






docker pull zookeeper
docker run -it -p2888:2888 -p2181:2181 --name=zookeeper zookeeper

这样zookeeper就起来了
我们创建一个节点
create /test2222 '2222'
docker run -it --rm --link zookeeper:zookeeper zookeeper zkCli.sh -server zookeeper 我们可以直接连接zk
============================================>>>>>>>>>>>>>>>>
也可以进入容器以后再连接zk
docker exec -it zookeeper bash //只登录容器,不登录 zkCli
./bin/zkCli.sh //执行脚本新建一个Client,即进入容器
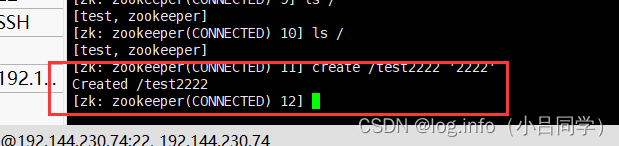
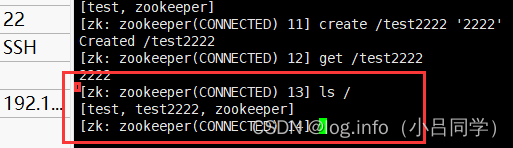
我们get test2222
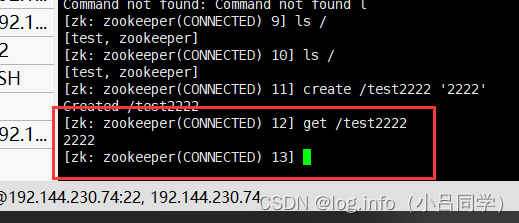
可以采用ls / 来查看我们所有的节点
--------------------------------------------------------------------
接下来我们启动kafka 连接zookeeper
我们可以使用他启动kafka 并且连接zookeeper
docker run -d --name kafka0 -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=127.0.0.1:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
之后我们docker ps -a 可以看看

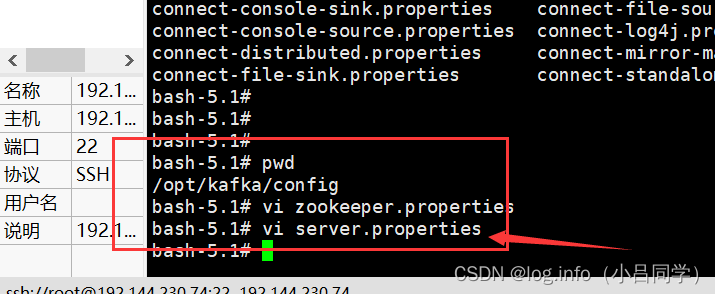
