








新增参考:https://www.jianshu.com/p/39fa4ac3a236
celery使用
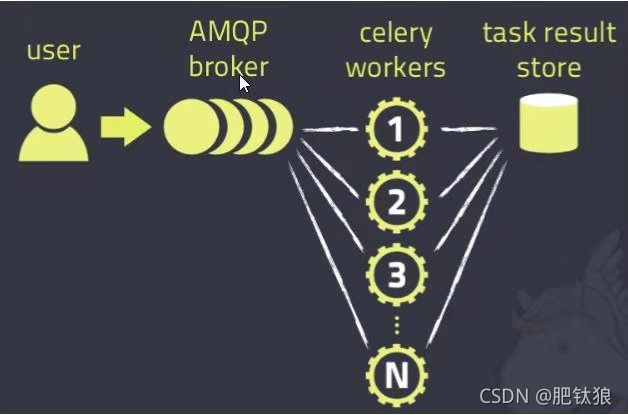
Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度。
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件:Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis等等。
任务执行单元:Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储:Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, redis等。
Celery多用来执行异步任务,将耗时的操作交由Celery去异步执行,比如发送邮件、短信、消息推送、音视频处理等。还可以执行定时任务,定时执行某件事情,比如Redis中的数据每天凌晨两点保存至mysql数据库,实现Redis的持久化。
执行任务过程

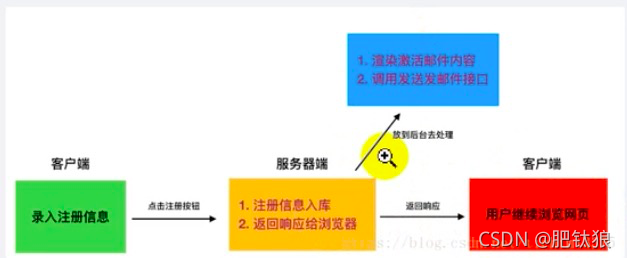
先发起异步任务或者定时任务 ——> 消息中间件开始排队 ——> celery worker开始获取任务开始处理 ——> 最终将处理结果储存到Backend中
Django celery配置
安装
参考版本组合
pip install celery==5.0.5
pip install redis==3.5.3
pip install django-celery-beat==2.2.0
pip install django-celery-results==2.0.1
安装方式一、
celery有两种一种是celery一种是django-celery。使用django-celery,配置中注意版本。
Python版本一定要在3.7以下,这里使用的是3.6.0是正常的
1、下载celery
pip install celery
2、下载redis,注意版本不要太高(这里使用2.8.17)
brew install redis
结果:
Ahmeds-iMac:~ x-xxx.com$ brew -v
Homebrew 1.2.2
Homebrew/homebrew-core (git revision e82a; last commit 2017-06-05)
Ahmeds-iMac:~ x-xxx.com$ brew install redis
Updating Homebrew...
==> Auto-updated Homebrew!
Updated 2 taps (homebrew/core, josegonzalez/php).
==> Updated Formulae
aws-sdk-cpp gphoto2 sdl_mixer
awscli heroku sdl_sound
bazel josegonzalez/php/wp-cli servus
citus knot svgcleaner
conan knot-resolver termius
docker-machine libgphoto2 vapoursynth
docker-machine-completion makepkg vim
ffmpeg mercurial wpcli-completion
freetds msgpack yara
==> Downloading https://homebrew.bintray.com/bottles/redis-3.2.9.sierra.bottle.t
######################################################################## 100.0%
==> Pouring redis-3.2.9.sierra.bottle.tar.gz
==> Using the sandbox
==> Caveats
To have launchd start redis now and restart at login:
brew services start redis
Or, if you don't want/need a background service you can just run:
redis-server /usr/local/etc/redis.conf
==> Summary
🍺 /usr/local/Cellar/redis/3.2.9: 13 files, 1.7MB
Ahmeds-iMac:~ x-xxxx.com$ redis-server
4297:C 07 Jun 17:44:26.735 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
4297:M 07 Jun 17:44:26.736 * Increased maximum number of open files to 10032 (it was originally set to 7168).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 3.2.9 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 4297
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
4297:M 07 Jun 17:44:26.737 # Server started, Redis version 3.2.9
4297:M 07 Jun 17:44:26.737 * The server is now ready to accept connections on port 6379
常用命令:
redis-server
//Redis 默认端口是6379,你也可以换个端口号启动,
redis-server --port 6380
//使用了肯定需要停止,停止怎么弄呢?
