






Shuffle Differential Privacy(2)
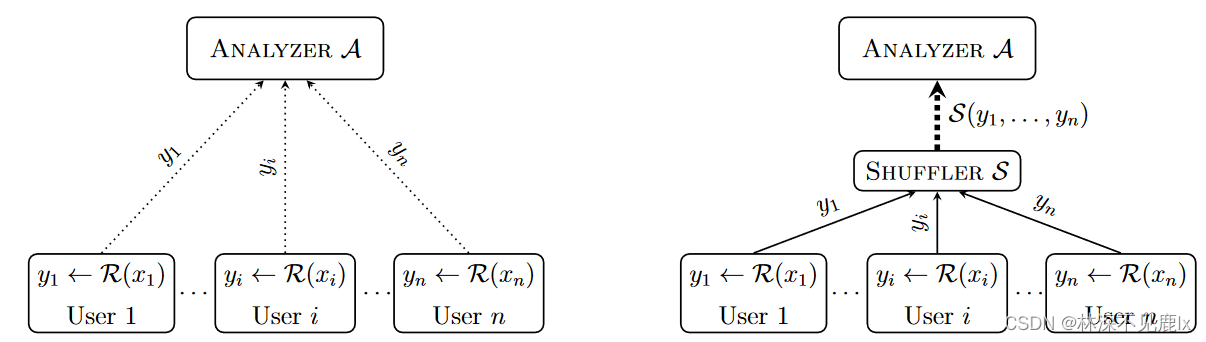
一、混洗差分隐私的“隐私毯”
The Privacy Blacket of the Shuffle Differential Privacy[1]
关键思想:将LDP报告的分布分解为两个分布,一个依赖于真实值,另一个独立随机。这个独立分布形成了一个“隐私毯”。
毯分解(blanket decomposition)
例如,在差分隐私单消息混洗模型 ( R , S , A ) (R,S,A) (R,S,A)下,有 n n n个用户,每个用户 u i u_i ui 持有一个输入 x i x_i xi并对其应用本地随机器 R R R获得单个消息 y i y_i yi,消息 ( y 1 , y 2 , … , y n ) (y_1,y_2,…,y_n) (y1,y2,…,yn)被混淆器 S S S打乱以获得 ( y σ ( 1 ) , y σ ( 2 ) , … , y σ ( n ) ) (y_{\sigma(1)},y_{\sigma(2)},…,y_{\sigma(n)}) (yσ(1),yσ(2),…,yσ(n)),其中 σ \sigma σ是随机选择的排列,最后由分析器 R R R对 ( y σ ( 1 ) , y σ ( 2 ) , … , y σ ( n ) ) (y_{\sigma(1)},y_{\sigma(2)},…,y_{\sigma(n)}) (yσ(1),yσ(2),…,yσ(n))进行后处理以得到分析结果。
定义一个概率参数 γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1],集合 B B B中包含 γ n \gamma n γn个用户,其中的用户将提交随机值,而剩余 ( 1 − γ ) n (1-\gamma) n (1−γ)n个用户将提交器其真实值。集合 B B B中的各方发送的值形成均匀随机值的直方图 Y 1 Y_1 Y1,而集合 B B B以外的各方发送的值对应于其数据的真实直方图 Y 2 Y_2 Y2。因此,在混洗模型中服务器端获得的信息相当于直方图 Y = Y 1 ∪ Y 2 Y=Y_1\cup Y_2 Y=Y1∪Y2。(其中 Y 1 Y_1 Y1为本地随机器 R R R的随机毯random blanket)
对于LDP下的GRR扰动协议,其输出分布可以被分解为如下形式:
∀ y ∈ D , P r [ G R R ( v ) = y ] = ( 1 − γ ) P r [ y ∣ v ] + γ P r [ U n i ( D ) = y ] . \forall y\in \mathcal{D},Pr[GRR(v)=y]=(1-\gamma)Pr[y|v]+\gamma Pr[Uni(\mathcal{D})=y]. ∀y∈D,Pr[GRR(v)=y]=(1−γ)Pr[y∣v]+γPr[Uni(D)=y].
上述结论的特例即对二进制数据混洗对应于安全加法(secure addition),当 k > 2 k>2 k>2时混洗对应于直方图的安全加法。
那么为了实现差分隐私,需要设置合理的 γ \gamma γ值使得在相邻数据集上计算时,总分布 Y Y Y的变化量有使得的限制。(即满足差分隐私的定义)
注意,当发生变化的用户(假设为第n个用户)在集合B中时,其上传的数据是均匀随机选择的,因此可以保证隐私。但若其不在B中,服务器在具有最大背景知识(即知道另外n-1个用户的真实数据)的情况下可以直接推断该用户的真实数据,导致隐私泄露。此时,服务器观察到 Y 1 ∪ { x n } Y_1\cup \{x_n\} Y1∪{xn},即随机直方图与该用户输入的并集。
直观上,协议的隐私性归结为设置 γ \gamma γ,以便 Y 1 Y_1 Y1适当地隐藏 x n x_n xn

