







文章目录
1.数据库不用连接池的情况
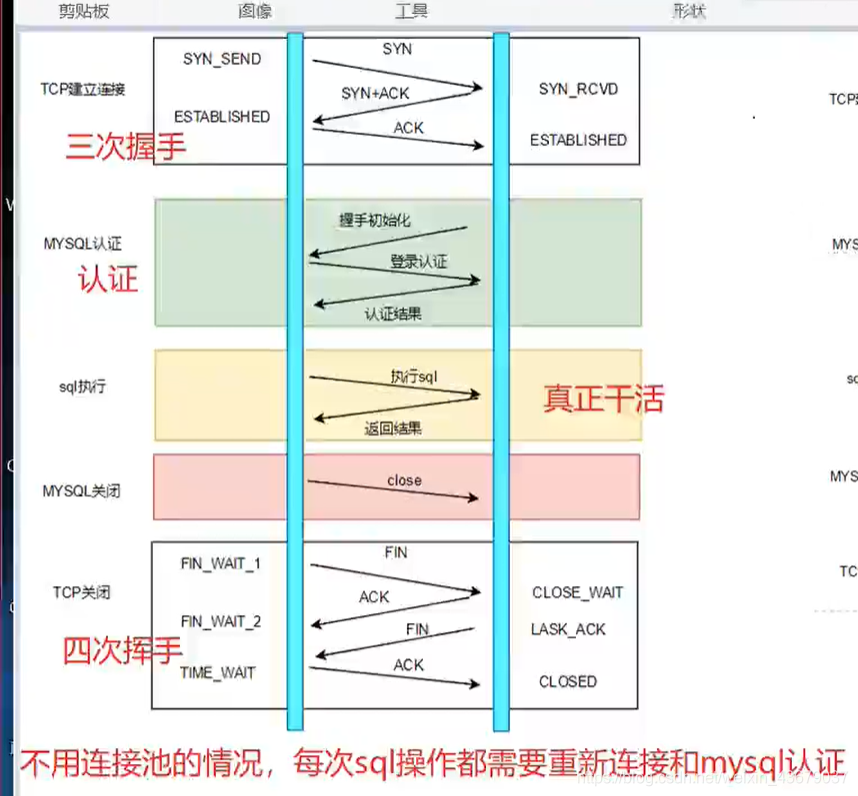
2.数据用了连接池的情况
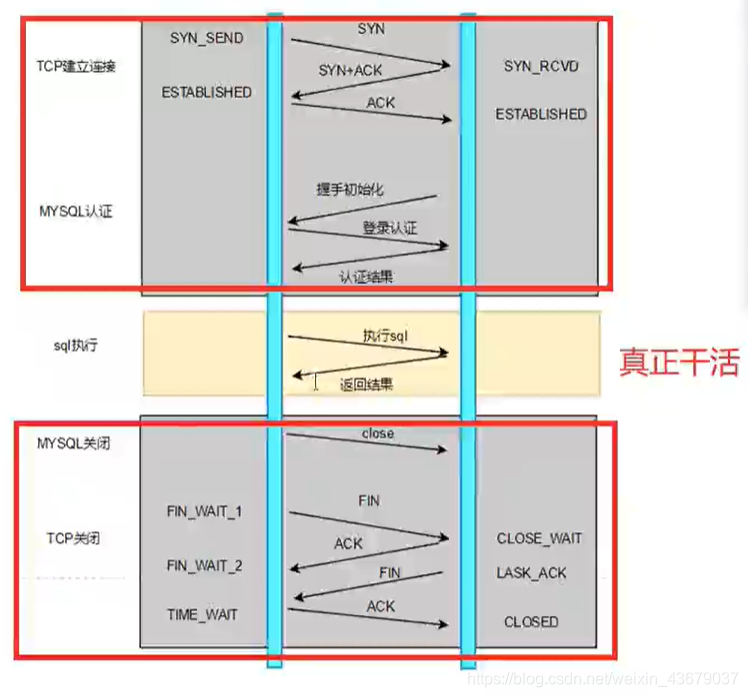
3.数据库与连接池的原理是一样的
1)redis连接池举例
- ①mysql和redis连接池的原理都是一样的
- ②例如输入一个语句
set teacher darren
ok
(交互的时候涉及到双方的TCP连接,第二个图片就是TCP连接的信息)

- ③redis举例代码示例
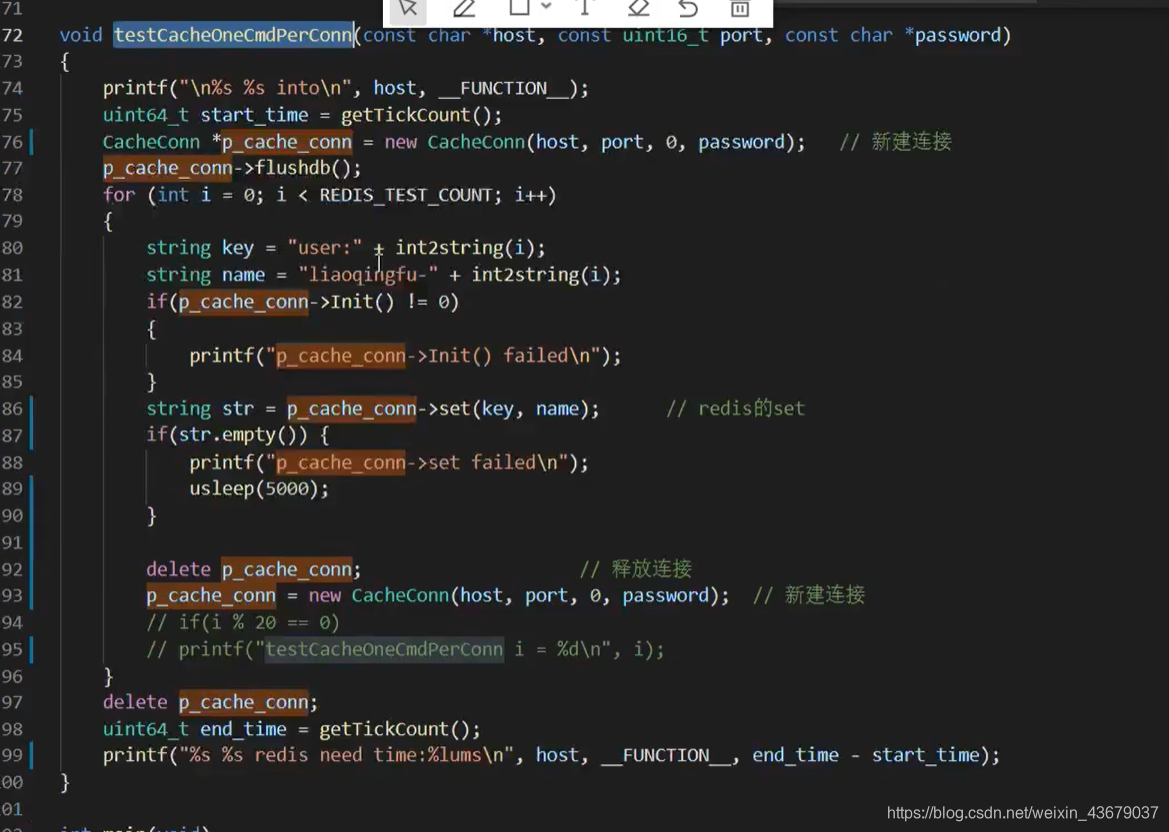
每次都要创建连接,释放连接 - ④复用redis连接
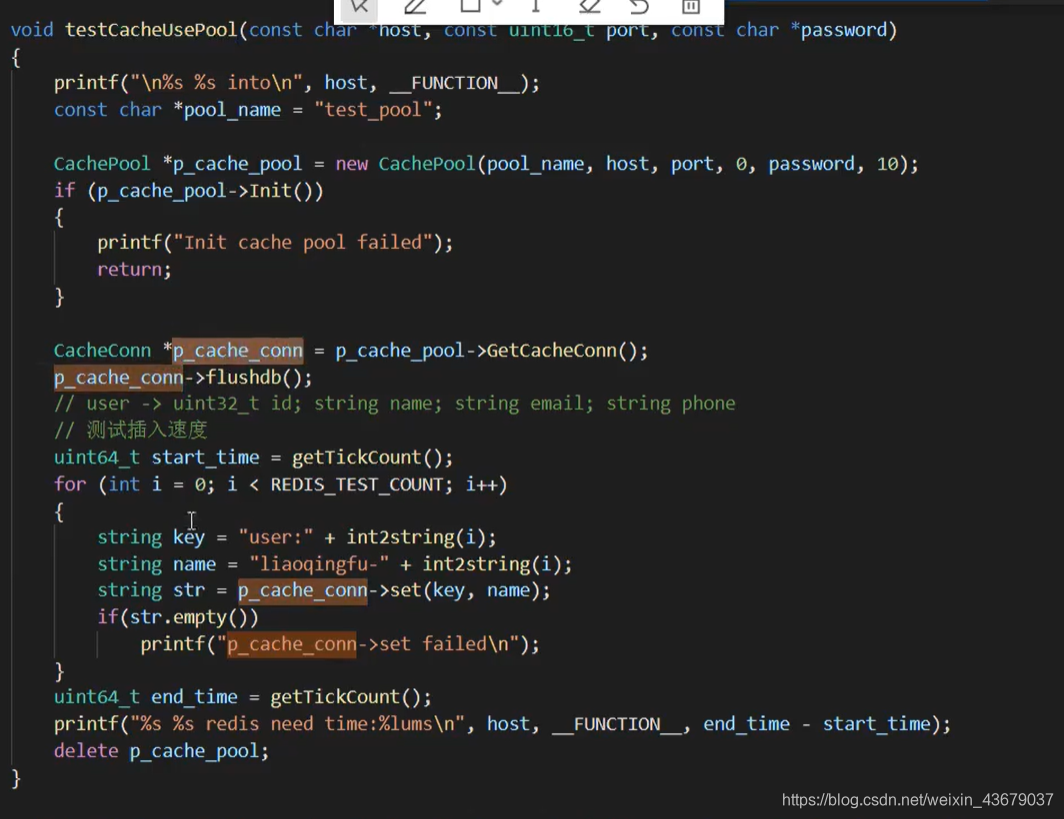
在for循环里面复用连接,连续set了一千次
下面是不用连接池的redis和用了连接池redis的区别,差了2倍多的时间,而且这个测试还是本地的连接,如果测试是外部的连接,这个延迟会更大
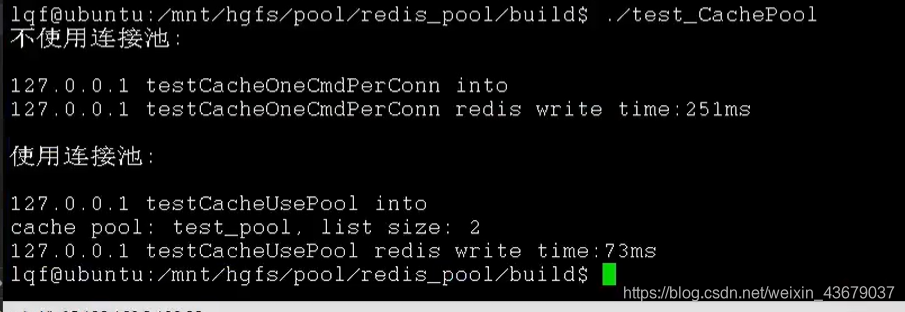
2)通过池化计数管理多个连接
3)mysql连接池举例
- ①mysql连接池初始化
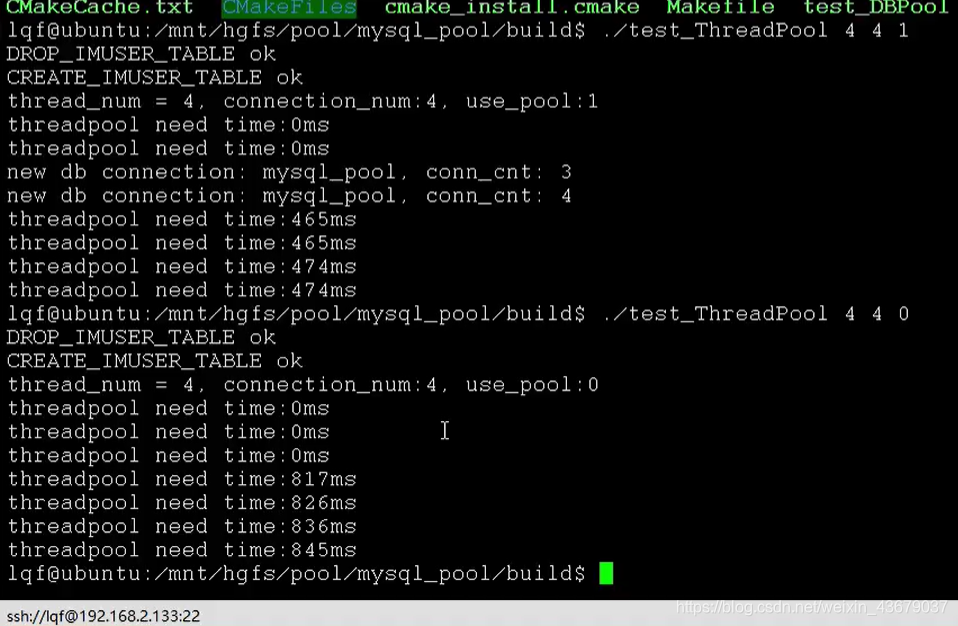
- ②mysql用连接池和不用连接池的对比
不用连接池比用了连接池多出一倍的时间
4.怎么创建连接池
1)创建连接,

所需要的信息:数据IP地址、端口、数据名称、用户名、密码
2)创建的连接要用什么管理,需要容器,比如list
3)提供对外接口,请求连接
4)归还连接
调用 RelDBConn(CDBConn *pConn); 函数来归还连接资源

用list管理空闲的连接

5)连接池的名字
连接池的名字db_pool_name
因为不同的连接池对应不同的业务:(例如主从复制)
写数据->masterpool
读数据->slavepool
5.连接池性能提升
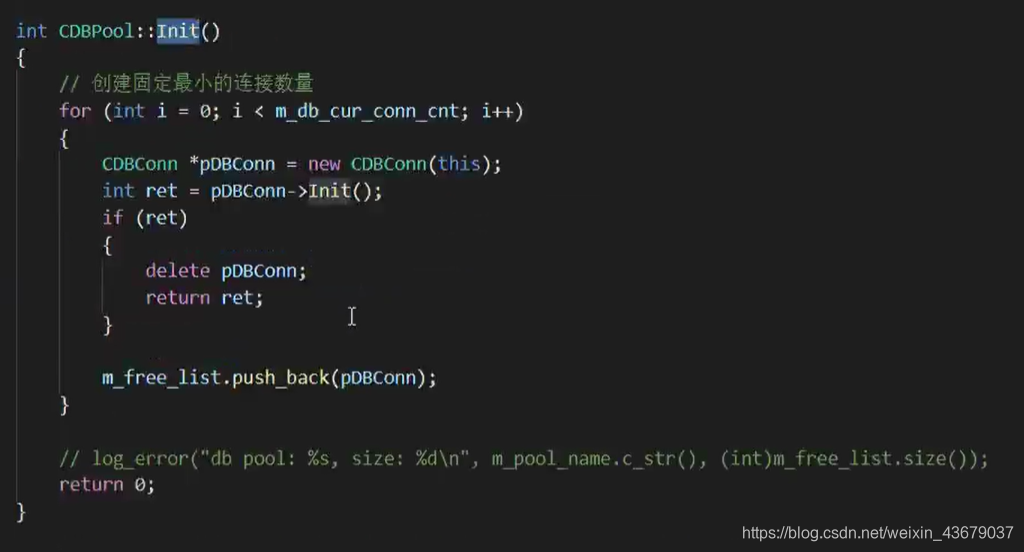
5.1 创建固定最小的连接数量(动态扩容连接池):
-
比如我们支持最大支持10个连接,一开始没必要直接创建10个连接.
-
连接数 = ((核心数 * 2) + 有效磁盘数),可以跑个性能测试看看,我们可以保证,它能轻松支撑 3000 用户以 6000 TPS 的速率并发执行简单查询的场景。你还可以将连接池大小超过 10,那时,你会看到响应时长开始增加,TPS 开始下降。
-
比如先创建2个连接,如果创建过多,则系统启动就慢,但创建后系统的响应速度会很快;如果创建过少,则系统启动的很快,响应起来却慢。
-
因为一核 CPU 的机器上,顺序执行A和B永远比通过时间分片切换“同时”执行A和B要快,其中原因,学过操作系统这门课程的童鞋应该很清楚。一旦线程的数量超过了 CPU 核心的数量,再增加线程数系统就只会更慢,而不是更快,因为这里涉及到上下文切换耗费的额外的性能。
-
如何确保连接池中的最小连接数呢?有动态和静态两种策略。动态即每隔一定时间就对连接池进行检测,如果发现连接数量小于最小连接数,则补充相应数量的新连接以保证连接池的正常运转。静态是发现空闲连接不够时再去检查。
5.2 进一步的设计:连接超时计算
- 获取连接超时,增加统计计数,发掘服务器性能的瓶颈在哪里
int m_get_conn_timeout_cnt = 0;
if(m_free_list.empty())
{
m_get_conn_timeout_cnt++; //统计超时的计时
return NULL;
}
- 长时间没有归还,每隔一段时间计算m_used_list的连接是否有长时间没有归还的。
5.3 连接峰值计算
可以看1、5、10秒计算了多少次连接,参考案例阿里的druid 德鲁伊特监控的参数
5.4 连接池的大小的设置还是要结合实际的业务场景来说事。
- 比如说,你的系统同时混合了长事务和短事务,这时,根据上面的公式来计算就很难办了。正确的做法应该是创建两个连接池,一个服务于长事务,一个服务于"实时"查询,也就是短事务。
5.5 还有一种情况,比方说一个系统执行一个任务队列,业务上要求同一时间内只允许执行一定数量的任务,这时,我们就应该让并发任务数去适配连接池连接数,而不是连接数大小去适配并发任务数。
5.6 连接池这也要取决于磁盘
