








Dataframe的简易应用
文章目录
前言
工作中接触到了数据清洗之类的工作。现在不对 Numpy、Serise、Dataframe 的基础进行研究,后续有机会再补充。此次只对 Dataframe 的简单应用做记录。
注意:代码均使用 jupyter notebook 运行。
一、清洗数据
1. pandas读取数据
本次使用 pandas 读取多个 csv 文件,并连接成一个 Dataframe
传送门 - pandas read_csv() 官方文档
import pandas as pd
_path = r'D:\data'
li = []
for _root, _dir, _file in os.walk(_path):
for i, f in enumerate(_file):
_csv = os.path.join(_root, f)
# _csv: csv路径
# index_col: 是否添加 列自增索引
# header:用作列名的行号和数据的开头
df = pd.read_csv(_csv, index_col=None, header=0)
li.append(df)
# dataframe 连接
frame = pd.concat(li, axis=0, ignore_index=True)
axis 参数
axis=0 代表:维度 或 轴 为0。
axis是 维度/轴 单位。在Numpy里, 我的理解是它跟空间维度不完全一样,单独理解成数组嵌套可能好理解一点。人类只能理解到三维数据,但axis可以指向高维,方便高维数据修改。
axis 例子:
import numpy as np
np1 = np.array([[1,2,3],[2,3,4]])
np2 = np.array([[9,9,9],[8,8,8]])
# axis=0 代表第一维度,针对第一层列表 [ ..., ... ]操作
# axis=1 代表第二维度,针对第二层列表 [1,2,3] [2,3,4] 操作
np.concatenate((np1,np2), axis=0)
> array([[1, 2, 3],
[2, 3, 4],
[9, 9, 9],
[8, 8, 8]])
np.concatenate((np1,np2),axis=1)
array([[1, 2, 3, 9, 9, 9],
[2, 3, 4, 8, 8, 8]])
2. 创造数据
from datetime import datetime
def str_to_date(str):
return datetime.strptime(str, '%Y-%m-%d').date()
data = [{'DATE':str_to_date('2020-01-01'), 'TYPE': 'TypeA', 'SALES': 1000},
{'DATE':str_to_date('2020-01-01'), 'TYPE': 'TypeB', 'SALES': 200},
{'DATE':str_to_date('2020-01-01'), 'TYPE': 'TypeC', 'SALES': 300},
{'DATE':str_to_date('2020-02-01'), 'TYPE': 'TypeA', 'SALES': 700},
{'DATE':str_to_date('2020-02-01'), 'TYPE': 'TypeB', 'SALES': 400},
{'DATE':str_to_date('2020-02-01'), 'TYPE': 'TypeC', 'SALES': 500},
{'DATE':str_to_date('2020-03-01'), 'TYPE': 'TypeA', 'SALES': 300},
{'DATE':str_to_date('2020-03-01'), 'TYPE': 'TypeB', 'SALES': 900},
{'DATE':str_to_date('2020-03-01'), 'TYPE': 'TypeC', 'SALES': 100}
]
df = pd.DataFrame(data)
df
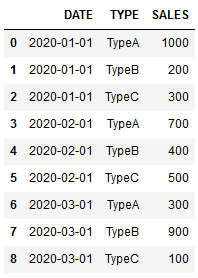
3. 选择指定的列
df = frame.loc[:, ['TYPE']]
df
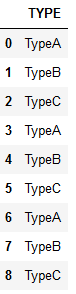
4. 分组统计
(1) 统计个数:count()
根据 TYPE 分组,统计每组的个数
df.groupby("TYPE").count()
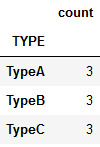
根据 TYPE 分组后,会自动将 TYPE 的值作为 索引。后边每列的列名并不重要,其实都表示每组的个数。可以 更改 列名获取更好的展示效果。