(这里给出了隐私毯privacy blanket的定义,也有文章直接将上述的独立分布叫做隐私毯)
二、本地随机发生器 R R R的隐私分析
隐私直方图的本地随机发生器: R γ , k , n P H \mathcal{R}_{\gamma,k,n}^{PH} Rγ,k,nPH

(该算法简单理解即为上述提到的用户上传随机值或真实值的情况)
下述定理表明了对 γ \gamma γ适当选择下的协议隐私性:
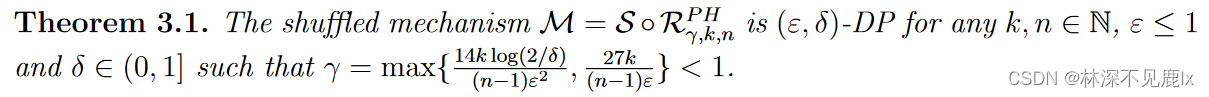
证明主要关注相邻数据集上用户 u n u_n un不在集合B中的情况,即该用户上传的是真实值
n j = Y 1 ( j ) + I [ x n = j ] n_j=Y_1(j)+\mathbb{I}[x_n=j] nj=Y1(j)+I[xn=j] 即随机分布中值j的数量加上用户n上传的真实数据是否为j(1或0)
所有 n j n_j nj的和即集合B中的用户总数加上第n个用户: ∣ B ∣ + 1 |B|+1 ∣B∣+1
假设相邻数据集中
x
n
=
1
x_n=1
xn=1,
x
n
′
=
2
x'_n=2
xn′=2 则有:
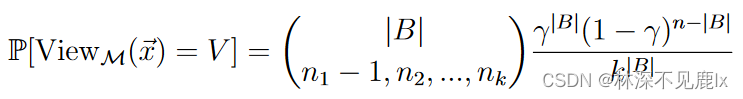
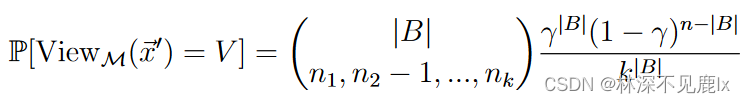
为了保证
(
ϵ
,
δ
)
−
D
P
(\epsilon,\delta)-DP
(ϵ,δ)−DP,需要证明:
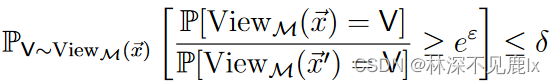
因此代入上述两个概率可以得到:
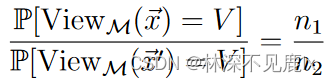
将 n 1 , n 2 n_1,n_2 n1,n2表示为表示为二项式分布即可得到:
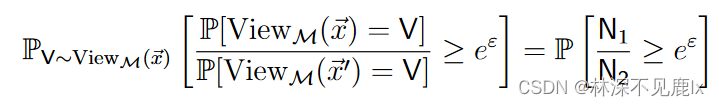
其中 N 1 ∼ B i n ( n − 1 , γ k ) + 1 , N 2 ∼ B i n ( n − 1 , γ k ) . N_1\sim Bin(n-1,\frac{\gamma}{k})+1,N_2\sim Bin(n-1,\frac{\gamma}{k}). N1∼Bin(n−1,kγ)+1,N2∼Bin(n−1,kγ).
接下来使用联合界(Union Bound)和乘法切诺夫界(Multiplicative Chernoff Bound)来限制上述概率:
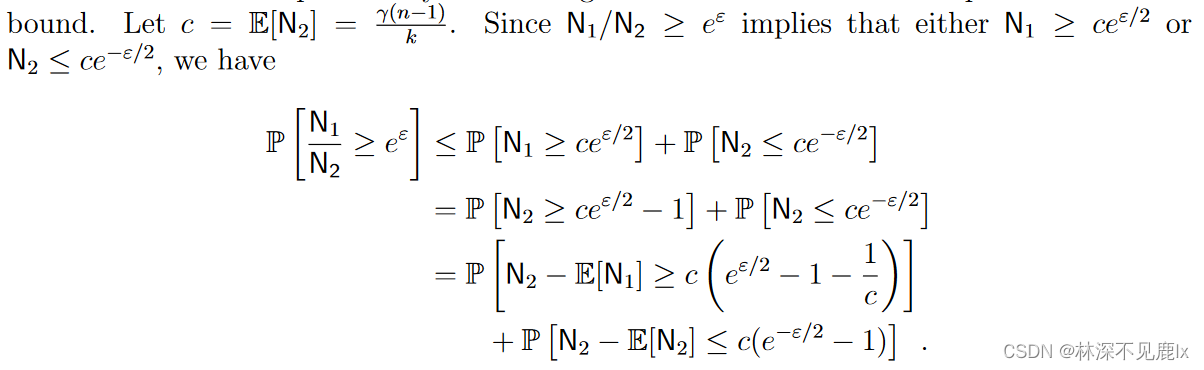
tips:
- 联合界(Union Bound)是概率论中的一个重要不等式,它用于对多个随机事件的概率上界进行估计。假设有一系列事件 A 1 , A 2 , . . . , A n A_1, A_2, ..., A_n A1,A2,...,An,那么这些事件至少其中之一发生的概率不会超过各事件发生概率之和。数学上可以表示为:
[ P ( ⋃ i = 1 n A i ) ≤ ∑ i = 1 n P ( A i ) ] [ P\left(\bigcup_{i=1}^n A_i\right) \leq \sum_{i=1}^n P(A_i) ] [P(i=1⋃nAi)≤i=1∑nP(Ai)]
-
