








Motivation:
多行为推荐系统(MBR)致力于利用多种行为去提升目标行为的性能。
本论文argue MBR模型应该:
1.建模用户在不同行为之间的粗粒度共性(公共偏好)。
2.同时考虑序列视图和全局图视图的多行为建模。
3.捕获用户在多个行为之间的细粒度差异。
因此
本论文提出一个新颖的多行为多视图对比学习推荐框架(MMCLR)
1.多行为CL致力于让每个视图中同一个用户的不同行为是相似的。
2.多视图CL致力于弥合用户序列视图的表征和图视图的表征的差距。
3.行为区分CL关注建模不同行为的细粒度差异。
Contribute:
1.在MBR中系统考虑了多种对比学习任务,To the best of our knowledge,本论文是第一个在MBR中引入对比学习的。
2.本论文提出了多行为CL任务和多视图CL任务,来建模不同行为之间粗粒度共性和两个视图更好的表征。
3.同时也设计了行为区分CL任务,通过CL框架建模多行为之间的细粒度差异和行为优先级。
4.实验中MMCLR性能比SOTA的baselines都更work。
Problem formulation:
多行为建模:
U和V表示用户和物品集合,B种行为{b1…bB},其中bt表示目标行为。
多视图建模:
1.序列视图: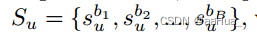
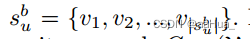
2.图视图:B种行为分别构成的图。
Method:
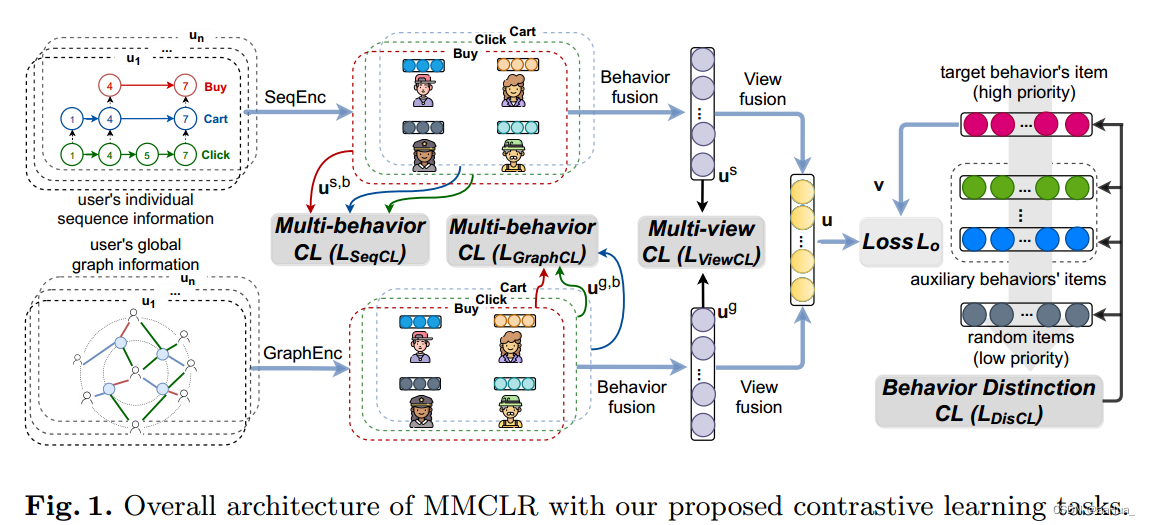
MMCLR由三部分组成:多视图编码器、多行为融合、多视图融合。
1.多视图编码器:
序列视图致力于准确捕获用户的局部序列信息。
图视图致力于捕获用户全局的信息。
SeqEnc()利用Bert4rec, GraphEnc()利用lightGCN。
这里学的是用户每个行为b的表征。
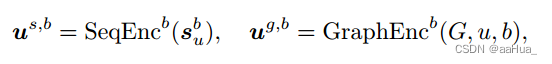
2.多行为融合:
分别构建两个视图用户不同行为的融合表征
注意:对于图视图,我们按照用户的融合形式也得到物品的融合表征vg。
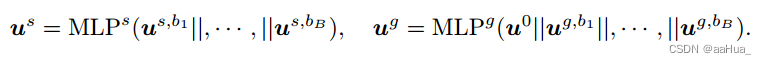