//停止
//执行命令
redis-cli shutdown
3、下载celery-with-redis
作用:关联celery和redis,使得redis存储celery中的消息队列(broke)和处理结果(backend)
安装方式二、
安装python 3.6.1 (如果python 3.6.0 会出现ImportError: cannot import name 'AsyncGenerator’报错 :原因是prompt_toolkit的版本与Python 3.6不匹配。解决办法是降低版本:pip install --upgrade prompt-toolkit==2.0.1)
安装Redis 6.0.10 这里使用的最新的,没有出现问题,安全起见使用低点的最好。brew install redis
安装django-celery==3.2.2( 安装django-celery同时也会安装celery)
安装python-redis,pip install redis==3.2.0 (python-redis用于django-celery和redis关联作用。注意这里下载的是redis实际是python-redis)**
项目中配置
1、settings.py中配置
# celery配置
BROKER_URL = 'redis://30.203.160.80:6379/0' # 关联redis,存放任务队列
# redis://:password@hostname:port/db_number 如果有密码
# 配置:配置用户存储结果(backend)的库,0代表是redis中的库,redis默认有16个库
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/1'
# 连接超时
BROKER_TRANSPORT_OPTIONS = {'visibility_timeout': 3600}
# 消息格式
CELERY_ACCEPT_CONNECT = ['application/json']
# 任务的结果的序列化格式
CELERY_TASK_SERIALIZER = 'json'
# 结果的格式以json序列化
CELERY_RESULT_SERIALIZER = 'json'
# celery的时区
CELERY_TIMEZONE = 'Asia/Shanghai'
# celery worker 每次去redis取任务的数量
CELERYD_PREFETCH_MULTIPLIER = 4
# 每个worker最多执行13个任务,避免内存泄漏
CELERYD_MAX_TASKS_PER_CHILD = 13
# 定时任务调度器
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
2、在项目目录下新建celery.py文件(作用:初始化celery配置,使得celer在对应app中可以调用)
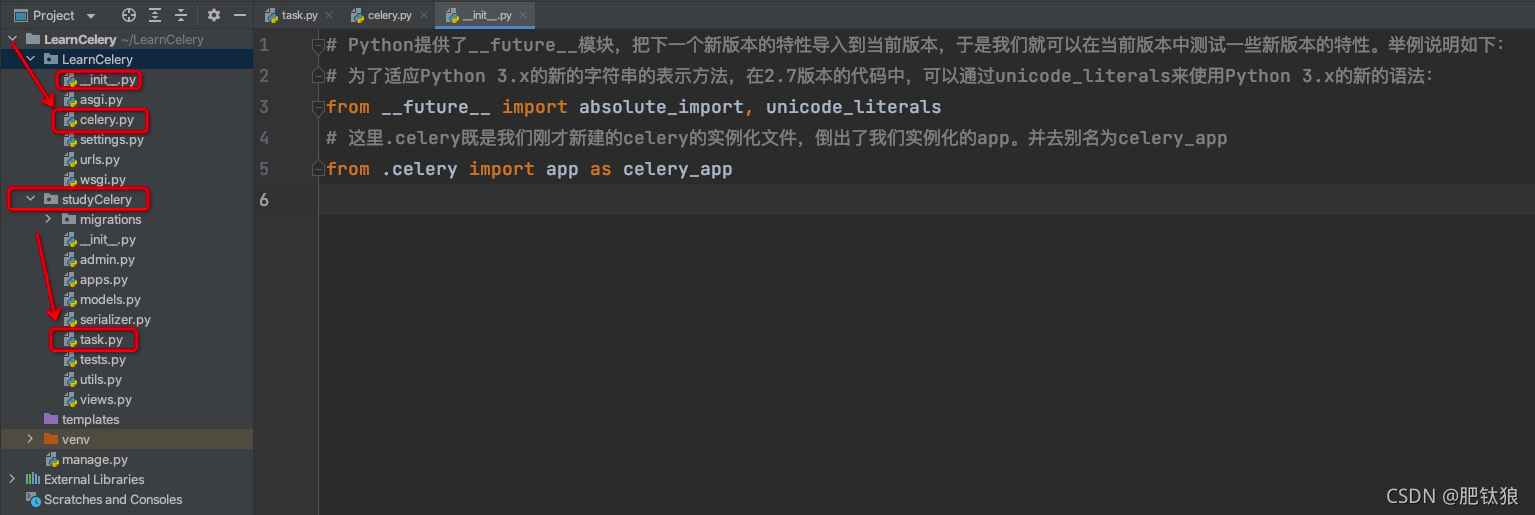
