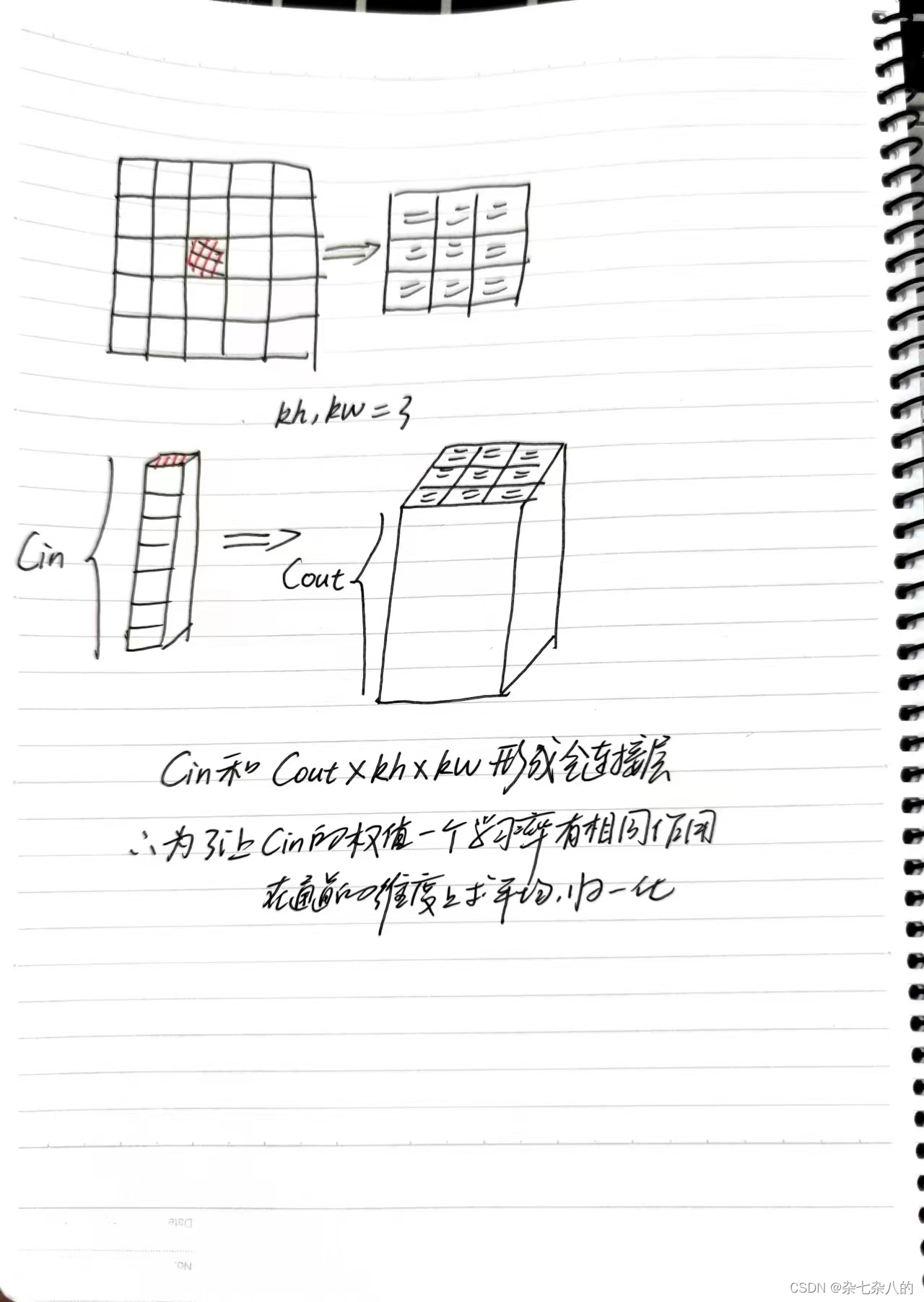
卷积批量归一化
- 卷积实际上是一种共用权值的批量归一化层,输入一个特征图通道上的所有值和输出的一块区域事实上形成了全连接
- 输入: 1 × 1 × C i n 1 \times 1 \times C_{in} 1×1×Cin
- 输出:
h
k
×
w
k
×
C
o
u
t
h_k \times w_k \times C_{out}
hk×wk×Cout
参数总量: C i n × h k × w k × C o u t C_{in} \times h_k \times w_k \times C_{out} Cin×hk×wk×Cout - 关键: 一个channel上的KaTeX parse error: Double subscript at position 7: C_{in}_̲i说实话不是独立分布的,如rgb值,看任合一个通道的image都能看出那是一只猫,独立分布的最小的个体是
C