如果你使用的是 SSD 固态硬盘,它不需要寻址,也不需要旋转碟片。打住打住!!!你千万可别理所当然的认为:“既然SSD速度更快,我们把线程数的大小设置的大些吧!!”结论正好相反!无需寻址和没有旋回耗时的确意味着更少的阻塞,所以更少的线程(更接近于CPU核心数)会发挥出更高的性能。只有当阻塞密集时,更多的线程数才能发挥出更好的性能。
5.7 当你的线程处理的是 I/O 密集型业务时,便可以让线程/连接数设置的比 CPU核心大一些,这样就能够在同样的时间内,完成更多的工作,提升吞吐量。
1.网络变成 百万连接
2.群聊天消息 千人群 从内存中拉取 redis,不能从mysql中拉取,效率太慢,微博朋友圈也是从redis中拉取
3.注册账号,走的http,使用nginx
数据库接入普通函数
#include <mysql/mysql.h>
#include <string.h>
#include <stdio.h>
int main(int argc,char* argv[])
{
if(2 != argc)
{
printf("error args\n");
return -1;
}
MYSQL *conn;
MYSQL_RES *res;
MYSQL_ROW row;
char *server = "localhost";
char *user = "root";
char *password = "密码";
char *database = "数据库名";//要访问的数据库名称
char query[300] = "select * from hero where name='";
unsigned int queryRet;
sprintf(query, "%s%s%s", query, argv[1], "'");
/* strcpy(query,"select * from hero"); */
//在输出前先打印查询语句
puts(query);
//初始化
conn = mysql_init(NULL);
if(!conn)
{
printf("MySQL init failed\n");
return -1;
}
//连接数据库,看连接是否成功,只有成功才能进行后面的操作
if(!mysql_real_connect(conn, server, user, password, database, 0, NULL, 0))
{
printf("Error connecting to database: %s\n", mysql_error(conn));
return -1;
}
else
{
printf("MySQL Connected...\n");
}
//把SQL语句传递给MySQL
queryRet = mysql_query(conn, query);
if(queryRet)
{
printf("Error making query: %s\n", mysql_error(conn));
}
else
{
//用mysql_num_rows可以得到查询的结果集有几行
//要配合mysql_store_result使用
//第一种判断方式
res = mysql_store_result(conn);
printf("mysql_num_rows = %lu\n", (unsigned long)mysql_num_rows(res));
//第二种判断方式,两种方式不能一起使用
/* res = mysql_use_result(conn); */
row = mysql_fetch_row(res);
if(NULL == row)
{
printf("Don't find any data\n");
}
else
{
do
{
/* printf("num=%d\n",mysql_num_fields(res));//列数 */
//每次for循环打印一整行的内容
for(queryRet = 0; queryRet < mysql_num_fields(res); ++queryRet)
{
printf("%8s ", row[queryRet]);
}
printf("\n");
}while(NULL != (row = mysql_fetch_row(res)));
}
mysql_free_result(res);
}
mysql_close(conn);
return 0;
}
6.连接池配合线程池代码(redis)
test_ThreadPool.cpp