下面是 只选取部分列,并改列名 的代码。
# loc 是 Dataframe的方法,用来选取指定的 行 和 列。
# 第一个参数代表行 只有冒号代表所有行, 第二参数代表列
# rename 将某个列名改为什么名字
df.groupby("TYPE").count().loc[:, ["DATE"]].rename(columns={"DATE": "count"})
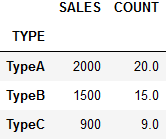
(2) 统计总数:sum()
自动将 数字 类型的数据进行加法运算
df.groupby(['TYPE']).sum()
(3) 其他
5. 排序
Dataframe的排序,功能上是跟Python的 sorted 类似的,也可以接收 key = lambda … 来根据某个列自定义排序。
# ascending=False 等于 sql 里的 desc。降序排序
df.sort_values(by="SALES", ascending=False)
二、画图
Dataframe的 plot 是基于 matplotlib 的,能够进行简单构图。如果需要更详细的画图功能,还需要使用 matplotlib。
中文问题
matplotlib 不支持中文, 画图的时候会生成乱码。需要查看当前系统中支持的中文有什么,在运行之初设置好。
from matplotlib.font_manager import FontManager
# 查看字体
mpl_fonts = set(f.name for f in FontManager().ttflist)
# print('all font list get from matplotlib.font_manager:')
# for f in sorted(mpl_fonts):
# print('\t' + f)
# 设置字体
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
1. 柱状图 bar
# 根据TYPE分类后价格汇总。
# rot: x周文字的旋转角度
# alpha: 柱状图的透明度
# figsize(w, h): 图的长宽大小
df.groupby("TYPE").sum().reset_index() \
.plot.bar(x='TYPE', y='SALES',
rot=50, alpha=0.75, figsize=(15,7),
xlabel = '售出总价', ylabel='商品类型', title='各类商品售出总价')

但是,如果 x轴的文字 太长了,出现相互遮挡的情况。
re_df = df.groupby("TYPE").sum().reset_index().replace(
{"TypeA": "这是一个非常长的字符长 A ","TypeB": "这是一个非常长的字符长 B ", "TypeC": "这是一个非常长的字符长 C "}
)
re_df.plot.bar(x='TYPE', y='SALES',
alpha=0.75, figsize=(5,5),
xlabel = '售出总价', ylabel='商品类型', title='各类商品售出总价')

单纯对图进行放大、旋转x字符串角度的效果不好,可以用 matplotlib 的 gcf().autofmt_xdate() 对 xlabel自动调整。
import matplotlib.pyplot as plt
# 画一个子图,设置大小。
f, ax = plt.subplots(figsize=(5,5))
plt.bar(re_df['TYPE'], re_df['SALES'])
# 设置x轴自适应
plt.gcf().autofmt_xdate()

2. 饼图 pie
饼图需要一个 index(索引) 来充当饼图的各个部分的名称,可以理解成柱状图额的x轴。
下图:
groupby([“TYPE”]).sum() : 自动将TYPE当作索引了。也可以使用 df.set_index( key ) 设置索引 。
y : 各个部分的数值
legend : 图例
autopct : 数值映射在图上的格式
shadow : 阴影
figsize : 图大小
pie(). legend(bbox_to_anchor=(x, y)) : \
# 饼状图, 标签占比
df.groupby(['TYPE']).sum().head(10)\
.plot.pie(y='SALES',
legend='TYPE',
autopct='%1.1f%%',
shadow = True,
figsize=(15,10),
title='各类别商品出售占比'
).legend(bbox_to_anchor=(1.3, 1))

如果一组数据需要画两个图。例如:
# 在df中加入一列数据,用来代表每天每类商品购买的人数。
df['PEOPLE'] = np.random.randint(1,10,9)
# 根据 TYPE 汇总,查看:这些天每类商品卖出多少钱,每类商品都有多少人买
df.groupby('TYPE').sum().plot(kind='pie',
subplots=True,
shadow = True,
autopct='%1.1f%%',
figsize=(15,10))
















 811
811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