celery.py文件
import os
from celery import Celery
project_name = os.path.split(os.path.abspath('.'))[-1] # 获取项目名,本项目获取的就是LearnCelery
project_settings = '%s.settings' % project_name # 获取该项目的settings文件,这里既是LearnCelery.settings
# 设置django环境
os.environ.setdefault('DJANGO_SETTINGS_MODULE', project_settings)
# 实例化celery
app = Celery(project_name)
# 使用django的配置文件,进行配置
app.config_from_object('django.conf:settings')
3、在项目的__init__.py文件中进行celery配置的初始化
# Python提供了__future__模块,把下一个新版本的特性导入到当前版本,于是我们就可以在当前版本中测试一些新版本的特性。举例说明如下:
# 为了适应Python 3.x的新的字符串的表示方法,在2.7版本的代码中,可以通过unicode_literals来使用Python 3.x的新的语法:
from __future__ import absolute_import, unicode_literals # 我这里理解为unicode_literals防止.celery文件中的编码问题
# 这里.celery既是我们刚才新建的celery的实例化文件,倒出了我们实例化的app。并去别名为celery_app
from .celery import app as celery_app
使用
1、新建任务
在需要使用一步的app中新建文件task.py,并且编辑对应要执行的任务。
import time
from celery import shared_task
@shared_task
def celery_test():
time.sleep(3)
print("这是celery定时器测试!!!")
2、在对应要使用的view中加入该任务
from django.shortcuts import HttpResponse
from taskPlan.tasks import celery_test
def login(request):
celery_test.delay()
print('hello celery')
return HttpResponse("celery")
启动
启动异步:worker
celery -A 项目名 worker -l info
存储任务结果
1、存储任务结果使用django_celery_results
pip install django-celery-results
2、settings.py中增加新的app