3.多视图融合:
用户表征融合是用户序列视图学习到的表征和图视图学习到的表征构成。
物品表征融合是图视图物品原始表征和图视图学习到的表征构成。
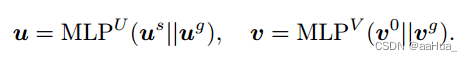
对于学到的用户和物品表征,利用BPR loss去优化目标。
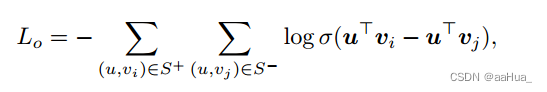
同时三种类型的对比学习任务也被设计来获取多行为和多视图的特征交互。
多视图多行为对比学习:
1.多行为对比学习:
1)序列多行为对比:
对于mini-batch的N个用户,用户i随机挑选两个行为表征b1和b2作为正例,用户i的b1行为和用户j的b2行为作为负例。
做对比前,先对用户的行为表征映射到同一个语义空间中,如下:
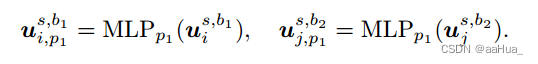
定义InfoNCE loss如下:
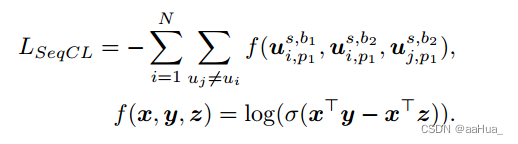
2)图多行为对比:
同理1)序列多行为对比

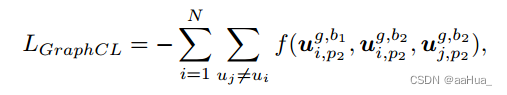
2.多视图对比学习:
多视图CL致力于强调单独序列视图和全局图之间的关系。
正例: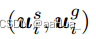
负例: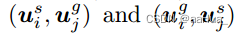
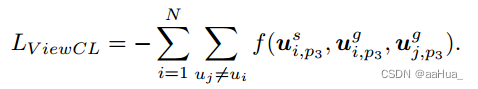
行为区分对比学习:
本论文设定了行为优先级:用户u对于物品 优先级顺序:目标行为物品vi >> 辅助行为物品vj >> 其他随机物品vk
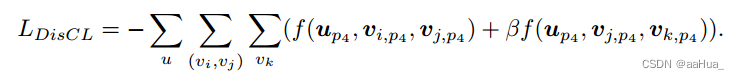
Model Training:
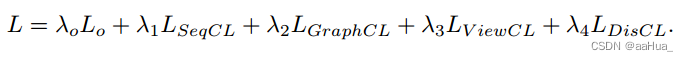
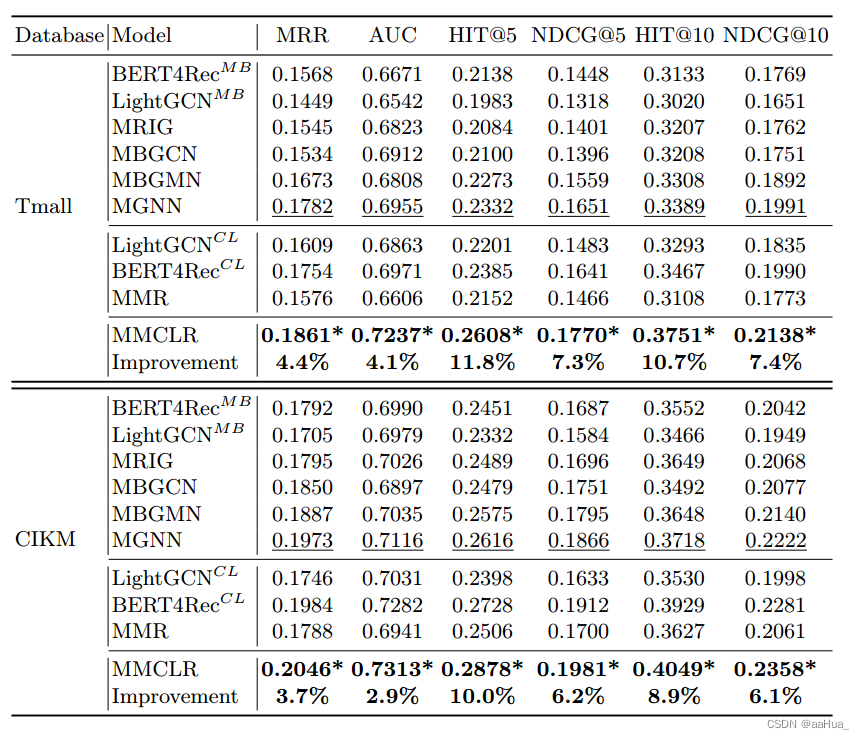
Dataset:
Tmall 、CIKM
Experiments:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











