







文章目录
一、memtier-benchmark安装步骤
法一
CentOS8.2 64bit环境 安装memtier-benchmark 【2021.04.19测试可用】
法二
memtier_benchmark:一种用于Redis和Memcached的工具环境配置和安装
二、memtier-benchmark测试命令说明及常用测试选项
[root@redis memtier_benchmark]# memtier_benchmark --help
Usage: memtier_benchmark [options]
A memcache/redis NoSQL traffic generator and performance benchmarking tool.
Connection and General Options:
-s, --server=ADDR Server address (default: localhost)
-p, --port=PORT Server port (default: 6379)
-S, --unix-socket=SOCKET UNIX Domain socket name (default: none)
-P, --protocol=PROTOCOL Protocol to use (default: redis). Other
supported protocols are memcache_text,
memcache_binary.
-a, --authenticate=CREDENTIALS Authenticate using specified credentials.
A simple password is used for memcache_text
and Redis <= 5.x. <USER>:<PASSWORD> can be
specified for memcache_binary or Redis 6.x
or newer with ACL user support.
--tls Enable SSL/TLS transport security
--cert=FILE Use specified client certificate for TLS
--key=FILE Use specified private key for TLS
--cacert=FILE Use specified CA certs bundle for TLS
--tls-skip-verify Skip verification of server certificate
--sni=STRING Add an SNI header
-x, --run-count=NUMBER Number of full-test iterations to perform
-D, --debug Print debug output
--client-stats=FILE Produce per-client stats file
-o, --out-file=FILE Name of output file (default: stdout)
--json-out-file=FILE Name of JSON output file, if not set, will not print to json
--hdr-file-prefix=FILE Prefix of HDR Latency Histogram output files, if not set, will not save latency histogram files
--show-config Print detailed configuration before running
--hide-histogram Don't print detailed latency histogram
--print-percentiles Specify which percentiles info to print on the results table (by default prints percentiles: 50,99,99.9)
--cluster-mode Run client in cluster mode
-h, --help Display this help
-v, --version Display version information
Test Options:
-n, --requests=NUMBER Number of total requests per client (default: 10000)
use 'allkeys' to run on the entire key-range
-c, --clients=NUMBER Number of clients per thread (default: 50)
-t, --threads=NUMBER Number of threads (default: 4)
--test-time=SECS Number of seconds to run the test
--ratio=RATIO Set:Get ratio (default: 1:10)
--pipeline=NUMBER Number of concurrent pipelined requests (default: 1)
--reconnect-interval=NUM Number of requests after which re-connection is performed
--multi-key-get=NUM Enable multi-key get commands, up to NUM keys (default: 0)
--select-db=DB DB number to select, when testing a redis server
--distinct-client-seed Use a different random seed for each client
--randomize random seed based on timestamp (default is constant value)
Arbitrary command:
--command=COMMAND Specify a command to send in quotes.
Each command that you specify is run with its ratio and key-pattern options.
For example: --command="set __key__ 5" --command-ratio=2 --command-key-pattern=G
To use a generated key or object, enter:
__key__: Use key generated from Key Options.
__data__: Use data generated from Object Options.
--command-ratio The number of times the command is sent in sequence.(default: 1)
--command-key-pattern Key pattern for the command (default: R):
G for Gaussian distribution.
R for uniform Random.
S for Sequential.
P for Parallel (Sequential were each client has a subset of the key-range).
Object Options:
-d --data-size=SIZE Object data size (default: 32)
--data-offset=OFFSET Actual size of value will be data-size + data-offset
Will use SETRANGE / GETRANGE (default: 0)
-R --random-data Indicate that data should be randomized
--data-size-range=RANGE Use random-sized items in the specified range (min-max)
--data-size-list=LIST Use sizes from weight list (size1:weight1,..sizeN:weightN)
--data-size-pattern=R|S Use together with data-size-range
when set to R, a random size from the defined data sizes will be used,
when set to S, the defined data sizes will be evenly distributed across
the key range, see --key-maximum (default R)
--expiry-range=RANGE Use random expiry values from the specified range
Imported Data Options:
--data-import=FILE Read object data from file
--data-verify Enable data verification when test is complete
--verify-only Only perform --data-verify, without any other test
--generate-keys Generate keys for imported objects
--no-expiry Ignore expiry information in imported data
Key Options:
--key-prefix=PREFIX Prefix for keys (default: "memtier-")
--key-minimum=NUMBER Key ID minimum value (default: 0)
--key-maximum=NUMBER Key ID maximum value (default: 10000000)
--key-pattern=PATTERN Set:Get pattern (default: R:R)
G for Gaussian distribution.
R for uniform Random.
S for Sequential.
P for Parallel (Sequential were each client has a subset of the key-range).