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <signal.h>
#include <setjmp.h>
#include <stdarg.h>
#include <sys/time.h>
#include <unistd.h>
#include <sstream>
#include "threadpool.h"
#include "CachePool.h"
using namespace std;
#define TASK_NUMBER 10000
#define DB_HOST_IP "127.0.0.1" // 数据库服务器ip
#define DB_HOST_PORT 6379
#define DB_INDEX 0 // redis默认支持16个db
#define DB_PASSWORD "" // 数据库密码,不设置AUTH时该参数为空
#define DB_POOL_NAME "redis_pool" // 连接池的名字,便于将多个连接池集中管理
#define DB_POOL_MAX_CON 4
struct threadpool *threadpool_init(int thread_num, int queue_max_num)
{
struct threadpool *pool = NULL;
do
{
pool = (struct threadpool *)malloc(sizeof(struct threadpool));
if (NULL == pool)
{
printf("failed to malloc threadpool!\n");
break;
}
pool->thread_num = thread_num;
pool->queue_max_num = queue_max_num;
pool->queue_cur_num = 0;
pool->head = NULL;
pool->tail = NULL;
if (pthread_mutex_init(&(pool->mutex), NULL))
{
printf("failed to init mutex!\n");
break;
}
if (pthread_cond_init(&(pool->queue_empty), NULL))
{
printf("failed to init queue_empty!\n");
break;
}
if (pthread_cond_init(&(pool->queue_not_empty), NULL))
{
printf("failed to init queue_not_empty!\n");
break;
}
if (pthread_cond_init(&(pool->queue_not_full), NULL))
{
printf("failed to init queue_not_full!\n");
break;
}
//创建线程池中所有线程的pthread_t
pool->pthreads = (pthread_t *)malloc(sizeof(pthread_t) * thread_num);
if (NULL == pool->pthreads)
{
printf("failed to malloc pthreads!\n");
break;
}
pool->queue_close = 0;
pool->pool_close = 0;
int i;
for (i = 0; i < pool->thread_num; ++i)
{
pthread_create(&(pool->pthreads[i]), NULL, threadpool_function, (void *)pool);
}
return pool;
} while (0);
return NULL;
}
int threadpool_add_job(struct threadpool *pool, void *(*callback_function)(void *arg), void *arg)
{
//1.判断额外条件
assert(pool != NULL); //pool不为空,如果Pool为空就报错
assert(callback_function != NULL); //
assert(arg != NULL);
//2.加锁判断队列是否满了
pthread_mutex_lock(&(pool->mutex));
