







文章目录
- 一、ucontext函数及定义说明
- 二、测试代码讲解
- 三、协程头文件coroutine.h
- 1)代码作用讲解
- ①协程回调函数定义(函数指针)
- ②coroutine_open创建协程调度器
- ③coroutine_close关闭协程调度器
- ④coroutine_new创建协程(返回协程句柄)
- ⑤coroutine_resume协程堆栈恢复
- ⑥coroutine_status和coroutine_running判断协程状态(判断协程yield出去后是否准备resume回来)
- ⑦coroutine_running(struct schedule *)返回调度器状态(-1为未运行)
- ⑧coroutine_yield协程让出CPU占用(yield)
- ⑨_save_stack()
- ⑩入口函数 mainfunc
- 十一、总体API流程执行流程图
- 2)代码实体
- 四、协程函数实现文件coroutine.c
- 五、云凤协程注意点
一、ucontext函数及定义说明
1)相关接口
所有接口函数定义简略说明:
(1)ucontext_t定义
(2)getcontext
(3)makecontext
(4)setcontext
(5)swapcontext
(1)ucontext_t定义和stack_t定义
在5.4的内核中,ucontext_t的定义如下
typedef struct ucontext_t
{
unsigned long int __ctx(uc_flags);
struct ucontext_t* uc_link; //下一个要resume回来继续执行的栈空间,当为空时结束进程
stack_t uc_stack; //栈空间
mcontext_t uc_mcontext; //保存的寄存器信息,saved registers
sigset_t uc_sigmask; //阻塞的信号signals being blocked
struct _libc_fpstate __fpregs_mem;
}ucontext_t;
typedef struct
{
void *ss_sp; //指向的栈
int ss_flags;
size_t ss_size; //栈的大小
} stack_t;
- 字段说明
1)uc_link指的是当前上下文结束后需要执行的上下文,如果设为NULL,则表示当前结束后进程退出;uc_link 是:字段保存当前函数结束后继续执行的函数
2)uc_stack中需要制定协程的栈地址和大小
3)协程实现区别:有栈协程和无栈协程
4)有栈协程:每一个协程都是有自己独立的栈空间
有栈问题:可能这个协程不需要太大的栈空间,造成空间浪费
5)无栈协程:没有独立的栈空间,栈空间都是共享的
6)uc_link 是:字段保存当前函数结束后继续执行的函数;
7)uc_sigmask 是:记录该context运行阶段需要屏蔽的信号;
8)uc_mcontext 是:保存具体的程序执行上下文(如PC值、堆栈指针、寄存器值等信息)其实现方式依赖于底层运行的系统架构,是平台、硬件相关的。
无栈优点:节约内存
(2)getcontext(获取当前上下文)
int getcontext(ucontext_t* ucp);
- 函数说明
该函数用来获取当前线程的执行上下文保存到ucp结构中,保存的堆栈信息后续能被setcontext恢复(restore)再往下执行 - man手册原文
The getcontext() function saves the current thread’s execution context in the structure pointed to by ucp. This saved context may then later be restored by calling setcontext().
(3)makecontext(修改上下文信息)
void makecontext(ucontext_t* ucp,void (*func)(), int argc,...);
void makecontext(ucontext_t *uc, void (*fn)(void), int argc, ...)
{
int i, *sp;
va_list arg;
// 将函数参数陆续设置到r0, r1, r2 .. 等参数寄存器中
sp = (int*)uc->uc_stack.ss_sp + uc->uc_stack.ss_size / 4;
va_start(arg, argc);
for(i=0; i<4 && i<argc; i++)
uc->uc_mcontext.gregs[i] = va_arg(arg, uint);
va_end(arg);
// 设置堆栈指针到sp寄存器
uc->uc_mcontext.gregs[13] = (uint)sp;
// 设置函数指针到lr寄存器,切换时会设置到pc寄存器中进行跳转到fn
uc->uc_mcontext.gregs[14] = (uint)fn;
}
- 函数说明
1)修改ucp的内容,使得下次切换到当前上下文时会调用func()函数。
2)其中
①ucp必须经过getcontext初始化,
②而且必须有个分配的栈
③ucp->uc_lick已被设置,当func()执行完后就会将当前线程上下文切换成其指向的上下文,若为空指针则结束进程
3)argc参数要等于后面的可变参数的参数数量,这些可变参数(必须是int类型)会被传递给func()
(4)setcontext(使用参数ucp中的上下文替换当前线程的上下文到CPU执行,并切换到参数ucp的栈)
int setcontext(const ucontext_t* ucp)
-
函数说明
1)使用ucp中的上下文替换当前线程的上下文,将上下文恢复到CPU中并执行,ucp上下文是由getcontext和makecontext设置而来,或者是作为参数传递给信号处理函数(see sigaction(2))。执行流会发生跳转,这意味着此函数永远不会返回
2)如果ucp经getcontext()初始化,那么程序执行流从getcontext()处返回继续执行。
3)如果ucp经makecontext()初始化,那么会调用makecontext()设置的func,当func执行完后替换上下文为ucp->uc_link指定的上下文。
4)如果ucp被信号处理函数初始化,执行流会从信号打断线程的地方继续往下执行 -
man手册原文
1)The setcontext() function makes a previously saved thread context the current thread context, i.e., the current context is lost and setcontext() does not return. Instead, execution continues in the context specified by ucp, which must have been previously initialized by a call to getcontext(), makecontext(3), or by being passed as an argument to a signal handler (see sigaction(2)).
2)If ucp was initialized by getcontext(), then execution continues as if the original getcontext() call had just returned (again).
3)If ucp was initialized by makecontext(3), execution continues with the invocation of the function specified to makecontext(3). When that function returns, ucp->uc_link determines what happens next: if ucp->uc_link is NULL, the process exits; otherwise, setcontext(ucp->uc_link) is implicitly invoked.
