







最近在工作中用到了celery,这里就简单的记录下,如果需要更详细的使用方法,那就看官方文档,你想要的它都有
(一)简介
-
什么是Celery ?
- Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度。
-
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
- 消息中间件(broker)
- Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis等等
- 任务执行单元(worker)
- Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
- 任务结果存储(Task result store)
- Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, redis等
- 消息中间件(broker)
它的工作流程:任务生产者将任务发送到broker的任务队列中,worker在到broker中取任务,worker后台异步执行任务,执行完成后将结果存放到backend中。

(二)安装celery
废话讲完,现在安装celery
pip install celery
如果你的中间件使用redis,那还需要安装python操作redis的客户端
pip install redis
(三)简单使用版
celery的目录结构有好几种,这里仅介绍我使用的一种,和比较简单的一种,下面broker和backend都以redis为示列,如果连接的redis有密码,格式差不多像这样
redis://:password@host:port/db
下面是简单版
先创建一个tasks.py
import celery
broker = 'redis://127.0.0.1:6379/1'
backend = 'redis://127.0.0.1:6379/2'
app = celery.Celery('app', backend=backend, broker=broker)
@app.task
def add_num(a, b):
c = a + b
return c
# 这里实现一个简单的数字相加功能
上面代码已经实现了一个最简单的celery任务配置,那如何调用呢,调用就是在其他代码导入add_num函数使用即可,看示列
from tasks import add_num
result = add_num.delay(1, 2)
print(result.id)
result2 = add_num.delay(11, 22)
print(result2.id)
# 58a55de1-a569-4d34-a95b-4f297d66cf56
# ff471254-51c9-419d-8c84-f6e906917e80
上面代码通过函数加delay方法传参就可以将这两个数字相加的异步任务发送到broker中,并且调用后会返回给我们两个任务id,这个id用来给我们查询任务状态和任务结果
此时任务已经发送到broker中,但并没有消费者执行,所以我们还要启动Worker消费任务,Worker执行完任务后就会将结果存放在backend里
# 格式为:celery -A app对象所在的文件 worker -l 日志级别
celery -A tasks worker -l info
执行上面的命令必须与tasks.py在同级目录下,celery对目录要求严格,下面是命令输出内容
User information: uid=0 euid=0 gid=0 egid=0
warnings.warn(SecurityWarning(ROOT_DISCOURAGED.format(
-------------- celery@ps v5.3.1 (emerald-rush)
--- ***** -----
-- ******* ---- Linux-5.15.0-76-generic-x86_64-with-glibc2.35 2023-07-04 16:10:33
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: app:0x7fde1ef70970
- ** ---------- .> transport: redis://:**@127.0.0.1:6379/1
- ** ---------- .> results: redis://:**@127.0.0.1:6379/2
- *** --- * --- .> concurrency: 24 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. tasks.add_num
[2023-07-04 16:10:33,947: INFO/MainProcess] Connected to redis://:**@127.0.0.1:6379/1
[2023-07-04 16:10:33,949: INFO/MainProcess] mingle: searching for neighbors
[2023-07-04 16:10:34,955: INFO/MainProcess] mingle: all alone
[2023-07-04 16:10:34,973: INFO/MainProcess] celery@ps ready.