while ((pool->queue_cur_num == pool->queue_max_num) && !(pool->queue_close || pool->pool_close))
{
pthread_cond_wait(&(pool->queue_not_full), &(pool->mutex)); //队列满的时候就等待
}
if (pool->queue_close || pool->pool_close) //队列关闭或者线程池关闭就退出
{
pthread_mutex_unlock(&(pool->mutex));
return -1;
}
//3.创建任务
struct job *pjob = (struct job *)malloc(sizeof(struct job));
if (NULL == pjob)
{
pthread_mutex_unlock(&(pool->mutex));
return -1;
}
pjob->callback_function = callback_function;
pjob->arg = arg;
pjob->next = NULL;
if (pool->head == NULL)
{
pool->head = pool->tail = pjob;
pthread_cond_broadcast(&(pool->queue_not_empty)); //队列空的时候,有任务来时就通知线程池中的线程:队列非空
}
else
{
pool->tail->next = pjob;
pool->tail = pjob;
}
pool->queue_cur_num++;
pthread_mutex_unlock(&(pool->mutex));
return 0;
}
static uint64_t get_tick_count()
{
struct timeval tval;
uint64_t ret_tick;
gettimeofday(&tval, NULL);
ret_tick = tval.tv_sec * 1000L + tval.tv_usec / 1000L;
return ret_tick;
}
void *threadpool_function(void *arg)
{
struct threadpool *pool = (struct threadpool *)arg;
struct job *pjob = NULL;
//起始事件
uint64_t start_time = get_tick_count();
//结束事件
uint64_t end_time = get_tick_count();
while (1) //死循环
{
pthread_mutex_lock(&(pool->mutex));
while ((pool->queue_cur_num == 0) && !pool->pool_close) //队列为空时,就等待队列非空
{
end_time = get_tick_count();
printf("threadpool need time:%lums\n", end_time - start_time);
pthread_cond_wait(&(pool->queue_not_empty), &(pool->mutex));
}
if (pool->pool_close) //线程池关闭,线程就退出
{
pthread_mutex_unlock(&(pool->mutex));
pthread_exit(NULL);
}
pool->queue_cur_num--;
pjob = pool->head;
if (pool->queue_cur_num == 0)
{
pool->head = pool->tail = NULL;
}
else
{
pool->head = pjob->next;
}
if (pool->queue_cur_num == 0)
{
pthread_cond_signal(&(pool->queue_empty)); //队列为空,就可以通知threadpool_destroy函数,销毁线程函数
}
if (pool->queue_cur_num == pool->queue_max_num - 1)
{
pthread_cond_broadcast(&(pool->queue_not_full)); //队列非满,就可以通知threadpool_add_job函数,添加新任务
}