4)If ucp was initialized by the invocation of a signal handler, execution continues at the point the thread was interrupted by the signal.
(5)swapcontext(保存并切换)
int swapcontext(ucontext_t* oucp,ucontext_t* ucp);
-
函数说明
该函数把当前线程上下文保存在oucp,并用ucp替换当前上下文 -
man手册原文
The swapcontext() function saves the current thread context in *oucp and makes *ucp the currently active context.
(6)func的参数只能是int类型(原因解释)
- 总结
随着 ISO/IEC 9899:1999 标准并入本规范,发现 ISO C 标准(子条款 6.11.6)规定使用带空括号的函数声明符已过时。因此,使用函数原型:
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
正在利用 ISO C 标准的过时特性。因此,严格符合 POSIX 的应用程序不能使用这种形式。因此,getcontext()、makecontext() 和 swapcontext() 的使用被标记为过时。用许多处理各种数量和类型的参数的 ISO C 标准兼容函数替换 makecontext() 将迫使 makecontext() 的所有现有用法都被重写,而几乎没有收益(no gain)。现在很少有应用程序使用 *context() 例程(There are very few applications today that use the *context() routines.)。那些确实使用它们的人几乎总是使用它们来实现协程。通过维护 makecontext() 的 XSH 第 5 版规范,现有应用程序将继续工作,尽管它们不能被归类为严格符合的应用程序。
2)使用案例
例子使用简短说明:
例1:
用getcontext/setcontext实现for循环
例2:
用makecontext/(setcontext/swapcontext)实现函数调用
例3:
ucontext簇函数实现函数循环调用
(1)用getcontext/setcontext实现for循环
- 代码
#include <ucontext.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
void test1()
{
//实现一个for循环
ucontext_t ctx;
getcontext(&ctx);
printf("hello world!\n");
sleep(1);
setcontext(&ctx);
}
int main()
{
test1();
return 0;
}
- 效果

(2)用makecontext/(setcontext/swapcontext)实现函数调用
- 代码
#include <ucontext.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
void test2_1()
{
printf("I am %s \n",__FUNCTION__);
}
void test2()
{
ucontext_t ctx;
getcontext(&ctx);
ctx.uc_stack.ss_sp = new char[1024];//申请栈空间,ss_sp指向申请出来的空间地址
ctx.uc_stack.ss_size = 1024; //申请空间的大小
ctx.uc_link = nullptr;
makecontext(&ctx,test2_1,0);//切换到函数1,传0个参数
setcontext(&ctx); //恢复上下文到CPU执行
printf("I am %s \n",__FUNCTION__); //这句话没有打印,因为uc_link为空
return;
}
int main()
{
test2();
return 0;
}
- 效果展示

(3)ucontext簇函数实现函数循环调用
- 代码展示
#include <ucontext.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
static ucontext_t ctx1,ctx2;
void test3_1()
{
printf(" I AM %s\n",__FUNCTION__);
sleep(1);
setcontext(&ctx2); //切换到ctx2
}
void test3_2()
{
printf(" I AM %s\n",__FUNCTION__);
sleep(1);
setcontext(&ctx1);//切换到ctx1
}
void test3()
{
getcontext(&ctx1);
getcontext(&ctx2);
ctx1.uc_stack.ss_sp = new char[1024];
ctx1.uc_stack.ss_size = 1024;
ctx1.uc_link = &ctx2;
makecontext(&ctx1,test3_1,0); //绑定函数
ctx2.uc_stack.ss_sp = new char[1024];
ctx2.uc_stack.ss_size = 1024;
ctx2.uc_link = &ctx1;
makecontext(&ctx2,test3_2,0); //绑定函数
setcontext(&ctx1); //切换到ctx1
return;
}
int main()
{
test3();
return 0;
}
- 效果
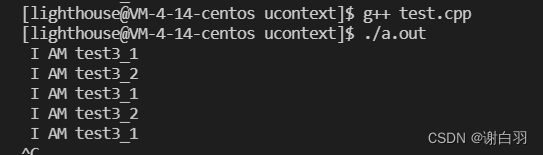
(4)swapcontext顺序遍历两个协程栈
- 代码
#include <iostream>
#include <ucontext.h>
using namespace std;
// ctx[0] <-> main
// ctx[1] <-> f1
// ctx[2] <-> f2
ucontext_t ctx[3];
using ucfunc_t = void(*)(void);
static void f1(int p) {
printf("start f1 of %d\n", p);
swapcontext(&ctx[1], &ctx[2]);//3,这里切到之前保存的ctx[2]栈帧的上下文信息
puts("finish f1");//5,第二次从f2切到这里,打印这句话,然后根据ctx[1].uc_link = &ctx[0];切到main函数
}
static void f2(int p) {
printf("start f2 of %d\n", p);
swapcontext(&ctx[2], &ctx[1]);//2,这里切到ctx[1]绑定的函数f1(1),传入参数为1
puts("finish f2");//4,从f1(1)切回来的,打印这句话,在根据之前 ctx[2].uc_link = &ctx[1];切到ctx[1]绑定的函数
}
int main() {
cout << "main begin" << endl;
char stk1[8192];
char stk2[8192];
getcontext(&ctx[1]);
ctx[1].uc_link = &ctx[0];
ctx[1].uc_stack.ss_sp = stk1;
ctx[1].uc_stack.ss_size = sizeof stk1;
makecontext(&ctx[1], (ucfunc_t)f1, 1, 1);
getcontext(&ctx[2]);
ctx[2].uc_link = &ctx[1];
ctx[2].uc_stack.ss_sp = stk2;
ctx[2].uc_stack.ss_size = sizeof stk2;
makecontext(&ctx[2], (ucfunc_t)f2, 1, 2);
// 执行流:main.1 -> f2.1 -> f1.1 -> f2.2 -> f1.2 -> main.2
swapcontext(&ctx[0], &ctx[2]);//1,这里切到f2(1),传入参数为1
cout << "main end" << endl;//6,从f1切到这里
}
- 执行结果
main begin
start f2 of 2
start f1 of 1
finish f2
finish f1
main end
二、测试代码讲解
1)main函数主流程
1)创建调度器
struct schedule * S = coroutine_open();