--key-stddev The standard deviation used in the Gaussian distribution
(default is key range / 6)
--key-median The median point used in the Gaussian distribution
(default is the center of the key range)
WAIT Options:
--wait-ratio=RATIO Set:Wait ratio (default is no WAIT commands - 1:0)
--num-slaves=RANGE WAIT for a random number of slaves in the specified range
--wait-timeout=RANGE WAIT for a random number of milliseconds in the specified range (normal
distribution with the center in the middle of the range)
2.1 连接和通用选项
- -s或–server=ADDR
服务器地址(默认值为localhost: 127.0.0.1) - -p或–port=PORT
服务器端口(默认值为6379)。 - -S或–unix-socket=SOCKET
UNIX域套接字的名称(默认值为none)。 - -P或–protocol=PROTOCOL
使用的协议(默认值为redis)。其他受支持的协议:memcache_text和memcache_binary. - -x或–run-count=NUMBER
完整测试的迭代执行次数。 - -D或–debug
输出调试信息。 - –client-stats=FILE
生成每个客户端的统计文件。 - –out-file=FILE
输出结果文件的名称(默认值为stdout)。 - –show-config
运行基准测试之前,输出详细的配置信息。 - –hide-histogram
不输出详细的延迟柱状图。 - –help
输出帮助信息。 - –version
输出版本信息。
2.2 测试选项
-
-n或–requests=NUMBER
每个客户端发出的请求总数(默认值为10000)。若使用“allkeys”,则基准测试会使用整个测试键的范围。 -
-c或–clients=NUMBER
每个线程驱动的客户端的数量(默认值为50)。 -
-t或–threads=NUMBER
基准测试使用的线程数量(默认值为4)。 -
–test-time=SECS
基准测试的持续时间,以秒为单位。 -
–ratio=RATIO
SET和GET操作的比率(默认值为1:10)。 -
–pipeline=NUMBER
管道请求的并发数量(默认值为1)。 -
–reconnect-interval=NUM
执行重新连接之后的请求数量。 -
–multi-key-get=NUM
使用Redis的MGET命令,这个命令最多可以一次获取NUM个键的值(默认值为0)。 -
-a或–authenticate=CREDENTIALS
登录Redis服务器时使用的凭证。根据使用的协议,可以是PASSWORD或USER:PASSWORD。 -
–select-db=DB
当测试一台Redis服务器时,选择它的DB编号。 -
–distinct-client-seed
每个客户端都使用一个不同的随机数种子。 -
–randomize
基于时间戳的随机数种子(默认为常数值)。
2.3 对象选项
- -d或–data-size=SIZE
对象数据的大小(默认值为32字节) - –data-offset=OFFSET
值的真实大小等于data-size + data-offset。基准测试将会使用Redis的SETRANGE和GETRANGE命令(默认值为0)。 - -R或–random-data
基准测试将会使用随机化的测试数据。 - –data-size-range=RANGE
基准测试使用的测试数据的大小是随机的,数据大小在指定的范围之内(min-max)。 - –data-size-list=LIST
根据权重列表设置测试数据的大小(size1:weight1,…sizeN:weightN)。 - –data-size-pattern=R|S
当这个选项设置为R时,就需要和–data-size-range选项一起使用,测试数据的大小将会在指定的范围之内随机取值。当这个选项设置为S时,定义的测试数据大小将会在测试键的范围之内均匀分布,请参考–key-maximum选项。默认值为R。 - –expiry-range=RANGE
测试键的过期时间是一个随机值,这个随机值在指定的范围之内。
2.4 导入数据选项
- –data-import=FILE
从文件中读取对象数据。 - –data-verify
当基准测试结束时,执行数据验证过程。 - –verify-only
只执行–data-verify选项的数据验证过程,而不会执行其他测试。 - –generate-keys
为导入的对象生成测试键。 - –no-expiry
忽略导入数据中的过期信息。
2.5 测试键选项
-
–key-prefix=PREFIX
测试键的前缀(默认值为“memtier-”)。 -
–key-minimum=NUMBER
测试键ID的最小值(默认值为0)。 -
–key-maximum=NUMBER
测试键ID的最大值(默认值为10000000)。 -
SET和GET操作的访问模式(默认值为R:R)。可以取以下值:
G:高斯分布;
R:均匀随机;
S:连续访问;
P:并行访问(在连续访问模式中,每个客户端都具有测试键范围的一个子集)。
- –key-stddev
高斯分布使用的标准偏差(默认值为测试键范围的1/6)。 - –key-median
高斯分布使用的期望值(默认值为测试键范围的中心值)。
2.6 等待选项
- –wait-ratio=RATIO
SET和WAIT操作的比率(默认不使用WAIT命令,默认值为1:0)。 - –num-slaves=RANGE
等待指定范围之内的随机数量的从机作出应答。 - –wait-timeout=RANGE
等待指定范围之内的时间,单位为毫秒(正太分布的中心值在这个范围的中间)。
三、伪随机数据、高斯访问模式和范围操作
3.1 伪随机数据
- memtier_benchmark基准测试工具能够生成随机化的测试数据,而数据大小则取决于已知的大小范围。
①首先,将–data-size-pattern选项设置为“S”(连续分配);
②然后,通过–data-size-range选项指定随机化的测试数据的大小范围。以下示例将会产生基准测试的键空间,其中的测试数据的大小将会在4字节至204字节之间均匀取值:
memtier-benchmark --random-data --data-size-range=4-204 --data-size-pattern=S --key-minimum=200 --key-maximum=400 <additional parameters>
- 在上文的示例中:
①我们已经使用–random-data选项来生成随机数据了;
②除此之外,我们还使用–key-minimum和–key-maximum选项来控制测试键ID的取值范围,总共产生200个测试键。第一个测试键,memtier-200,将会持有4字节的数据;下一个测试键,将会持有5字节的数据;以此类推,直到最后一个测试键,memtier-400,将会持有204字节的数据。
3.2 高斯访问模式(也叫正态分布)
- memtier_benchmark基准测试工具能够使用高斯分布(也叫做正态分布)来访问测试数据。在支持高斯访问模式之前,你可以将基准测试的访问模式设置为均匀随机分布或连续分布。但是,为了更好的模拟真实用例,你可以使用这个新的选项,确保memtier_benchmark的测试键访问模式符合常见的高斯分布的钟型曲线。当使用高斯分布时,你还可以控制和设置标准偏差和期望值,它们是高斯分布的关键参数。例如,你可以通过以下参数调用这个基准测试工具:
memtier-benchmark --random-data --data-size-range=4-204 --data-size-pattern=S --key-minimum=200 --key-maximum=400 --key-pattern=G:G --key-stddev=10 --key-median=300 <additional parameters>
- 上述调用方式会将大部分的读/写访问集中在第100个(memtier-300)测试键上。
3.3 范围操作
- memtier-benchmark基准测试工具支持Redis的SETRANGE和GETRANGE命令,可用于代替SET和GET命令。这个功能使得你在进行基准测试时,能够明显降低网络流量的消耗,同时你仍然可以使用较大的测试数据。例如,你可以将测试键的值的大小设置为1MB,但是只会读取和写入最后一个字节,你可以通过以下参数调用这个基准测试工具:
memtier-benchmark --data-offset=1048575 --data-size=1 <additional parameters>
四、测试用例展示
4.1 定制测试
./memtier_benchmark -s r-XXXX.redis.rds.aliyuncs.com -p 6379 -a XXX -c 20 -d 32 --threads=10 --ratio=1:1 --test-time=1800 --select-db=10
//memtier_benchmark -s {IP} -n {nreqs} -c {connect_number} -t 4 -d {datasize}
-
-s Redis数据库的连接地址
–server=ADDR Server address (default: localhost) -
-a Redis数据库的密码
-authenticate=CREDENTIALS -
-c 测试中模拟连接的客户端数量
-
-d 测试使用的对象数据的大小
-
–threads 测试中使用的线程数
-
–ratio 测试命令的读写比率(SET:GET Ratio)
-
–test-time 测试时长(单位:秒)
-
–select-db 测试使用的DB数量
4.2 快速测试
memtier_benchmark
4.3 集群测试
memtier_benchmark --cluster-mode -s {IP} -n {nreqs} -c {connect_number} -t 4 -d {datasize}
- QPS: 即Query Per Second,表示数据库每秒执行的命令数。
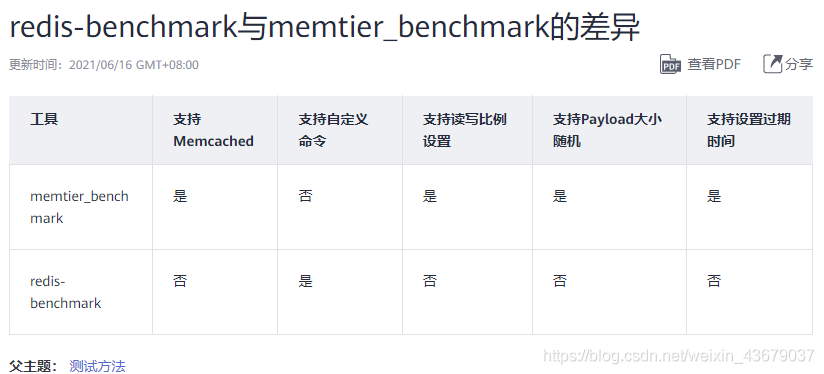
五、redis-benchmark和memtier_benchmark的差异

















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