pthread_mutex_unlock(&(pool->mutex));
(*(pjob->callback_function))(pjob->arg); //线程真正要做的工作,回调函数的调用
free(pjob);
pjob = NULL;
}
}
int threadpool_destroy(struct threadpool *pool)
{
assert(pool != NULL);
pthread_mutex_lock(&(pool->mutex));
if (pool->queue_close || pool->pool_close) //线程池已经退出了,就直接返回
{
pthread_mutex_unlock(&(pool->mutex));
return -1;
}
pool->queue_close = 1; //置队列关闭标志
while (pool->queue_cur_num != 0)
{
pthread_cond_wait(&(pool->queue_empty), &(pool->mutex)); //等待队列为空
}
pool->pool_close = 1; //置线程池关闭标志
pthread_mutex_unlock(&(pool->mutex));
pthread_cond_broadcast(&(pool->queue_not_empty)); //唤醒线程池中正在阻塞的线程
pthread_cond_broadcast(&(pool->queue_not_full)); //唤醒添加任务的threadpool_add_job函数
int i;
for (i = 0; i < pool->thread_num; ++i)
{
pthread_join(pool->pthreads[i], NULL); //等待线程池的所有线程执行完毕
}
pthread_mutex_destroy(&(pool->mutex)); //清理资源
pthread_cond_destroy(&(pool->queue_empty));
pthread_cond_destroy(&(pool->queue_not_empty));
pthread_cond_destroy(&(pool->queue_not_full));
free(pool->pthreads);
struct job *p;
while (pool->head != NULL)
{
p = pool->head;
pool->head = p->next;
free(p);
}
free(pool);
return 0;
}
// #define random(x) (rand()%x)
static string int2string(uint32_t user_id)
{
stringstream ss;
ss << user_id;
return ss.str();
}
void *workUsePool(void *arg)
{
CachePool *pCachePool = (CachePool *)arg;
CacheConn *pCacheConn = pCachePool->GetCacheConn();
int count = rand() % TASK_NUMBER;
string key = "user:" + int2string(count);
string name = "liaoqingfu-" + int2string(count);
pCacheConn->set(key, name);
pCachePool->RelCacheConn(pCacheConn);
return NULL;
}
void *workNoPool(void *arg)
{
CacheConn *pCacheConn = new CacheConn(DB_HOST_IP, DB_HOST_PORT, DB_INDEX, DB_PASSWORD);
int count = rand() % TASK_NUMBER;
string key = "user:" + int2string(count);
string name = "liaoqingfu-" + int2string(count);
pCacheConn->set(key, name);
delete pCacheConn;
return NULL;
}
int main(int argc, char *argv[])
{