首先调用coroutine_open()创建一个schedule,一个schedule是一个执行上下文,所有要执行的协程都要在schedule的栈环境下运行。
2)用函数test()来测试调度器
(1)创建协程并yield
调用coroutine_new()创建了两个coroutine对象,它们各自代表一个可调度的协程实体。
int co1 = coroutine_new(S, foo, &arg1);
int co2 = coroutine_new(S, foo, &arg2);
(2)开启协程并按顺序resume恢复堆栈信息回来
在while循环中,只要两个协程都未结束(coroutine_status()仅在协程终止时返回0),就依次调用coroutine_resume()唤醒它们
while (coroutine_status(S,co1) && coroutine_status(S,co2)) {
coroutine_resume(S,co1);
coroutine_resume(S,co2);
}
(3)在foo调用函数中
协程函数体foo()内部,在有限循环中执行printf任务后调用yield(),让出执行流
static void foo(struct schedule *S, void *ud) {
struct args *arg = ud;
int start = arg->n;
int i;
for (i = 0; i < 5; i++) {
printf("coroutine %d : %d\n", coroutine_running(S), start + i);
coroutine_yield(S);
}
}
(4)关闭调度器
coroutine_close(S);
2)main测试代码示例
#include "coroutine.h"
#include <stdio.h>
struct args {
int n;
};
static void
foo(struct schedule * S, void *ud) {
struct args * arg = ud;
int start = arg->n;
int i;
for (i=0;i<5;i++) {
printf("coroutine %d : %d\n",coroutine_running(S) , start + i);
coroutine_yield(S);
}
}
static void
test(struct schedule *S) {
struct args arg1 = { 0 };
struct args arg2 = { 100 };
int co1 = coroutine_new(S, foo, &arg1);
int co2 = coroutine_new(S, foo, &arg2);
printf("main start\n");
while (coroutine_status(S,co1) && coroutine_status(S,co2)) {
coroutine_resume(S,co1);
coroutine_resume(S,co2);
}
printf("main end\n");
}
int
main() {
struct schedule * S = coroutine_open();
test(S);
coroutine_close(S);
return 0;
}
三、协程头文件coroutine.h
1)代码作用讲解
①协程回调函数定义(函数指针)
typedef void (*coroutine_func)(struct schedule *, void *ud);
②coroutine_open创建协程调度器
struct schedule * coroutine_open(void);
struct schedule *coroutine_open(void) {
struct schedule *S = malloc(sizeof(*S)); //分配内存
S->nco = 0; //一开始管理的协程数量是0
S->cap = DEFAULT_COROUTINE;//可以承载的coroutine数量为DEFAULT_COROUTINE即16
S->running = -1; //-1表示未运行
S->co = malloc(sizeof(struct coroutine *) * S->cap);//给管理的协程指针分配内存
memset(S->co, 0, sizeof(struct coroutine *) * S->cap);
return S;
}

③coroutine_close关闭协程调度器
void coroutine_close(struct schedule *);
void _co_delete(struct coroutine *co) {
free(co->stack); //释放栈空间
free(co); //释放整个协程
}
void coroutine_close(struct schedule *S) {
int i;
//遍历所有协程结构体,一一释放空间
for (i = 0; i < S->cap; i++) {
struct coroutine *co = S->co[i];
if (co) {
_co_delete(co);
}
}
//释放协程指针数组并置空
free(S->co);
S->co = NULL;
free(S);
}

④coroutine_new创建协程(返回协程句柄)
创建一个新的coroutine对象并且把它注册到schedule中,如果schedule没有足够的容量还要先进行扩容
int coroutine_new(struct schedule *, coroutine_func, void *ud);
int coroutine_new(struct schedule *S, coroutine_func func, void *ud) {
struct coroutine *co = _co_new(S, func, ud);
if (S->nco >= S->cap) { //(若满了) S->co空间不足时2倍扩容
int id = S->cap;
S->co = realloc(S->co, S->cap * 2 * sizeof(struct coroutine *));
memset(S->co + S->cap, 0, sizeof(struct coroutine *) * S->cap);
S->co[S->cap] = co;
S->cap *= 2; //管理的协程数量容量翻倍
++S->nco; //管理的协程数量加1
return id;
} else {
int i;
for (i = 0; i < S->cap; i++) {
int id = (i + S->nco) % S->cap; // trick: 优先使用(nco, cap)区间的协程控制块(它们更可能是空闲的)
if (S->co[id] == NULL) {
S->co[id] = co;
++S->nco;
return id; // 返回协程id,这也是用户操纵指定协程的句柄
}
}
}
assert(0);
return -1;
}
struct coroutine *_co_new(struct schedule *S, coroutine_func func, void *ud) {
struct coroutine *co = malloc(sizeof(*co)); //分配指针空间
co->func = func; //安装上回调函数
co->ud = ud; //传递给函数的参数
co->sch = S; //按上协程调度器指针
co->cap = 0; //协程栈容量先置为0
co->size = 0; //协程还没开始使用栈,使用量为0
co->status = COROUTINE_READY; //刚刚创建好,已就绪
co->stack = NULL; // 刚刚创建协程时不分配栈空间
return co;
}

⑤coroutine_resume协程堆栈恢复
void coroutine_resume(struct schedule *, int id);
void coroutine_resume(struct schedule *S, int id) {
assert(S->running == -1); //确保当前调度器是未运行的
assert(id >= 0 && id < S->cap); //确保调度的协程是在结构体指针里面
struct coroutine *C = S->co[id];
if (C == NULL)
return;
int status = C->status;
switch (status) {
case COROUTINE_READY: // 协程第一次resume时获取上下文并设置共享栈为S->stack.