[2023-07-04 16:10:35,190: INFO/MainProcess] Task tasks.add_num[58a55de1-a569-4d34-a95b-4f297d66cf56] received
[2023-07-04 16:10:35,194: INFO/MainProcess] Task tasks.add_num[ff471254-51c9-419d-8c84-f6e906917e80] received
[2023-07-04 16:10:35,198: INFO/ForkPoolWorker-16] Task tasks.add_num[58a55de1-a569-4d34-a95b-4f297d66cf56] succeeded in 0.006506197001726832s: 3
[2023-07-04 16:10:35,199: INFO/ForkPoolWorker-1] Task tasks.add_num[ff471254-51c9-419d-8c84-f6e906917e80] succeeded in 0.0018085810006596148s: 33
接下来就是任务状态和结果的查询
from celery.result import AsyncResult
from tasks import app
async_result = AsyncResult(id="58a55de1-a569-4d34-a95b-4f297d66cf56", app=app)
if async_result.successful():
result = async_result.get() # 获取结果
print(result)
# result.forget() # 将结果删除
elif async_result.failed():
print('执行失败')
elif async_result.status == 'PENDING':
print('任务等待中被执行')
elif async_result.status == 'RETRY':
print('任务异常后正在重试')
elif async_result.status == 'STARTED':
print('任务已经开始被执行')
(四)部署版
下面介绍我现在的使用方式
目录结构
tree my_celery/
my_celery/
├── config.py
├── __init__.py
├── main.py
└── tasks.py
my_celery目录有3个文件,config.py管理一些celery的配置,main.py是celery启动消费者时的入口文件也可以设置celery的配置,tasks.py用来注册celery的任务,也可以在my_celery目录下新建多个目录,每个目录下新建一个tasks.py,这样可以自动实现每个目录下tasks.py里的celery任务注册
config.py
broker_url = 'redis://127.0.0.1:6379/1'
result_backend = 'redis://127.0.0.1:6379/2'
# celery worker每次去redis预取任务的数量,默认值就是4
worker_prefetch_multiplier = 1 # 设置为1,一个unack,其他在等待
# 结果保存时间,6小时
result_expires = 6*60*60
# 追踪状态
task_track_started = True
# 设置任务超时时间
# task_time_limit = 10
# 设置任务完成才会应答的机制,否则任务默认为完成状态,配合rabbitmq可有效解决worker崩溃的问题
task_acks_late = True
# celery升到5.3后使用原来的启动命令会出警告,加上这个配置后就不会了
broker_connection_retry_on_startup = True
# 下面两个控制时区的,但结果存储数时间仍为utc时间
enable_utc = False
timezone = 'Asia/Hong_Kong'
# 每个worker消费100个任务后自动销毁
# worker_max_tasks_per_child = 100
# 如果将此设置为None,将永远重连
broker_connection_max_retries = None
# 设置优先级队列列表数量(针对redis,因为如果中间件为redis的话,如果同一个任务设置10个优先级的话,redis会默认将任务列表根据你设置的任务优先级动态调整列表数,比如你设置了10个优先级不同的任务,redis默认不会生成10个任务列表,可能会生成3个优先级任务列表,就变成了1~3优先级为一个,4~6为一个,7~9为一个
# 这种情况后,1~3优先级里的任务设置就不成立了,就可能会出现3优先级任务执行优先于1的,这时候任务的执行顺序就会完全按照任务进入队列的顺序,当然priority_steps也不是无限设置的,好像最大为10)
# 当然我们这里并不要设置10个优先级,但这并不影响
broker_transport_options = {
'priority_steps': list(range(10)),
}
#上面只是我写的配置,具体配置可以参考官方文档
main.py
# 主程序
from celery import Celery
# 创建celery实例对象
app = Celery("my_celery")
# 通过app对象加载配置,config对应上面的config.py的导入路径,因为启动消费者命令是在my_celery的同级目录,你也可以跳过config.py,使用app.conf的属性点出config.py的所有配置,比如app.conf.timezone = 'Asia/Hong_Kong'等
app.config_from_object("my_celery.config")
# 加载任务
# 参数必须必须是一个列表,里面的每一个任务都是任务的路径名称
# app.autodiscover_tasks(["任务1","任务2"]),因为我的目录下只有一个tasks.py,如果你的目录结构下有多个tasks.py,结构类似task1/tasks.py,task2/tasks.py 那这里就应该app.autodiscover_tasks(["my_celery.task1", "my_celery.task2"])
app.autodiscover_tasks(["my_celery", ])
# 设置时区
#app.conf.timezone = 'Asia/Hong_Kong'