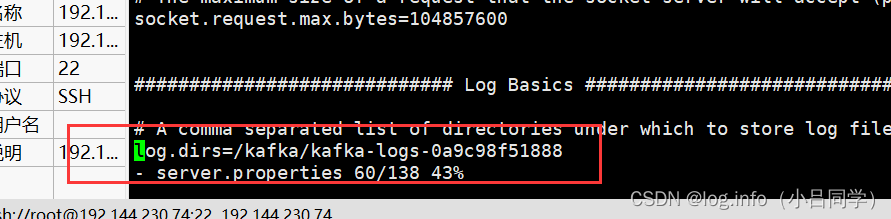
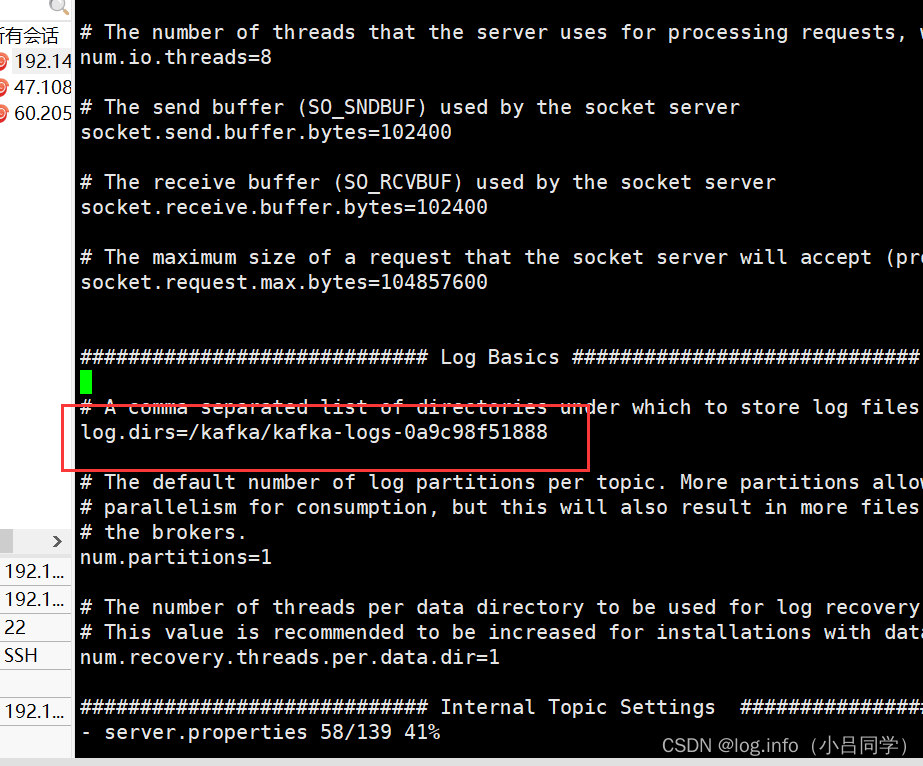
我们可以看到我们当前的kafka的配置文件中 sercer.properties
的 log.dirs 存放在哪里
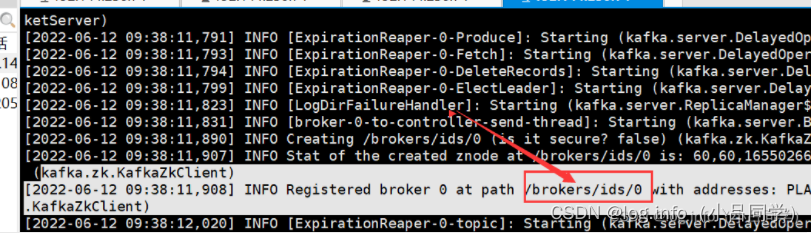
看kafka 启动日志 kafka在启动的时候会吧自己的信息 注册在zookeeper上 位于/brokers/id/0 dai
之后我们可以建立一个主题topic 进行收发数据
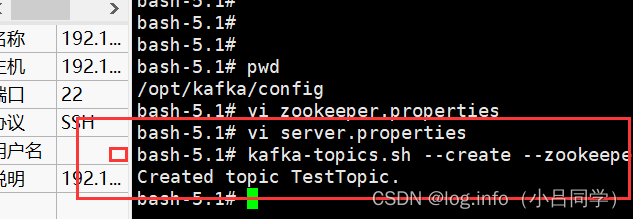
创建topic
副本数指定为1 分区指定为1 副本和分区以后再说
kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic TestTopic
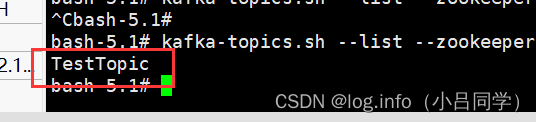
查看topic : kafka-topics.sh --list --zookeeper 127.0.0.1:2181
下面是进入zk的界面 因为我们kafka连接的zk,所以kafka在启动的时候会吧一些元数据放在zk中 比如说broker信息

# 用这个命令 发送消息到 TestTopic 中
kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic TestTopic
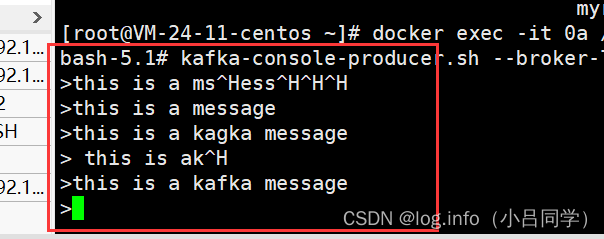
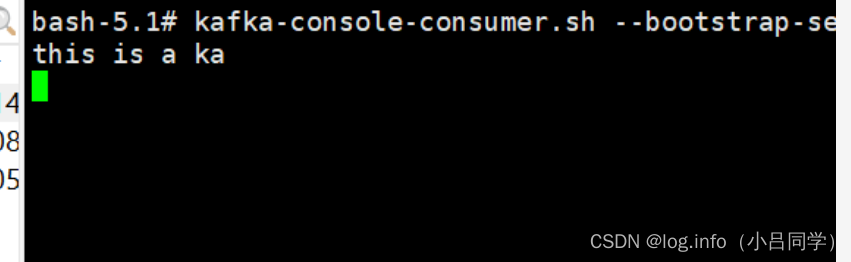
# 只会接受 消费者启动之后de 信息
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic TestTopic
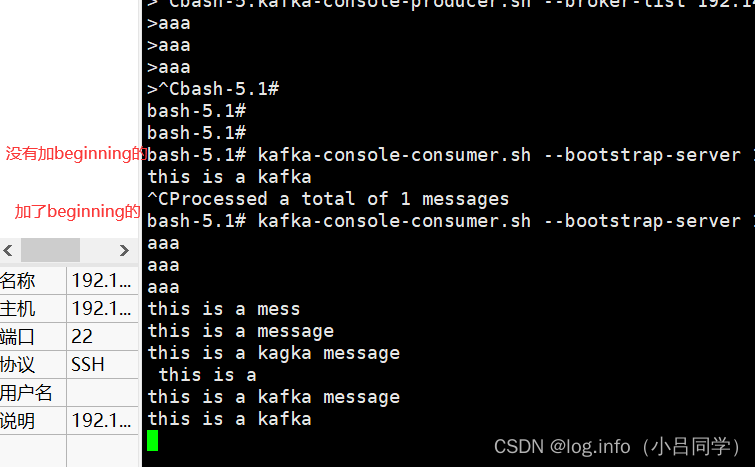