getcontext(&C->ctx); //获取当前线程的上下文信息放到协程的ucontext_t上下文信息里面
C->ctx.uc_stack.ss_sp = S->stack; //S->stack是该协程分配的栈空间首地址
C->ctx.uc_stack.ss_size = STACK_SIZE; //填写分配栈空间的大小
C->ctx.uc_link = &S->main; // 协程执行结束/挂起后返回至此函数尾(然后return),该协程执行结束后返回到main函数
S->running = id; //表示调度器正在执行id号的协程,不是空闲状态
C->status = COROUTINE_RUNNING;//改变协程状态
uintptr_t ptr = (uintptr_t) S;
makecontext(&C->ctx, (void (*)(void)) mainfunc, 2, (uint32_t) ptr, (uint32_t) (ptr >> 32));//给这个协程传递参数和回调函数,传递调度器
swapcontext(&S->main, &C->ctx); // 调用mainfunc,运行在共享栈S->stack上,
//切换到ctx这个协程上指定对应的函数,保存当前上下文信息到调度器
break;
case COROUTINE_SUSPEND: //挂起,如果这不是第一次resume(),那么将协程自身保存的栈内容复制到共享栈中,设置状态为RUNNING
memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size); // 拷贝协程栈到共享栈(在yield的时候,协程的栈内容保存到了C->stack数组中。 这个时候,就是用memcpy把协程的之前保存的栈内容(堆分配的空间),重新拷贝到运行时栈里面。)
S->running = id;
C->status = COROUTINE_RUNNING;
swapcontext(&S->main, &C->ctx); // 调用mainfunc,运行在共享栈S->stack上
//切换到ctx这个协程上指定对应的函数,保存当前上下文信息到调度器
break;
default:
assert(0);
}
}
- mainfunc函数做的事
static void mainfunc(uint32_t low32, uint32_t hi32) {
uintptr_t ptr = (uintptr_t) low32 | ((uintptr_t) hi32 << 32);
// 组合两个uint32_t拿到struct schedule*指针,此做法兼容32位/64位指针
struct schedule *S = (struct schedule *) ptr;
int id = S->running;
struct coroutine *C = S->co[id]; // 拿到要执行的协程的指针
C->func(S, C->ud); // 实际执行协程函数,内部可能会调用coroutine_yield,所以可能不会立即返回
_co_delete(C); // 一旦返回就说明此协程的函数return了,整个协程执行完毕,销回之
S->co[id] = NULL;
--S->nco;
S->running = -1;
}
⑥coroutine_status和coroutine_running判断协程状态(判断协程yield出去后是否准备resume回来)
int coroutine_status(struct schedule *, int id);
int coroutine_status(struct schedule *S, int id) {
assert(id >= 0 && id < S->cap);
if (S->co[id] == NULL) {
return COROUTINE_DEAD;
}
return S->co[id]->status; //那四个枚举的状态
}