# 启动Celery的命令
# 强烈建议切换目录到my_celery根目录下启动
# celery -A my_celery.main worker --loglevel=info
# celery -A my_celery.main worker -Q celery --loglevel=info -c 1#指定消费不同的队列
tasks.py
# celery的任务必须写在tasks.py的文件中,别的文件名称不识别!!!
from my_celery.main import app
from celery import Task
import time
import logging
logging.basicConfig(format='[%(filename)s:%(lineno)d] %(asctime)s - %(levelname)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=20)
# 自己定义的任务类
class MyTask(Task):
def run(self, *args, **kwargs):
pass
abstract = True
def on_failure(self, exc, task_id, args, kwargs, einfo):
logging.error(f'{task_id}执行失败')
def on_success(self, retval, task_id, args, kwargs):
logging.info(f'{task_id}执行成功')
@app.task(base=MyTask)
def send_num(**kwargs):
print(f"收到{**kwargs}")
time.sleep(1)
return f"{**kwargs} OK"
@app.task(base=MyTask) # name表示设置任务的名称,如果不填写,则默认使用函数名做为任务名
def task_start(**kwargs):
logging.info(f'异步任务接口接收到请求,参数为{kwargs}')
start_time = time.time()
# 具体业务代码
time.sleep(7)
print('执行任务')
logging.info(f"任务执行完成,耗时:{time.time() - start_time}")
return '完成'
这就我现在使用celery的完成一个项目配置,这点代码,根本无法面面俱到,最好的办法还是看celery的官方文档 文档传送门
下面启动celery
celery -A my_celery.main worker -Q 队列名 --loglevel=info -c 1