# 会接受所有基于主题的消息
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic TestTopic --from-beginning
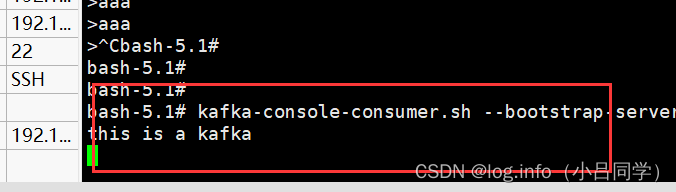
我们可以看下区别
我们可以查看他们的topic
kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic TestTopic

# 消费者组
我们可以建立一个消费者组 来消费topic
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --consumer-property group.id=halow --topic TestTopic
# 我此时的消费者组为halow 订阅主题TestTopic
--consumer-property group.id=halow
当发送消息的时候 一样可以收到消息的
但是同一个消息在同一个消费者组里面只能接受一次
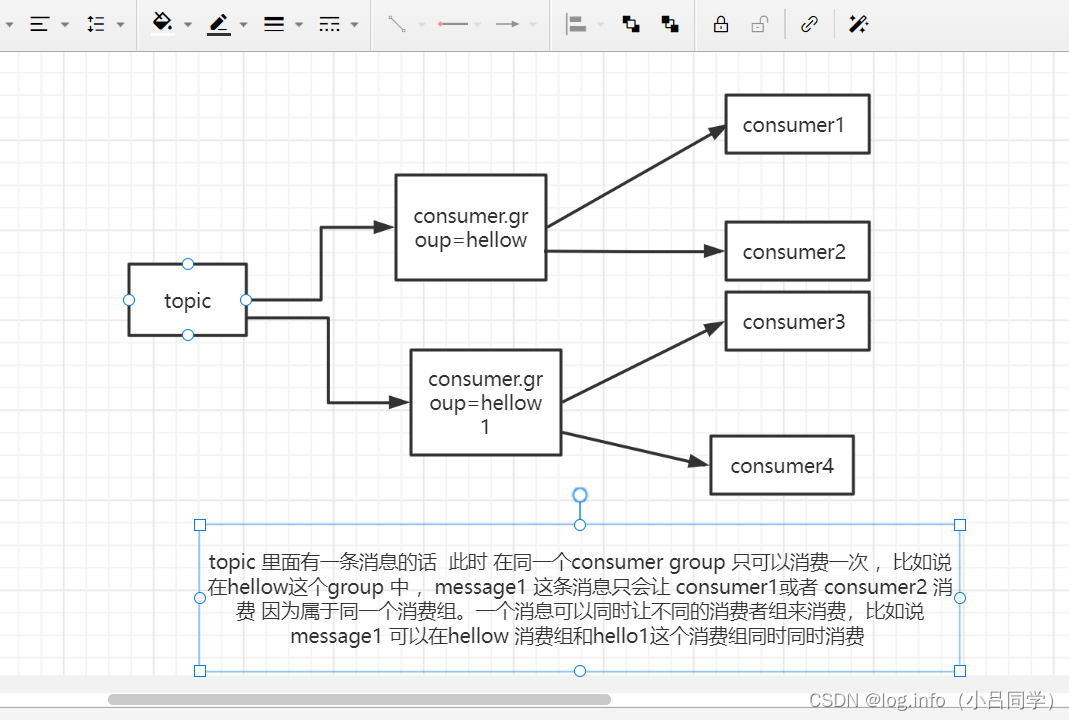
也就是说kafka的消费记录是以组来记录的,我们可以看看某一个组的消费情况 还有可以看看具体有那些组
# 查看有那些组
kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
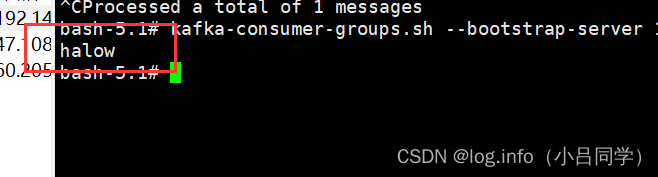
我此时就一个hello组
# 查看这个组的消费情况
kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group hello

lag代表 我此时这个组还没有消费到的消息 每一个消息是有一个唯一偏移量的
在同一个分组下的同一个分区 此时分区是0号位
current-offset:当前消费组的已消费偏移量
log-end-offset:主题对应分区消息的结束偏移量(HW)