int coroutine_running(struct schedule *S) {
return S->running;
}
⑦coroutine_running(struct schedule *)返回调度器状态(-1为未运行)
int coroutine_running(struct schedule *);
⑧coroutine_yield协程让出CPU占用(yield)
void coroutine_yield(struct schedule *);
void coroutine_yield(struct schedule *S)
{
int id = S->running;
assert(id >= 0);
struct coroutine *C = S->co[id];
assert((char *) &C > S->stack);
_save_stack(C, S->stack + STACK_SIZE); // 保存共享栈S->stack到当前协程的栈C->stack
C->status = COROUTINE_SUSPEND;
S->running = -1;
swapcontext(&C->ctx, &S->main); // 返回coroutine_resume函数尾(然后return)
}
- 最后swapcontext的作用
1)通过前面对coroutine_resume()的分析我们知道S->main始终代表coroutine_resume()函数尾处的上下文,所以这里执行流将会”跳转“到coroutine_resume()函数尾,紧接着返回到coroutine_resume()的调用方。
2)对一个已经调用过coroutine_yield()的协程,其C->ctx保存的是coroutine_yield()结尾处的上下文,所以当它再次被调用coroutine_resume()时,执行流将跳转到此处并返回到该协程的主体函数中,从coroutine_yield()调用处继续向下执行。
⑨_save_stack()
static void _save_stack(struct coroutine *C, const char *top) {
// trick: 因为协程C运行在S->stack中,所以栈上对象dummy也位于S->stack中
// [&dummy, top) 就是执行到目前为止整个协程所使用的栈空间,所以保存协程栈时就不需要保存整个S->stack了
char dummy = 0;
assert(top - &dummy <= STACK_SIZE);
// 如果已分配内存小于当前栈的大小,则释放内存重新分配
if (C->cap < top - &dummy) { // 如果是第一次保存或者协程栈变大了,那么(重)分配C->stack
free(C->stack);
C->cap = top - &dummy;
C->stack = malloc(C->cap);
}
C->size = top - &dummy;
//这里dummy是在栈里面,而c->stack是堆分配出来的,而堆的地址比较低,从高位的栈空间复制到低位的堆空间,不存在拷贝覆盖的情况(拷贝方向都是从低到高地址)
memcpy(C->stack, &dummy, C->size);
}
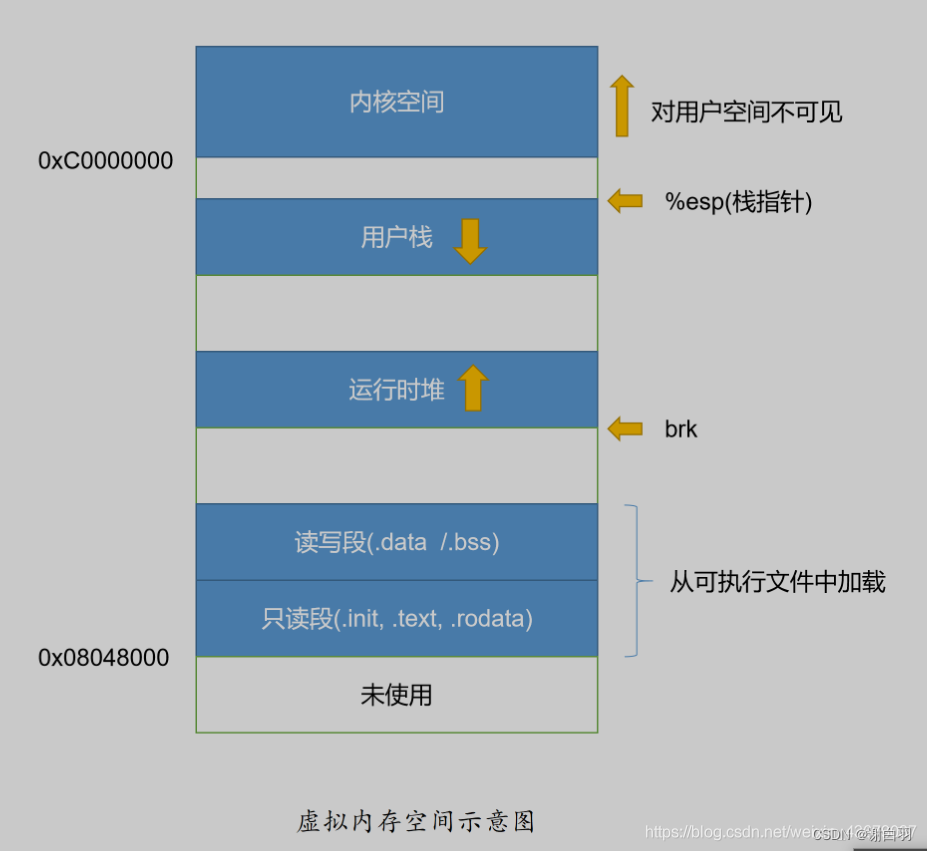
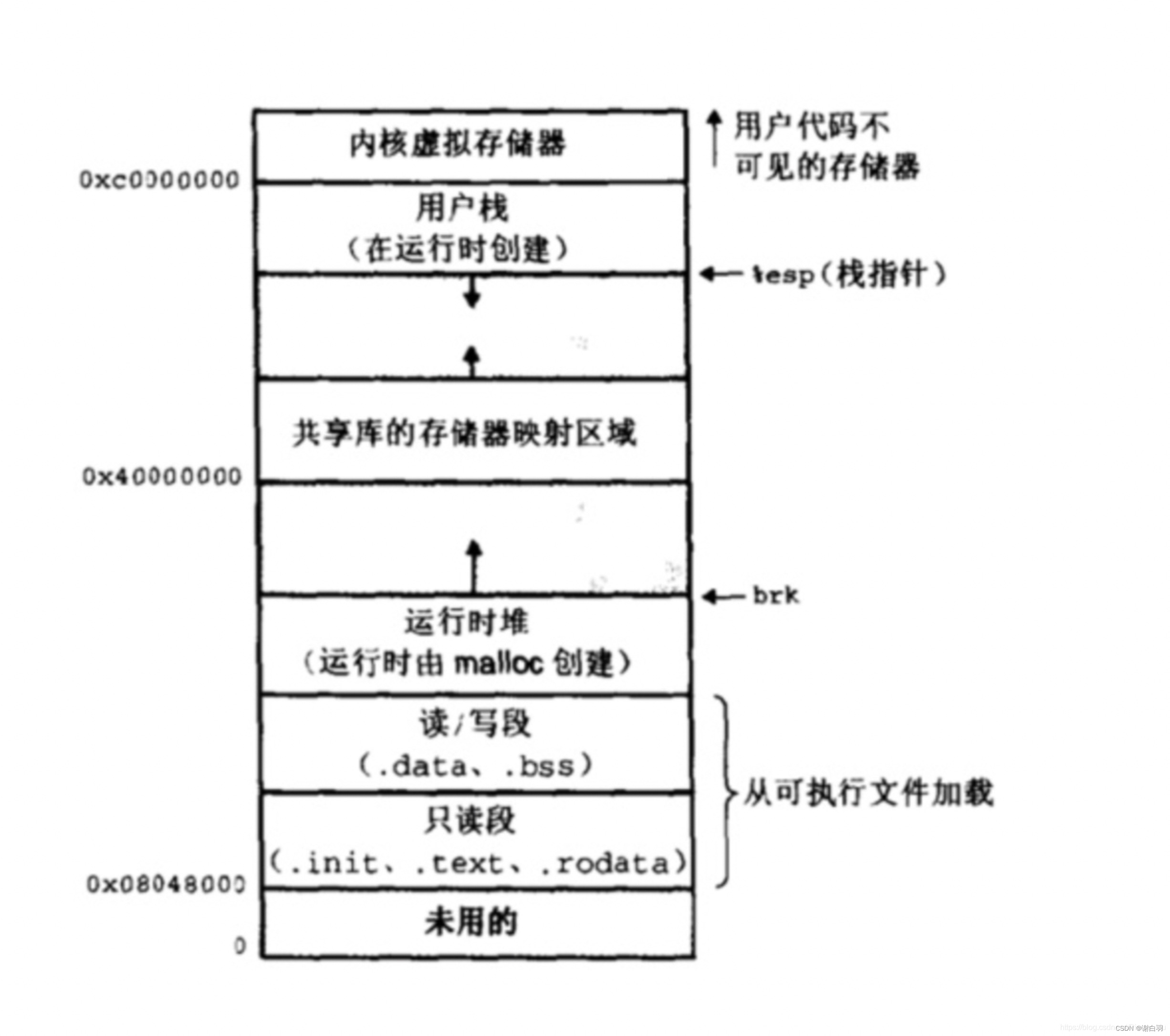
执行到_save_stack函数内部时,backtrace是这样的:(栈的生长方向是高地址到低地址)
┌──────────────────────────────┐
│ stack top *──┐
└──────────────────────────────┘ │
┌──────────────────────────────┐ │
│ previous │ │
│ stack frames │ │
└──────────────────────────────┘ │