#这里启动celery,要求在my_celery的同级目录下,不是my_celery的目录下
#-Q 队列名 用来指定消费监听消费那个队列,因为任务生产者在将任务发送到broker时还会指定是那个队列,如果没有,任务就会发送到默认的celery队列,如果这里不指定-Q参数,那该消费者就会默认监听broker里的celery队列,还有就是如果你希望该消费者监听多个队列,参数可以像这样配置-Q queue1,queue2,queue3,....
#--loglevel=info指定日志级别
#-c 1 指定并发数
还是那句话,官方文档
如何调用,任务调用的方式与上面简单的使用的调用方法一致,将对应的celery任务注册函数导入并调用加上delay方法传参,其实除了delay方法调用,还有一个方法叫apply_async,相比于delay,该方法可以传更多的参数比如任务优先级,任务的队列,任务的过期时间…
你可以理解apply_async是delay的加强版,有更多的参数选项设置
send_num.apply_async(kwargs={'a': 1}, queue='common',priority=0)
#kwargs传递的关键字参数
#queue表示任务发送到的队列,与启动消费者时的-Q参数相对应
#priority 任务的优先级
其实区别于delay和apply_async这种将注册函数导入然后加上delay或apply_async的模块执行方法,还有一种不依赖于导入的执行方法。
这种执行方法较send_task,具体使用方法如下
from celery import Celery
#config_source与消费者端相同的配置文件
app = Celery(config_source='my_celery.config')
#可能有人觉得导入配置文件的方法也麻烦,那还可以用app.config_from_object()将配置以参数的形式传入
# app.control.broadcast('shutdown')
ret = app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '1'}, queue='common', priority=0)
print(ret.id)
其实我更喜欢这种方法,这种方法仅依赖于一个配置文件config_source='my_celery.config’或者也可以用app.conf的属性配置所有配置项,或者用Celery参数进行配置,这种方法摆脱了模块化导入方式的调用,更加自由,因为不用加载tasks.py,这样的好处是我们就不用执行tasks.py里的代码,因为我们在生产者端有的时候并不希望执行tasks.py里的代码,我们只是需要他作为接口生成异步任务。这样以来只需维护一份config.py就可以了