//1.设置数据库参数
int thread_num = 1; // 线程池线程数量
int db_maxconncnt = 4; // 连接池最大连接数量(核数*2 + 磁盘数量)
int use_pool = 1; // 是否使用连接池
if (argc != 4)
{
printf("usage: ./test_ThreadPool thread_num db_maxconncnt use_pool\n \
example: ./test_ThreadPool 4 4 1");
return 1;
}
thread_num = atoi(argv[1]);
db_maxconncnt = atoi(argv[2]);
use_pool = atoi(argv[3]);
const char *pool_name = DB_POOL_NAME; //池的名字
const char *host = DB_HOST_IP; //IP
uint16_t port = DB_HOST_PORT; //端口号
const char *password = DB_PASSWORD; //密码
int db_index = DB_INDEX; //表示第几个数据库
//2.创建缓存数据库连接池
CachePool *pCachePool = new CachePool(pool_name, host, port, 0, password, db_maxconncnt);
if (pCachePool->Init())//连接池初始化,然后创建连接池的连接
{
printf("Init cache pool failed\n");
return -1;
}
//3.获取连接池的连接
CacheConn *pCacheConn = pCachePool->GetCacheConn();
pCacheConn->flushdb();
pCachePool->RelCacheConn(pCacheConn);
//4.创建线程池
printf("thread_num = %d, connection_num:%d, use_pool:%d\n",
thread_num, db_maxconncnt, use_pool);
struct threadpool *pool = threadpool_init(thread_num, TASK_NUMBER);
//5.从任务队列取出任务,然后
for (int i = 0; i < TASK_NUMBER; i++)
{
//取出任务然后进行执行
if (use_pool)
{
threadpool_add_job(pool, workUsePool, (void *)pCachePool);
}
else
{
threadpool_add_job(pool, workNoPool, (void *)pCachePool);
}
}
while(pool->queue_cur_num !=0 ) // 判断队列是否还有任务
{
sleep(1); // 还有任务主线程继续休眠
}
sleep(2); // 没有任务要处理了休眠2秒退出,这里等待主要是确保所有线程都已经空闲
threadpool_destroy(pool);
delete pCachePool;
return 0;
}
threadpool.h
#include <pthread.h>
struct job
{
void* (*callback_function)(void *arg); //线程回调函数
void *arg; //回调函数参数
struct job *next;
};
struct threadpool
{
int thread_num; //线程池中开启线程的个数
int queue_max_num; //队列中最大job的个数
struct job *head; //指向job的头指针
struct job *tail; //指向job的尾指针
pthread_t *pthreads; //线程池中所有线程的pthread_t
pthread_mutex_t mutex; //互斥信号量
pthread_cond_t queue_empty; //队列为空的条件变量
pthread_cond_t queue_not_empty; //队列不为空的条件变量
pthread_cond_t queue_not_full; //队列不为满的条件变量