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'studyCelery.apps.StudyceleryConfig',
'django_celery_results',
]
3、settings.py中增加配置celery
# celery配置
BROKER_URL = 'redis://30.203.160.80:6379/0' # 关联redis,存放任务队列
# redis://:password@hostname:port/db_number 如果有密码
# 配置:配置用户存储结果(backend)的库,0代表是redis中的库,redis默认有16个库
# CELERY_RESULT_BACKEND = 'redis://30.203.160.80:6379/0'
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/1'
# 连接超时
BROKER_TRANSPORT_OPTIONS = {'visibility_timeout': 3600}
# 消息格式
CELERY_ACCEPT_CONNECT = ['application/json']
# 任务的结果的序列化格式
CELERY_TASK_SERIALIZER = 'json'
# 结果的格式以json序列化
CELERY_RESULT_SERIALIZER = 'json'
# celery的时区
CELERY_TIMEZONE = 'Asia/Shanghai'
# celery worker 每次去redis取任务的数量
CELERYD_PREFETCH_MULTIPLIER = 4
# 每个worker最多执行13个任务,避免内存泄漏
CELERYD_MAX_TASKS_PER_CHILD = 13
# 使用项目数据库存储任务执行结果
CELERY_RESULT_BACKEND = 'django-db'
4、数据迁移
python manage.py migrate
5、查看新增表,查看存储结果

定时任务 django_celery_beat
1、如果我们想某日某时执行某个任务,或者每隔一段时间执行某个任务,也可以使用celery来完成.django_celery_beat
pip install django_celery_beat
2、settings.py中增加新的app
'django_celery_beat',
3、settings.py中增加配置celery
# 定时任务调度器
CELERYBEAT_SCHEDULER = 'django_celery_beat.schedulers.DatabaseScheduler'
4、数据迁移
python manage.py migrate
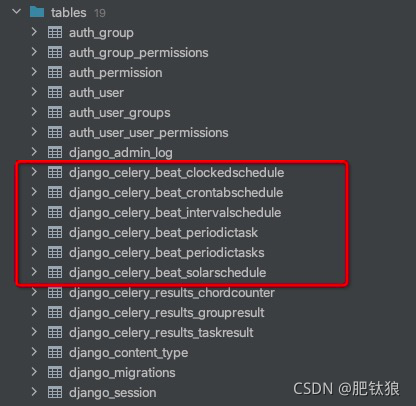
admin中查看生成的对应的数据库
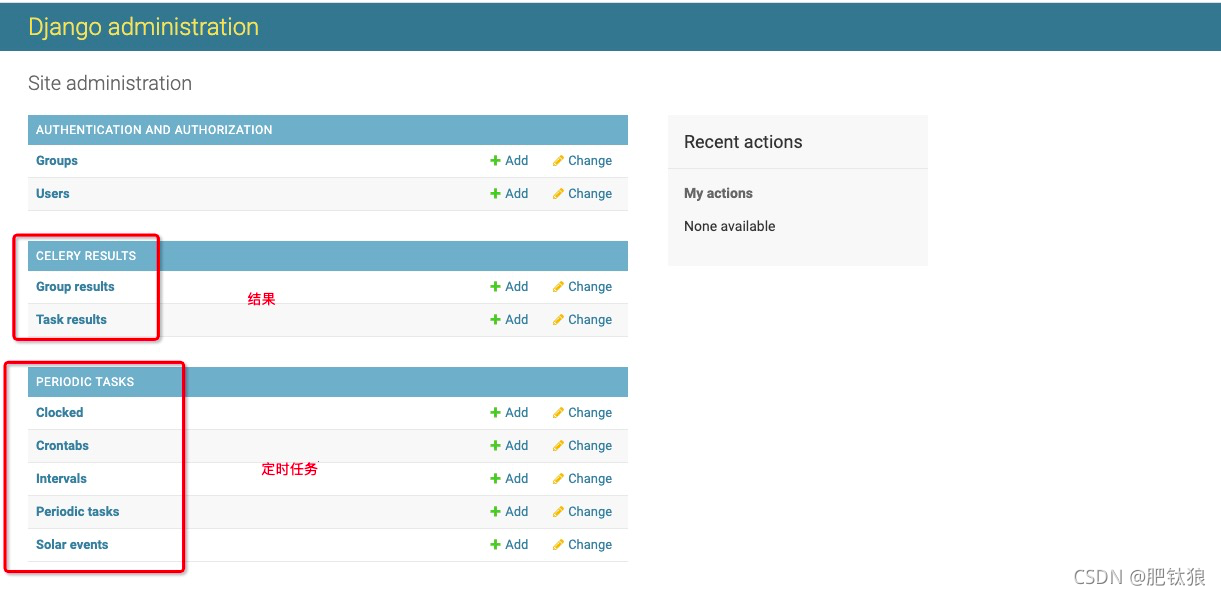
