







 本文介绍了如何利用HTML5的Blob对象来保护网页中的音频和视频资源,避免被浏览器嗅探。通过创建XMLHttpRequest对象,设置响应类型为blob,获取服务端返回的文件流,然后转化为Blob对象,并用URL.createObjectURL()生成可播放的源,实现对敏感内容的保护。同时,文章提及了服务端返回文件流的示例代码,但注意到这种方式可能导致文件加载速度变慢,提出了后续需要考虑优化加载速度的问题。
本文介绍了如何利用HTML5的Blob对象来保护网页中的音频和视频资源,避免被浏览器嗅探。通过创建XMLHttpRequest对象,设置响应类型为blob,获取服务端返回的文件流,然后转化为Blob对象,并用URL.createObjectURL()生成可播放的源,实现对敏感内容的保护。同时,文章提及了服务端返回文件流的示例代码,但注意到这种方式可能导致文件加载速度变慢,提出了后续需要考虑优化加载速度的问题。
现在的浏览器很聪明,会对页面中的mp3,MP4等内容进行嗅探下载。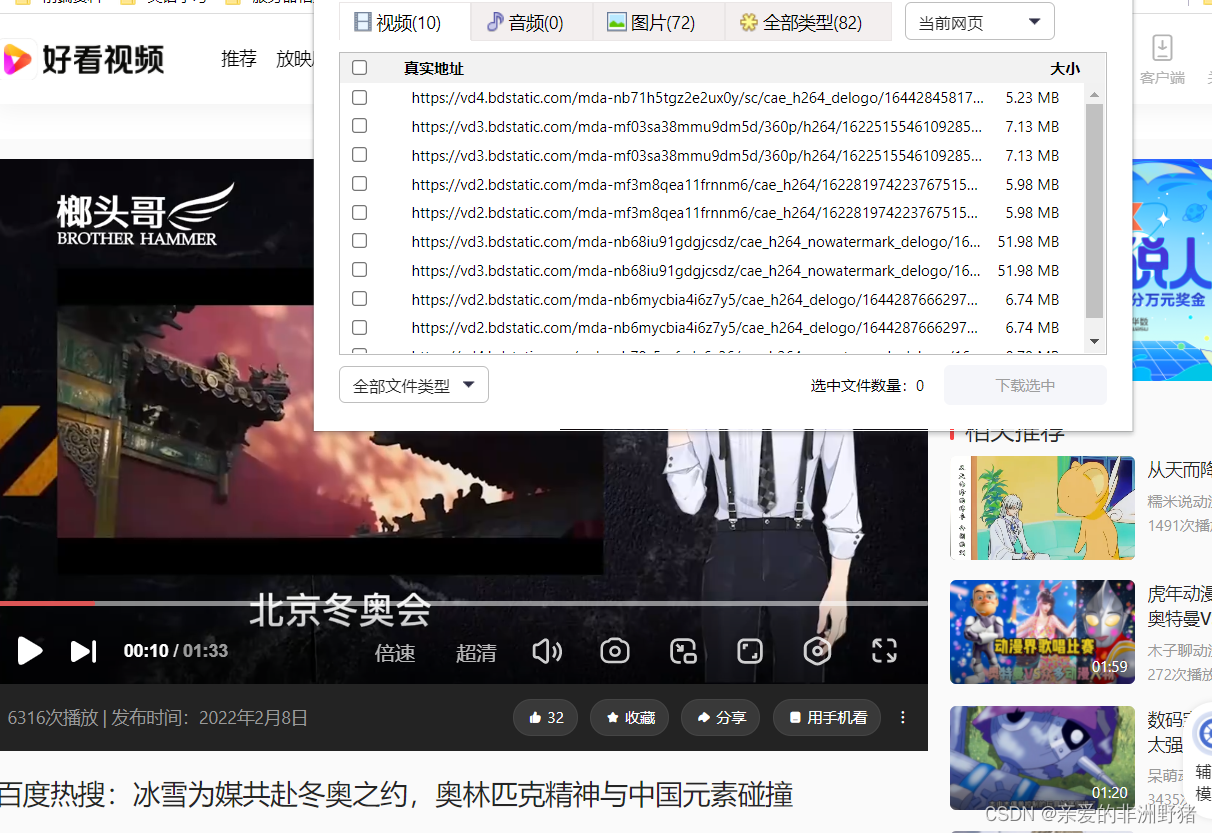 但是对于部分付费或敏感内容,我们并不想版权资源被嗅探。这就需要使用html5 提供的 blob 对象对文件内容进行保护,blob格式的资源是无法被嗅探的。
但是对于部分付费或敏感内容,我们并不想版权资源被嗅探。这就需要使用html5 提供的 blob 对象对文件内容进行保护,blob格式的资源是无法被嗅探的。
具体可以参考一下 blob介绍。
话不多说,直接看实例代码。
正常情况下的audio标签写法:
<audio controls src="https://img.tukuppt.com/newpreview_music/08/99/49/5c897788e421b53181.mp3" >
</audio>当然,如果是Vue的话这里的src 属性是可以动态绑定的。就不具体演示了。
接下来是blob格式的video 标签的实现:
<video id="tttt" width="200px" height="400px" controls="controls"></video>
<script>
//创建XMLHttpRequest对象
var xhr = new XMLHttpRequest();
//配置请求方式、请求地址以及是否同步
xhr.open('POST', 'http://localhost:8081/file/get?url=8bdc9.mp4', true);