┌──────────────────────────────┐ │
│ test() │ │
│ stack frame │ │active
└──────────────────────────────┘ coroutine
┌──────────────────────────────┐ │stack
│ coroutine_resume() │ │
│ stack frame │ │
└──────────────────────────────┘ │
┌──────────────────────────────┐ │
│ (_save_stack() stack frame) │ │
│ ebp of previous stack frame │ │
│ dummy *◀─┘
│ arguments │
│ ... │
└──────────────────────────────┘
- 总结
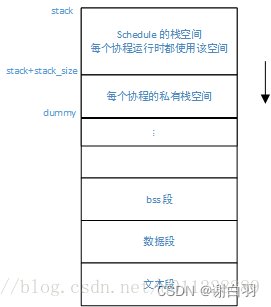
所以_save_stack()中,top - &dummy所代表的就是当前协程活跃的栈空间,而共享栈S->stack固定大小为1024k,当前协程所使用的栈大小一般远小于这个数,所以在协程切换时只保存top - &dummy这一部分而非整个协程栈将极大减少协程的空间开销。 - 换个简单的说法:
这里特意用到了一个dummy变量,这个dummy的作用非常关键也非常巧妙,大家可以细细体会下。因为dummy变量是刚刚分配到栈上的,此时就位于栈的最顶部位置。整个内存布局如下图所示:
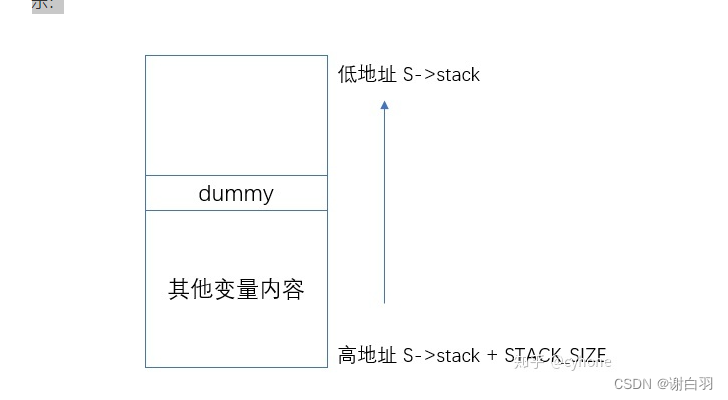
因此整个栈的大小就是从栈底到栈顶,栈容量就是S->stack - &dummy。最后又调用了memcpy将当前运行时栈的内容,拷贝到了C->stack中保存了起来。
⑩入口函数 mainfunc
主要就是传入协程调度器,从而获取正在执行的协程,从而执行对应的回调函数。并在回调函数执行完毕后删除协程,从而宣布此协程执行完毕
static void
mainfunc(uint32_t low32, uint32_t hi32) {
uintptr_t ptr = (uintptr_t)low32 | ((uintptr_t)hi32 << 32);
struct schedule *S = (struct schedule *)ptr;
int id = S->running;
struct coroutine *C = S->co[id];
C->func(S,C->ud);//执行协程的回调函数
_co_delete(C);//执行完毕删除协程
S->co[id] = NULL;
--S->nco;
S->running = -1;
}
- 为什么传递两个int指针(man makecontext)
On architectures where int and pointer types are the same size (e.g., x86-32, where both types are 32 bits), you may be able to get away with passing pointers as arguments to makecontext() following argc. However, doing this is not guaranteed to be portable, is undefined according to the standards, and won’t work on architectures where pointers are larger than ints. Nevertheless, starting with version 2.8, glibc makes some changes to makecontext(3), to permit this on some 64-bit architectures (e.g., x86-64).