启动定时器:celery -A celery_demo worker -l info --beat
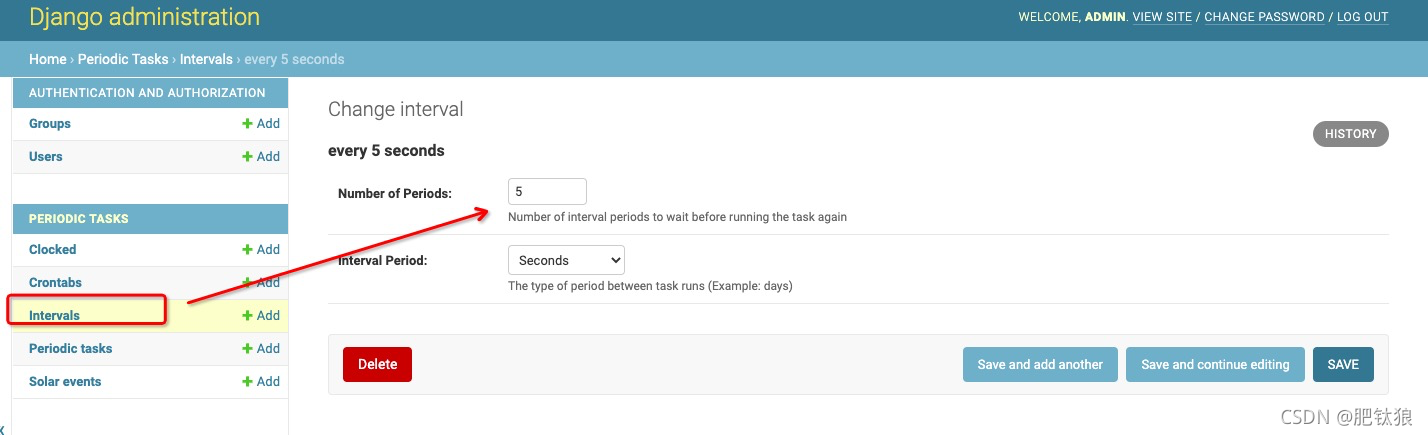
定时器与任务关联
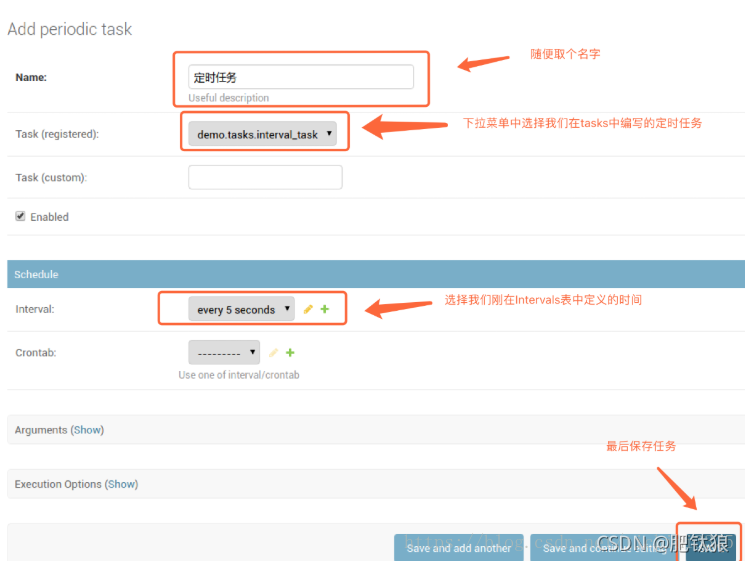
定时器运行

异步任务执行进程

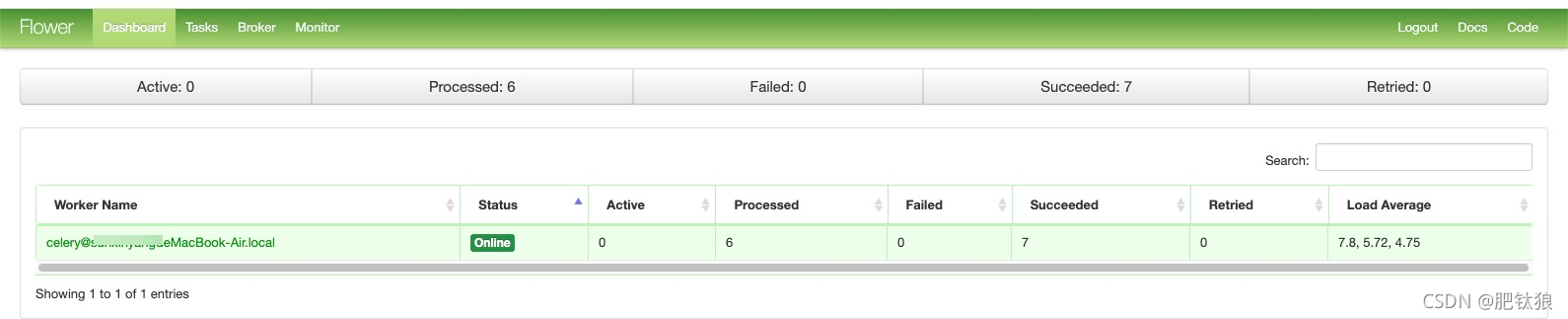
启动flower可进行监控:在http://localhost:5555查看
安装
pip3 install flower
启动
celery -A 项目名 flower
运行报错
[2022-03-27 07:55:39,366: ERROR/MainProcess] Unrecoverable error: AttributeError("'str' object has no attribute 'items'",)
Traceback (most recent call last):
File "/Users/sunxinyang/Desktop/LaatUI/venv/lib/python3.6/site-packages/celery/worker/__init__.py", line 206, in start
File "/Users/sunxinyang/Desktop/LaatUI/venv/lib/python3.6/site-packages/celery/bootsteps.py", line 123, in start
info = {}
解决
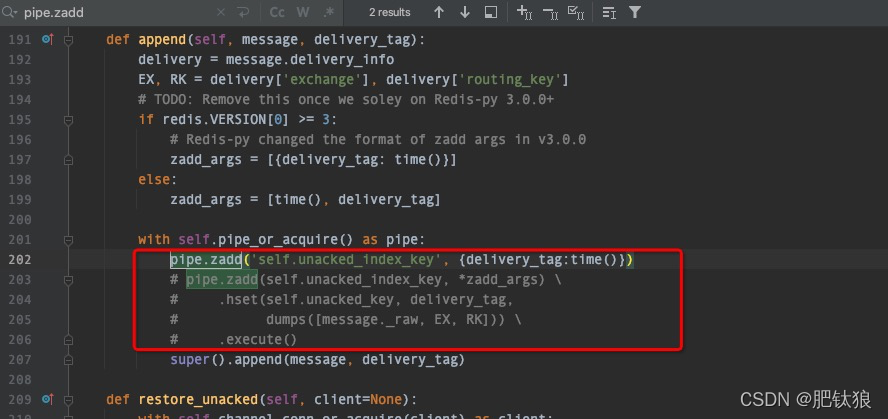
#解决办法:直接进入 File "/home/python/.virtualenvs/django_class/lib/python3.5/site-packages/kombu/transport --这个目录下
#修改redis.py文件里面的这行代码: pipe.zadd(self.unacked_index_key, delivery_tag, time())
###改成pipe.zadd(‘self.unacked_index_key’, {delivery_tag:time()})
celery设置并发数
标准文档:
https://docs.celeryproject.org/en/stable/userguide/workers.html
该文档是通过在启动时设置并发参数实现的
https://docs.celeryproject.org/en/stable/userguide/concurrency/eventlet.html#examples
该文档是对多worker的一个延伸。
参考文档:
https://blog.csdn.net/myli_binbin/article/details/90374660
该文档里面的并发时通过写配置文件实现的
并发实现:
–concurrency 设置并发的数量