int queue_cur_num; //队列当前的job个数
int queue_close; //队列是否已经关闭
int pool_close; //线程池是否已经关闭
};
//1.初始化线程池
//================================================================================================
//函数名: threadpool_init
//函数描述: 初始化线程池
//输入: [in] thread_num 线程池开启的线程个数
// [in] queue_max_num 队列的最大job个数
//输出: 无
//返回: 成功:线程池地址 失败:NULL
//================================================================================================
struct threadpool* threadpool_init(int thread_num, int queue_max_num);
//2.向线程池中增加任务
//================================================================================================
//函数名: threadpool_add_job
//函数描述: 向线程池中添加任务
//输入: [in] pool 线程池地址
// [in] callback_function 回调函数
// [in] arg 回调函数参数
//输出: 无
//返回: 成功:0 失败:-1
//================================================================================================
int threadpool_add_job(struct threadpool *pool, void* (*callback_function)(void *arg), void *arg);
//3.销毁线程池
//================================================================================================
//函数名: threadpool_destroy
//函数描述: 销毁线程池
//输入: [in] pool 线程池地址
//输出: 无
//返回: 成功:0 失败:-1
//================================================================================================
int threadpool_destroy(struct threadpool *pool);
//4.线程池中线程函数
//================================================================================================
//函数名: threadpool_function
//函数描述: 线程池中线程函数
//输入: [in] arg 线程池地址
//输出: 无
//返回: 无
//================================================================================================
void* threadpool_function(void* arg);
CachePool.cpp
#include <pthread.h>
struct job
{
void* (*callback_function)(void *arg); //线程回调函数
void *arg; //回调函数参数
struct job *next;
};
struct threadpool
{
int thread_num; //线程池中开启线程的个数
int queue_max_num; //队列中最大job的个数
struct job *head; //指向job的头指针
struct job *tail; //指向job的尾指针
pthread_t *pthreads; //线程池中所有线程的pthread_t