lag:当前消费组未消费的消息数
我说说什么是分区
一个主题默认里面有1个分区,我们的消息最终是发送在topic下面的分区的,我们可以在创建主题的时候设置多分区 我们所有消息都是基于主题下面的分区去做的,我们所有消息的收发都是基于主题下面的分区去做的
kafka 有个特点就是数据不删除 默认7天删除 我们可以配置 为什么有多分区
针对于大数据的情况 会有一个分布式存储的思想,假如我此时开一个分区,淘宝几百亿的订单数据放在一个文件中是行不通的
所以kafka的数据是落到磁盘的 我可以开多个分区 以后将这些分区文件分别存储在不同的机器上
如果我存一个文件的话 海量数据下的是存不了的
分区的数据, 会存储在你磁盘上的某一个文件 。每一个消息在一个主题下面的一个分区上有一个唯一偏移量(索引值)
他只在当前分区是唯一的
消费实际上也是针对于某一个分区,我一个消费者也可以消费多个分区
类似于下面的
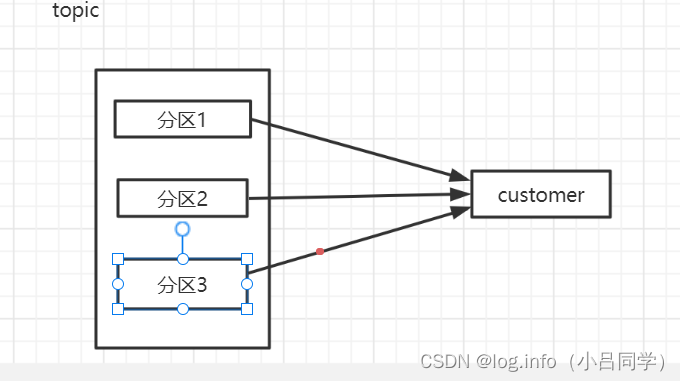
我们收发信息都是基于某个主体下面的某个分区去发送消息的
默认是1个主体下面有一个分区
建立多少个分区我们可以通过参数来设置 所有消息的收发 都是基于某个分区去做的
如果只有一个分区的 话,我大数据情况下 海量数据是存不下来的
我可以搞很多分区,这样我可以多分区存储数据,然后将分区数据文件放在不同的磁盘中
分区 你发消息 发到你主体下面的某个分区 , 他就会存储在你磁盘上面的某个文件上
# 我此时创建一个topic 有2个分区一个副本 创建多分区主题
kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 2 --topic TestTopic22
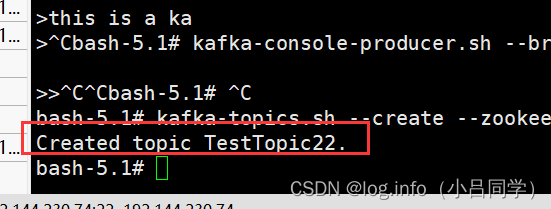
# 我可以查看我这个topic 的情况,我此时TestTopic 有2个分区 分区0和分区1
==============================>>>>>>>>>>>>.