//设置请求结果类型为blob
xhr.responseType = 'blob';
//请求成功回调函数
xhr.onload = function(e) {
if (this.status == 200) {//请求成功
//获取blob对象
var blob = this.response;
//获取blob对象地址,并把值赋给容器
var video = document.getElementById("tttt");
video.setAttribute("src", URL.createObjectURL(blob));
}
};
xhr.send();
</script>这就是个例子,如果要加上鉴权就携带请求头或者cookie,先进行鉴权就行了。
注意一下,这里的请求的路径是需要服务端支持的。
比如如果是使用阿里云的对象存储服务,不能直接使用文件对象的公网访问url,应该拿着文件id(和用户信息)访问自己的服务端,自己的服务端完成鉴权后查到该文件的阿里云路径,读取并返回,这里简单提供一个服务端的例子:
private static void fileResponse(InputStream fis, String fileName) {
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
if(requestAttributes == null){
return;
}
HttpServletRequest request = (HttpServletRequest) requestAttributes.resolveReference("request");
HttpServletResponse response = ((ServletRequestAttributes) requestAttributes).getResponse();
String agent = request.getHeader("User-Agent").toUpperCase();
OutputStream os = null;
try {
fis = new BufferedInputStream(fis);
byte[] buffer;
buffer = new byte[fis.available()];
fis.read(buffer);
//由于火狐和其他浏览器显示名称的方式不相同,需要进行不同的编码处理
if (agent.indexOf("FIREFOX") != -1) {//火狐浏览器