celery -A proj worker --loglevel=INFO --concurrency=10
可以在一台机器上启动多个woker,但是最好使用不同的名称来标识他们
celery -A proj worker --loglevel=INFO --concurrency=10 -n worker2@%h
celery -A proj worker --loglevel=INFO --concurrency=10 -n worker1@%h
celery获取任务执行结果
在某些特定情境下,我们会先发起celery任务,过一段时间之后再获取其执行结果,而不用一直等待。返回的result其实就是一个唯一的<class ‘celery.result.AsyncResult’>对象。可以同过str(<class ‘celery.result.AsyncResult’>)获取对应的id。任务不要忘了return值出来,没有
值获取的是None。
from celery.result import AsyncResult
res=AsyncResult("62051878-ca77-4895-a61f-6f9525681347") # 参数为task id
res.result
批量删除
使用ModelViewSet可以自动生成删除单个资源的方法,删除的url是/resource_name/pk/。如果想要批量删除可以写继承APIView的类,自定义delete方法,如果使用ModelViewSet的话可以在类里面写一个批量删除的函数:
from rest_framework.decorators import action
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
@action(methods=['delete'], detail=False)
def multiple_delete(self, request, *args, **kwargs):
delete_id = request.query_params.get('deleteid', None)
if not delete_id:
return Response(status=status.HTTP_404_NOT_FOUND)
for i in delete_id.split(','):
get_object_or_404(User, pk=int(i)).delete()
return Response(status=status.HTTP_204_NO_CONTENT)
action装饰器使multiple_delete方法接受delete操作,detail=False使得在users/后面直接跟方法名而不用加/pk/。
api/user/multiple_delete/?deleteid=1,2,3















 1779
1779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