(五)任务优先级
在使用apply_async或send_task方法调用异步任务的时候,为了控制任务的优先级可以传递一个priority的参数,值越小,任务优先级与为高
celery的任务优先级就是给不同优先级的任务生成不同的队列,然后优先消费优先级高的队列,比如下面给common队列中插入10个优先级不同的任务,broker里就会生成10中common队列,其中priority=0的为common
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '9'}, queue='common', priority=9)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '8'}, queue='common', priority=8)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '7'}, queue='common', priority=7)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '6'}, queue='common', priority=6)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '5'}, queue='common', priority=5)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '4'}, queue='common', priority=4)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '3'}, queue='common', priority=3)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '2'}, queue='common', priority=2)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '1'}, queue='common', priority=1)
app.send_task(name='my_celery.tasks.send_num', kwargs={'a': '0'}, queue='common', priority=0)
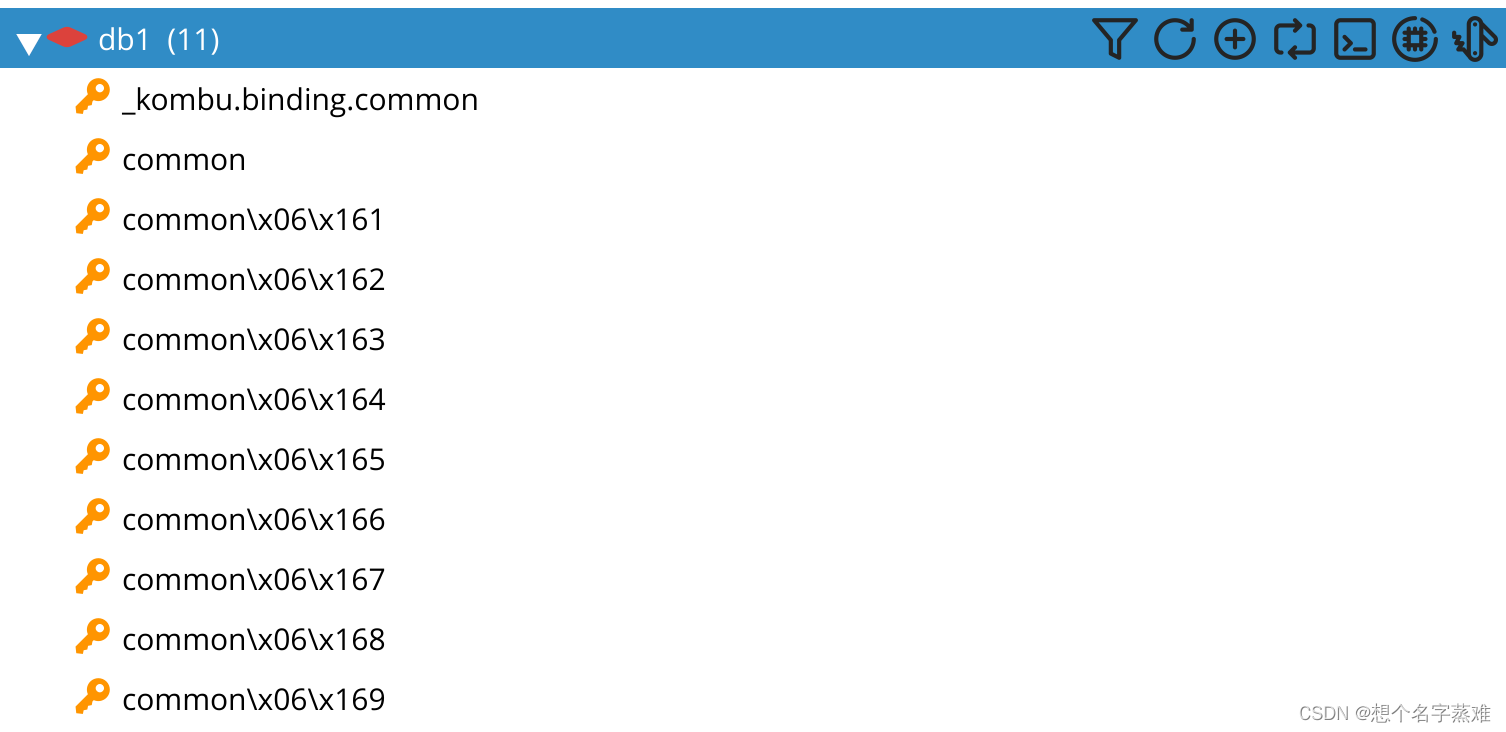