乘法切诺夫界(Multiplicative Chernoff Bound)是Chernoff Bounds的一个变种,用于估计独立随机变量之积的概率。假设有一组独立同分布的随机变量 ( X 1 , X 2 , … , X n ) ( X_1, X_2, \ldots, X_n ) (X1,X2,…,Xn),它们的期望值为 μ \mu μ 。定义它们的乘积为 Y = X 1 ⋅ X 2 ⋅ … ⋅ X n Y = X_1 \cdot X_2 \cdot \ldots \cdot X_n Y=X1⋅X2⋅…⋅Xn。其可以表示为:
[ P ( Y ≥ ( 1 + δ ) μ n ) ≤ e − δ 2 μ 3 ] [ P(Y \geq (1+\delta)\mu^n) \leq e^{-\frac{\delta^2\mu}{3}} ] [P(Y≥(1+δ)μn)≤e−3δ2μ]
将乘法切尔诺夫界限应用于每个概率可以得出:
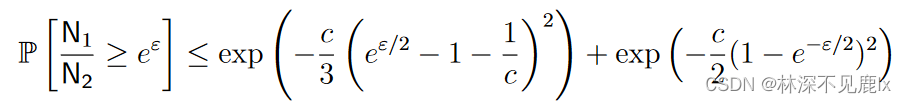
假设 ϵ ≤ 1 \epsilon \leq1 ϵ≤1,则右侧两个被加数都小于或等于 δ 2 \frac{\delta}{2} 2δ,如果满足下式:
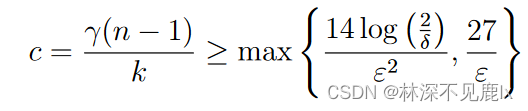
(上述证明在使用切尔诺夫不等式来限制隐私损失随机变量较大的概率时,为了简单起见假设了 ϵ ≤ 1 \epsilon \leq1 ϵ≤1。但在对 ϵ \epsilon ϵ没有限制时通过将 Chernoff 不等式替换为 Bennett 不等式来解释尾部边界中隐私丢失随机变量的方差,可以得到类似的结果。)
通过上述对于概率参数 γ \gamma γ的选择,本地随机发生器R满足 ϵ 0 − L D P \epsilon_0-LDP ϵ0−LDP,其中:
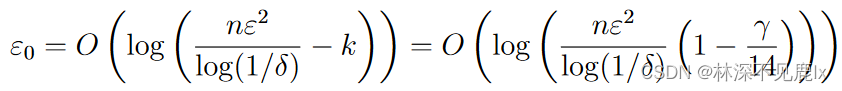
因此上述定理(Theorem3.1)可以被视为隐私放大声明:

注意隐私放大后结果为 ( ϵ , δ ) − D P (\epsilon,\delta)-DP (ϵ,δ)−DP而不是 ( ϵ , δ ) − L D P (\epsilon,\delta)-LDP (ϵ,δ)−LDP
参考文献:
[1]Balle, B., Bell, J., Gascón, A., Nissim, K. (2019). The Privacy Blanket of the Shuffle Model. In: Boldyreva, A., Micciancio, D. (eds) Advances in Cryptology – CRYPTO 2019. CRYPTO 2019.
[2]Wang, T., Xu, M., Ding, B., Zhou, J., Hong, C., Huang, Z., Li, N., & Jha, S. (2019). Improving utility and security of the shuffler-based differential privacy. Proceedings of the VLDB Endowment, 13, 3545 - 3558.















 3109
3109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