i
n
C_in
Cin,所以求归一化是在
C
i
n
C_in
Cin上做的
torch张量维度重构
参考:
一文读懂torch的view机制
torch的view和reshape底层机制
import torch
arr = torch.rand(2, 3, 4, 5)
arr_1d = arr.flatten()
for d1 in range(2):
for d2 in range(3):
for d3 in range(4):
for d4 in range(5):
index = d1 * 3 * 4 * 5 + d2 * 4 * 5 + d3 * 5 + d4 * 1
print(arr_1d[index])
import torch
arr = torch.rand(2, 3, 4, 5)
arr_1d = arr.flatten()
s4 = 1
s3 = 5 * 1
s2 = 4 * 5 * 1
s1 = 3 * 4 * 5 * 1
for d1 in range(2):
for d2 in range(3):
for d3 in range(4):
for d4 in range(5):
index = d1 * s1 + d2 * s2 + d3 * s3 + d4 * s4
print(arr_1d[index])
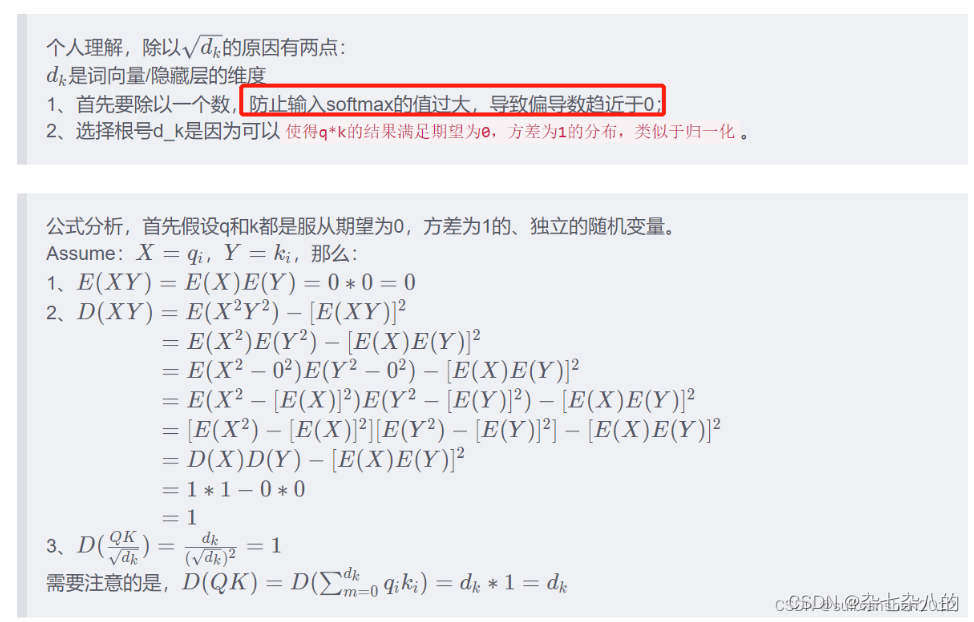
self-attention

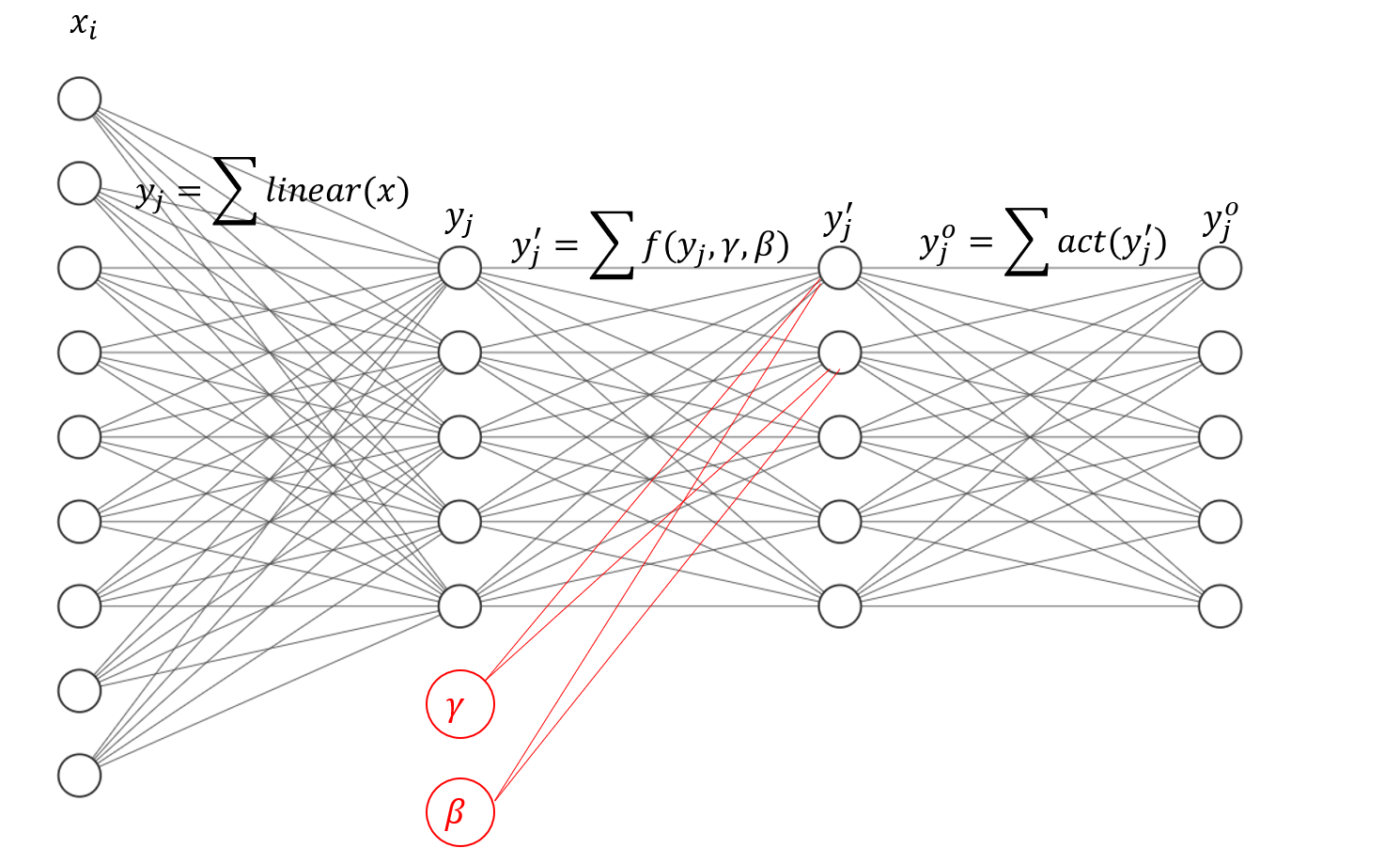
错误理解,对比加深理解
- 目的是:只有一个学习率, 通过归一化,让所有的 x i x_i xi具有一样的分布,则对每个参数 w i w_i wi梯度的作用是相当的
- 实现是:实际上是在全连接中增加了两个节点
γ
\gamma
γ,
β
\beta
β














 4162
4162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