要实现上面不同优先级common任务队列生成,config.py里的broker_transport_options参数配置至关重要,设置优先级队列列表数量(针对broker为redis,因为如果中间件为redis的话,如果同一个任务设置10个优先级的话,redis会默认将任务列表根据你设置的任务优先级动态调整列表数,比如你设置了10个优先级不同的任务,redis默认不会生成10个任务列表,可能会生成3个优先级任务列表,就变成了1~3优先级为一个,4~6为一个,7~9为一个,我的理解是broker_transport_options参数是用来控制优先级粒度的,如过不设置该参数,celery就会动态的调整优先级队列,这种情况后,1~3优先级里的任务设置就不成立了,就可能会出现3优先级任务执行优先于1的,这时候任务的执行顺序就会完全按照任务进入队列的顺序,当然priority_steps也不是无限设置的,好像最大为10),如下图

(六)celery事件监听
celery的事件大致有两种,一种是任务事件,还有一种worker(消费者)事件
Task Events
- celery事件
- 任务事件
- task-sent
- task-received
- task-started
- task-succeeded
- task-failed
- …
- worker事件
- worker-online
- worker-heartbeat
- worker-offline
- 任务事件
详见 文档传送门
下面是监听脚本
from celery import Celery
# 创建Celery实例
app = Celery(config_source='my_celery.config')
def on_worker_online(event):
print('worker上线事件', event)
def on_worker_offline(event):
print('worker离线事件', event)
def on_worker_heartbeat(event):
print('worker心跳事件', event)
# 监听任务事件
with app.connection() as connection:
recv = app.events.Receiver(connection, handlers={
'worker-online': on_worker_online,
'worker-offline': on_worker_offline,
'worker-heartbeat': on_worker_heartbeat
})
print('监听中....')
recv.capture(limit=None, timeout=None, wakeup=True)
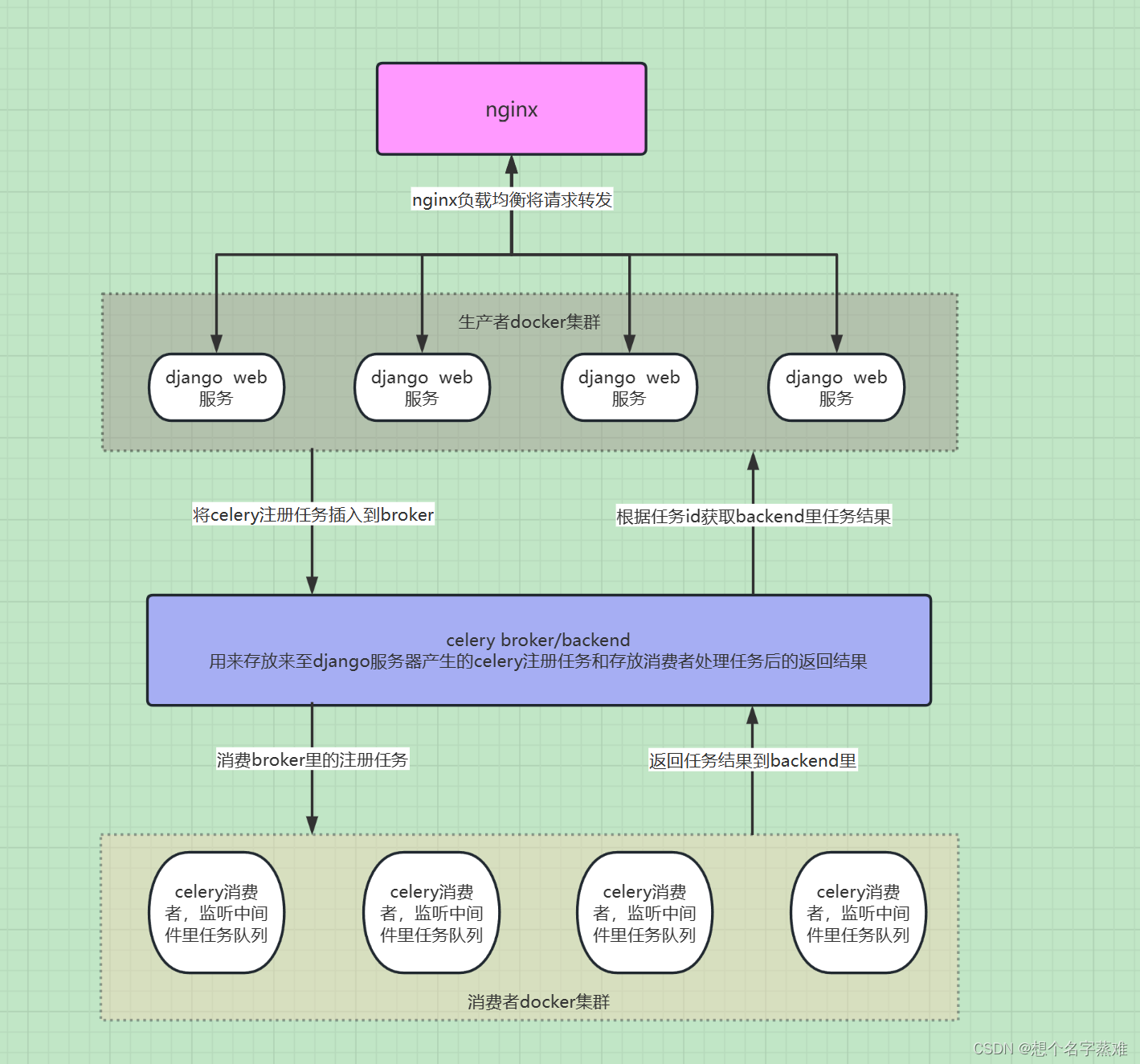
下面是当前我的服务的一个结构
(七)监控flower