pthread_mutex_t mutex; //互斥信号量
pthread_cond_t queue_empty; //队列为空的条件变量
pthread_cond_t queue_not_empty; //队列不为空的条件变量
pthread_cond_t queue_not_full; //队列不为满的条件变量
int queue_cur_num; //队列当前的job个数
int queue_close; //队列是否已经关闭
int pool_close; //线程池是否已经关闭
};
//1.初始化线程池
//================================================================================================
//函数名: threadpool_init
//函数描述: 初始化线程池
//输入: [in] thread_num 线程池开启的线程个数
// [in] queue_max_num 队列的最大job个数
//输出: 无
//返回: 成功:线程池地址 失败:NULL
//================================================================================================
struct threadpool* threadpool_init(int thread_num, int queue_max_num);
//2.向线程池中增加任务
//================================================================================================
//函数名: threadpool_add_job
//函数描述: 向线程池中添加任务
//输入: [in] pool 线程池地址
// [in] callback_function 回调函数
// [in] arg 回调函数参数
//输出: 无
//返回: 成功:0 失败:-1
//================================================================================================
int threadpool_add_job(struct threadpool *pool, void* (*callback_function)(void *arg), void *arg);
//3.销毁线程池
//================================================================================================
//函数名: threadpool_destroy
//函数描述: 销毁线程池
//输入: [in] pool 线程池地址
//输出: 无
//返回: 成功:0 失败:-1
//================================================================================================
int threadpool_destroy(struct threadpool *pool);
//4.线程池中线程函数
//================================================================================================
//函数名: threadpool_function
//函数描述: 线程池中线程函数
//输入: [in] arg 线程池地址
//输出: 无
//返回: 无
//================================================================================================
void* threadpool_function(void* arg);
7、mysql连接池代码设计
总体流程
代码
代码可粗略分为:















 3028
3028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