这是因为 makecontext 的函数指针的参数是 uint32_t 类型,在 64 位系统下,一个 uint32_t 没法承载一个指针, 所以基于兼容性的考虑,才采用了这种做法。
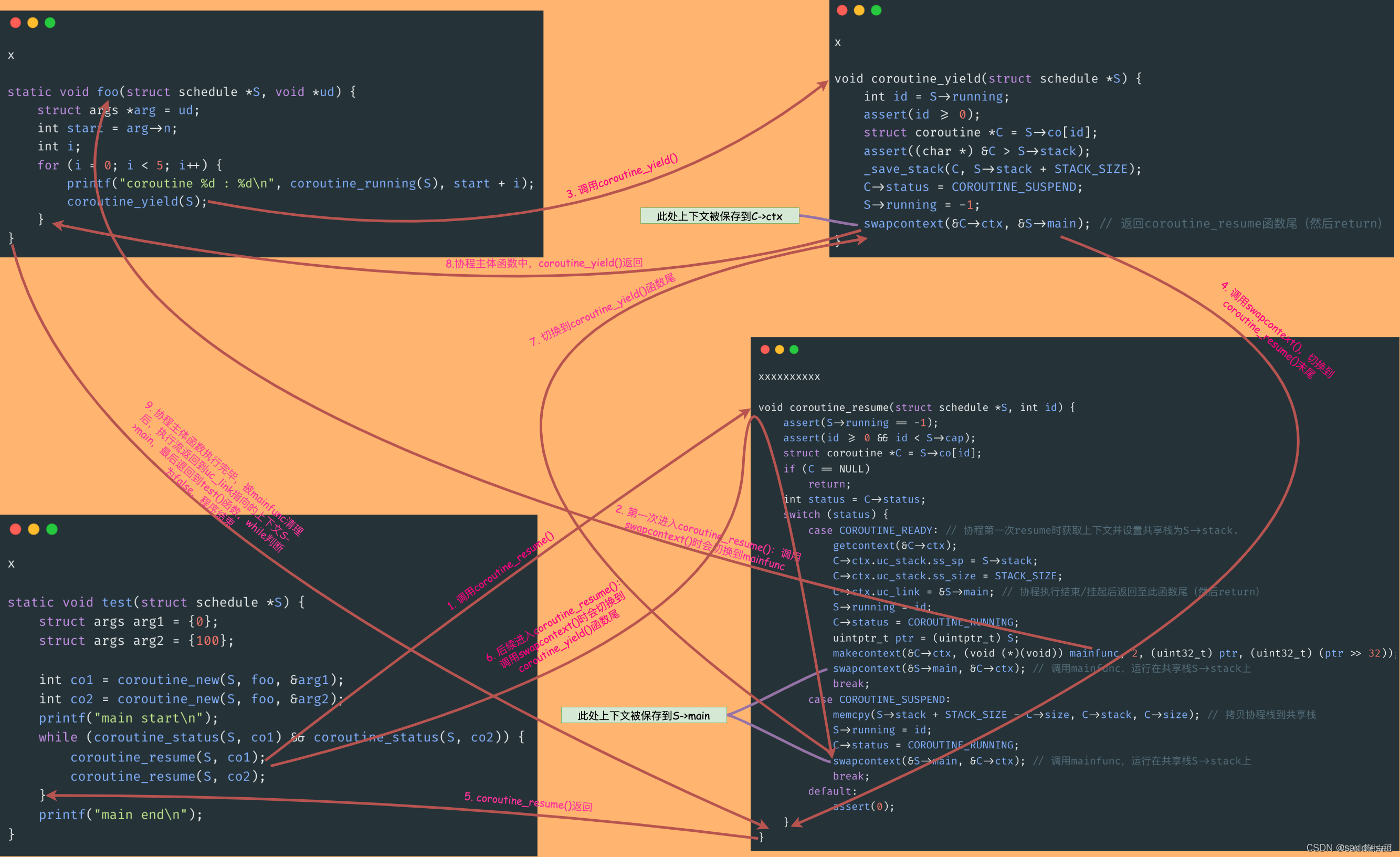
十一、总体API流程执行流程图
下图展示了以ucontextAPI为核心的协程执行流:
2)代码实体
#ifndef C_COROUTINE_H
#define C_COROUTINE_H
#define COROUTINE_DEAD 0
#define COROUTINE_READY 1
#define COROUTINE_RUNNING 2
#define COROUTINE_SUSPEND 3
struct schedule;
typedef void (*coroutine_func)(struct schedule *, void *ud);
struct schedule * coroutine_open(void);
void coroutine_close(struct schedule *);
int coroutine_new(struct schedule *, coroutine_func, void *ud);
void coroutine_resume(struct schedule *, int id);
int coroutine_status(struct schedule *, int id);
int coroutine_running(struct schedule *);
void coroutine_yield(struct schedule *);
#endif
四、协程函数实现文件coroutine.c
0)备注背景知识
1)ptrdiff_t是C/C++标准库中定义的一个与机器相关的数据类型。ptrdiff_t类型变量通常用来保存两个指针减法操作的结果
1)错误码及结构体解释
①struct args
struct args {
int n;
};
②struct coroutine
struct coroutine {
coroutine_func func; //协程执行函数
void *ud; // 要传递给函数的参数,一般是两个uint32_t拼成的调度器指针
ucontext_t ctx; //这个协程本身的上下文信息
struct schedule * sch; // 该协程所属的调度器
ptrdiff_t cap; //协程栈容量,已经分配的内存大小
// ptrdiff_t是C/C++标准库中定义的一个与机器相关的数据类型,通常用来保存两个指针减法操作的结果
ptrdiff_t size; // 协程栈已使用大小,当前协程运行时栈,保存起来后的大小
int status; // 运行状态,协程当前的状态,四个状态之一
char *stack; // 当前协程的保存起来的运行时栈
};
③struct schedule
struct schedule {
char stack[STACK_SIZE]; // 运行时栈,此栈即是共享栈
ucontext_t main; // 主协程的上下文,主协程的上下文,方便后面协程执行完后切回到主协程。
int nco; //管理的存活的协程数量
int cap; //管理的协程容量上限,如果不够了,则进行2倍扩容
int running; // 运行状态,-1表示未运行,>=0表示正在运行的协程ID
//其他表示正运行的协程id
struct coroutine **co; // 一个一维数组,用于存放所有协程。其长度等于cap,存放了目前所有的协程
};
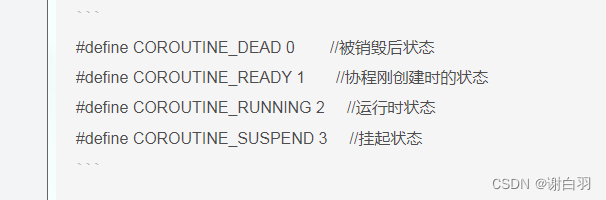
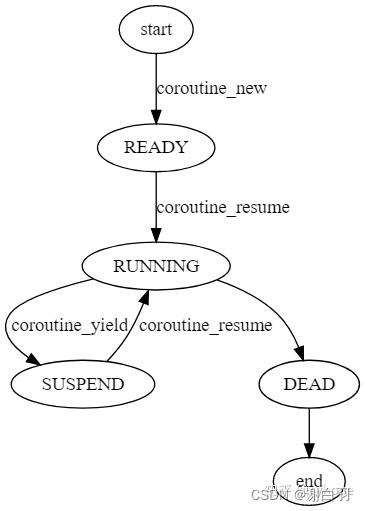
④协程四种状态解释
#define COROUTINE_DEAD 0 //被销毁后状态
#define COROUTINE_READY 1 //协程刚创建时的状态
#define COROUTINE_RUNNING 2 //运行时状态
#define COROUTINE_SUSPEND 3 //挂起状态
2)代码
#include "coroutine.h"
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stddef.h>
#include <string.h>
#include <stdint.h>
#if __APPLE__ && __MACH__
#include <sys/ucontext.h>
#else
#include <ucontext.h>
#endif
#define STACK_SIZE (1024*1024)
#define DEFAULT_COROUTINE 16
struct coroutine;
struct schedule {
char stack[STACK_SIZE];
ucontext_t main;
int nco;
int cap;
int running;
struct coroutine **co;
};
struct coroutine {
coroutine_func func;
void *ud;
ucontext_t ctx;
struct schedule * sch;
ptrdiff_t cap;
ptrdiff_t size;
int status;
char *stack;
};
struct coroutine *
_co_new(struct schedule *S , coroutine_func func, void *ud) {
struct coroutine * co = malloc(sizeof(*co));
co->func = func;
co->ud = ud;
co->sch = S;
co->cap = 0;
co->size = 0;
co->status = COROUTINE_READY;
co->stack = NULL;
return co;
}
void
_co_delete(struct coroutine *co) {
free(co->stack);
free(co);
}
struct schedule *
coroutine_open(void) {
struct schedule *S = malloc(sizeof(*S));
S->nco = 0;
S->cap = DEFAULT_COROUTINE;
S->running = -1;