Celey是一个分布式任务队列系统,而Flower是Celey的监控工具。它提供了一个用户友好的Web界面,用于实时监控和管理Celey集群。
- 下面是一些关于Celey监控工具Flower的特点和功能的介绍:
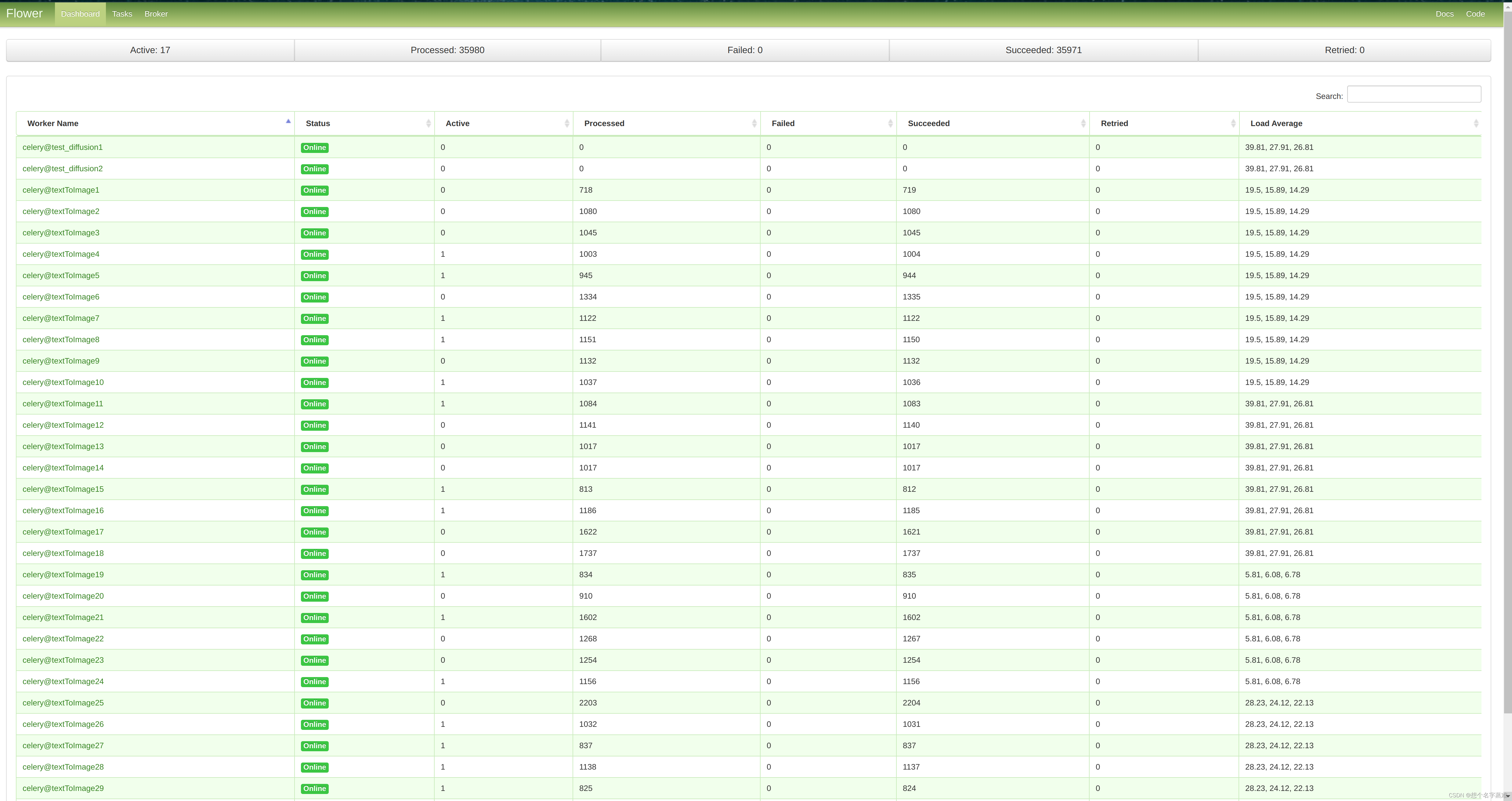
- 实时监控任务:Flower能够显示Celey集群中所有任务的实时状态和统计信息。你可以看到任务的执行时间、结果状态等。通过监控,你可以及时了解任务的执行情况,方便进行问题排查和优化。
- 任务历史记录:Flower会保存Celey集群中的任务历史记录,包括任务的执行时间、结果、参数等。这对于追溯任务执行的历史非常有用,特别是当你需要审计或进行故障排查时。
- 任务详情和日志:Flower提供了详细的任务信息和日志查看功能。你可以查看任务的输入参数、输出结果,并获取任务执行过程中的日志信息。这有助于理解任务的运行情况和排查潜在问题。
- 执行任务操作:Flower还允许你手动控制任务的执行,例如终止正在运行的任务或重新执行失败的任务。这使得你可以更加灵活地管理和调度任务。
- 集群状态监控:除了单个任务的监控外,Flower还提供了整个Celey集群的状态监控功能。你可以查看集群中各个节点的健康状态、任务队列的长度等信息。
总之,Flower是Celey的一个强大工具,可以帮助你实时监控和管理Celey任务队列系统。它提供了丰富的功能,让你更好地了解任务执行情况并进行必要的操作和优化。使用Flower,你可以更高效地使用Celey来完成分布式任务的调度和管理。
安装
pip install flower
启动监控
celery --broker=redis://127.0.0.1:6379/1 flower --port=5555
监控页面
flower还是好用,flower官方文档 文档传送门
(八)结语
其实我使用celery更看重他的分布式能力,比如说我现在的一个应用场景就是django作为任务生产者调用celery的注册任务方法将任务送到broker(redis)里,消费者是一个个docker容器(每个docker容器分配一张显卡),里面跑着celery的消费者进程监控任务队列,任务结果如果任务结果比较小的话可以直接存储的redis里,像我这里容器的返回结果是多张图片,所以这里没有直接将图片存在redis里,是将图片存储在minio文件服务器里,redis里存储minio的对象名,如果有什么错误的地方,还请大家批评指正。最后,希望小伙伴们都能有所收获。写这些,仅记录自己学习使用celery的过程


















 2502
2502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