response.addHeader("Content-Disposition", "attachment;filename=" + new String(fileName.getBytes("GB2312"), "ISO-8859-1"));
} else {//其他浏览器
response.addHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(fileName, "UTF-8"));
}
//设置response编码
response.setCharacterEncoding("UTF-8");
//设置输出文件类型
response.setContentType("video/mp4");
//获取response输出流
os = response.getOutputStream();
// 输出文件
os.write(buffer);
} catch (Exception e) {
LOGGER.error("error:",e);
} finally {
//关闭流
try {
if (fis != null) {
fis.close();
}
} catch (IOException e) {
LOGGER.error("error:", e);
} finally {
try {
if (os != null) {
os.flush();
}
} catch (IOException e) {
LOGGER.error("error:", e);
} finally {
try {
if (os != null) {
os.close();
}
} catch (IOException e) {
LOGGER.error("error:", e);
}
}
}
}
}
这里的InputStream就是(鉴权后)从文件服务器(自有或者阿里云腾讯云等)处读取到的文件流。
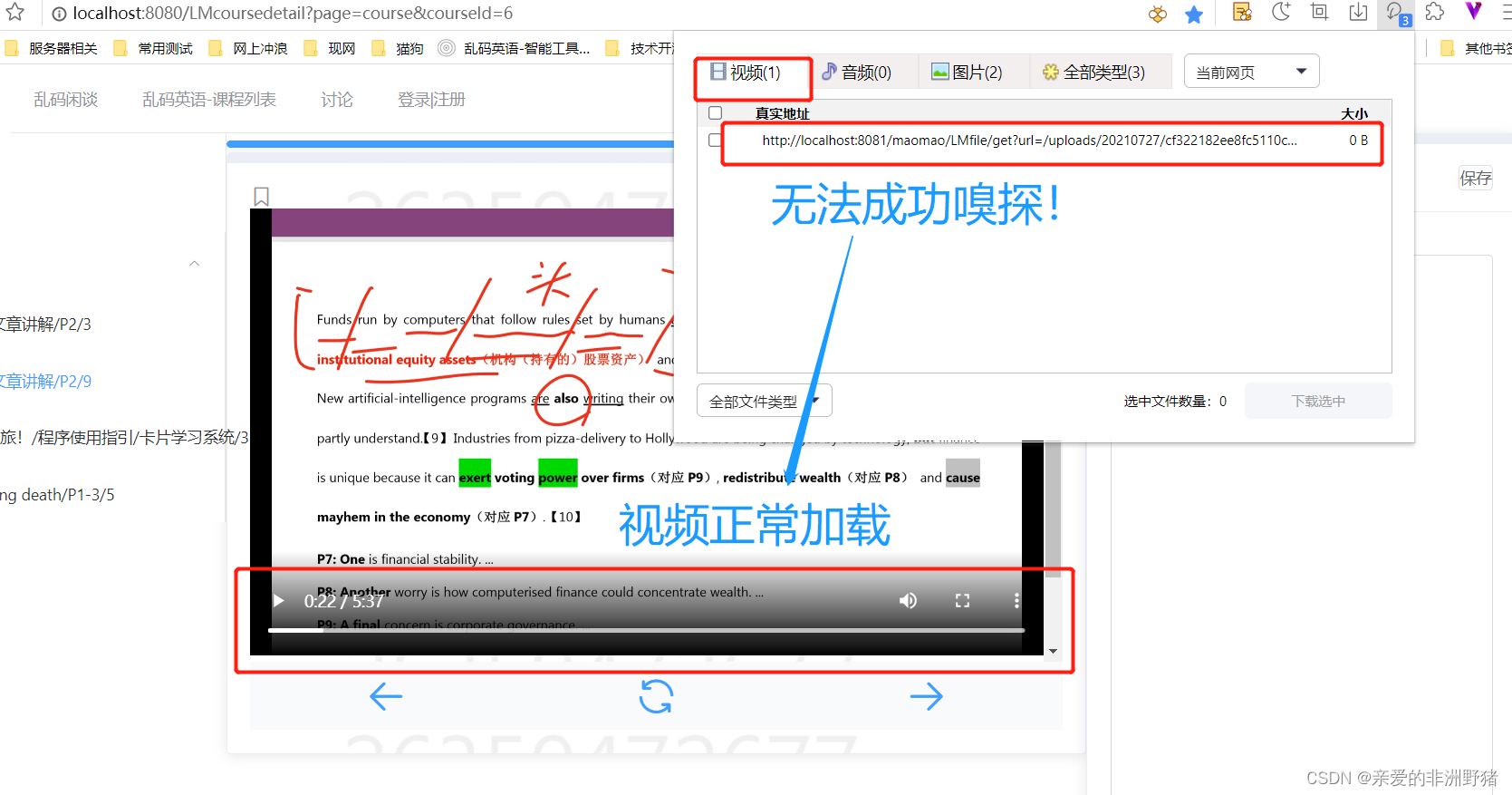
-------------------------------
事情写到这就改结束了,我的任务看上去也完成了。但是在项目里实现后,发现文件加载的速度真的是非常的慢,这是个大问题!
接下来要考虑怎么提高加载速度!!


















 6920
6920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