S->co = malloc(sizeof(struct coroutine *) * S->cap);
memset(S->co, 0, sizeof(struct coroutine *) * S->cap);
return S;
}
void
coroutine_close(struct schedule *S) {
int i;
for (i=0;i<S->cap;i++) {
struct coroutine * co = S->co[i];
if (co) {
_co_delete(co);
}
}
free(S->co);
S->co = NULL;
free(S);
}
int
coroutine_new(struct schedule *S, coroutine_func func, void *ud) {
struct coroutine *co = _co_new(S, func , ud);
if (S->nco >= S->cap) {
int id = S->cap;
S->co = realloc(S->co, S->cap * 2 * sizeof(struct coroutine *));
memset(S->co + S->cap , 0 , sizeof(struct coroutine *) * S->cap);
S->co[S->cap] = co;
S->cap *= 2;
++S->nco;
return id;
} else {
int i;
for (i=0;i<S->cap;i++) {
int id = (i+S->nco) % S->cap;
if (S->co[id] == NULL) {
S->co[id] = co;
++S->nco;
return id;
}
}
}
assert(0);
return -1;
}
static void
mainfunc(uint32_t low32, uint32_t hi32) {
uintptr_t ptr = (uintptr_t)low32 | ((uintptr_t)hi32 << 32);
struct schedule *S = (struct schedule *)ptr;
int id = S->running;
struct coroutine *C = S->co[id];
C->func(S,C->ud);
_co_delete(C);
S->co[id] = NULL;
--S->nco;
S->running = -1;
}
void
coroutine_resume(struct schedule * S, int id) {
assert(S->running == -1);
assert(id >=0 && id < S->cap);
struct coroutine *C = S->co[id];
if (C == NULL)
return;
int status = C->status;
switch(status) {
case COROUTINE_READY:
getcontext(&C->ctx);
C->ctx.uc_stack.ss_sp = S->stack;
C->ctx.uc_stack.ss_size = STACK_SIZE;
C->ctx.uc_link = &S->main;
S->running = id;
C->status = COROUTINE_RUNNING;
uintptr_t ptr = (uintptr_t)S;
makecontext(&C->ctx, (void (*)(void)) mainfunc, 2, (uint32_t)ptr, (uint32_t)(ptr>>32));
swapcontext(&S->main, &C->ctx);
break;
case COROUTINE_SUSPEND:
memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size);
S->running = id;
C->status = COROUTINE_RUNNING;
swapcontext(&S->main, &C->ctx);
break;
default:
assert(0);
}
}
static void
_save_stack(struct coroutine *C, char *top) {
char dummy = 0;
assert(top - &dummy <= STACK_SIZE);
if (C->cap < top - &dummy) {
free(C->stack);
C->cap = top-&dummy;
C->stack = malloc(C->cap);
}
C->size = top - &dummy;
memcpy(C->stack, &dummy, C->size);
}
void
coroutine_yield(struct schedule * S) {
int id = S->running;
assert(id >= 0);
struct coroutine * C = S->co[id];
assert((char *)&C > S->stack);
_save_stack(C,S->stack + STACK_SIZE);
C->status = COROUTINE_SUSPEND;
S->running = -1;
swapcontext(&C->ctx , &S->main);
}
int
coroutine_status(struct schedule * S, int id) {
assert(id>=0 && id < S->cap);
if (S->co[id] == NULL) {
return COROUTINE_DEAD;
}
return S->co[id]->status;
}
int
coroutine_running(struct schedule * S) {
return S->running;
}
3)状态机转换流程图
五、云凤协程注意点
1)他实现的协程是无栈协程不用担心溢出的问题(同一调度器共享栈空间)
原文:
Coroutines in the same schedule share the stack , so you can create many coroutines without worry about memory.















 2427
2427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