和集群有关
leader代表 当前这个分区的 主副本
Relicas 代表所有副本
Isr代表当前存活的副本

我们可以在kafka 的server 配置文件看到这些信息 可以在这个目录下看到我们的broker
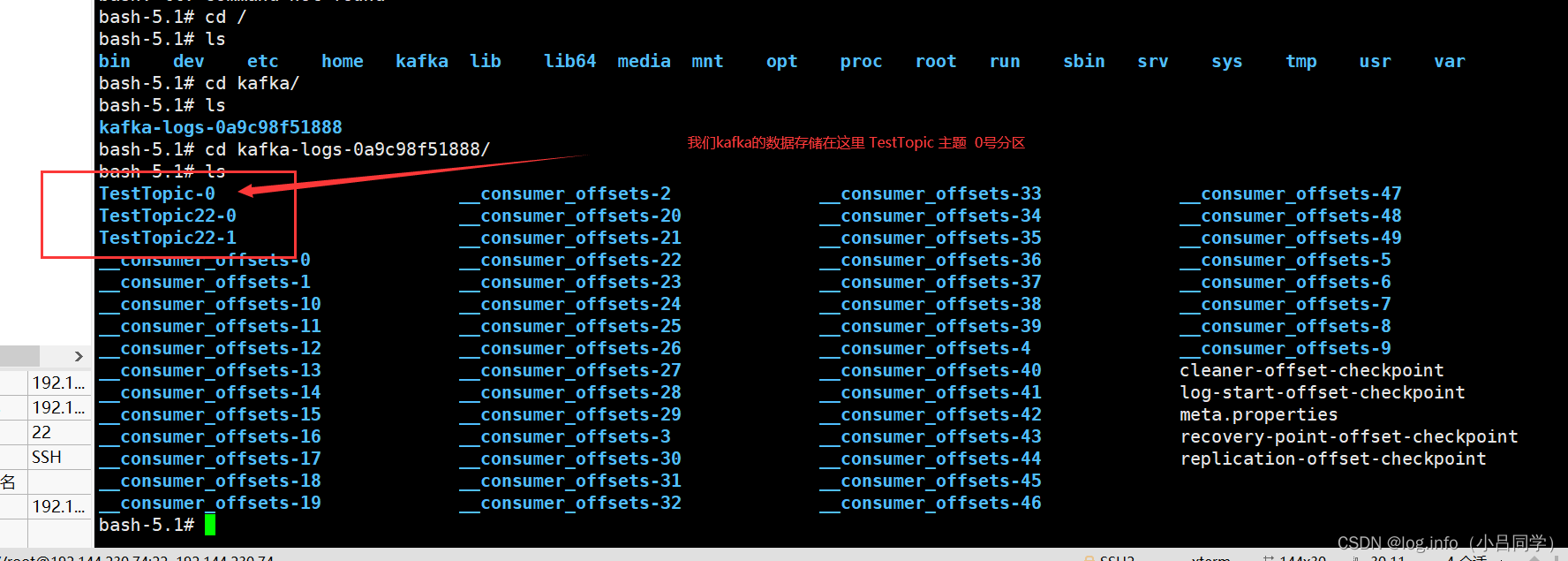
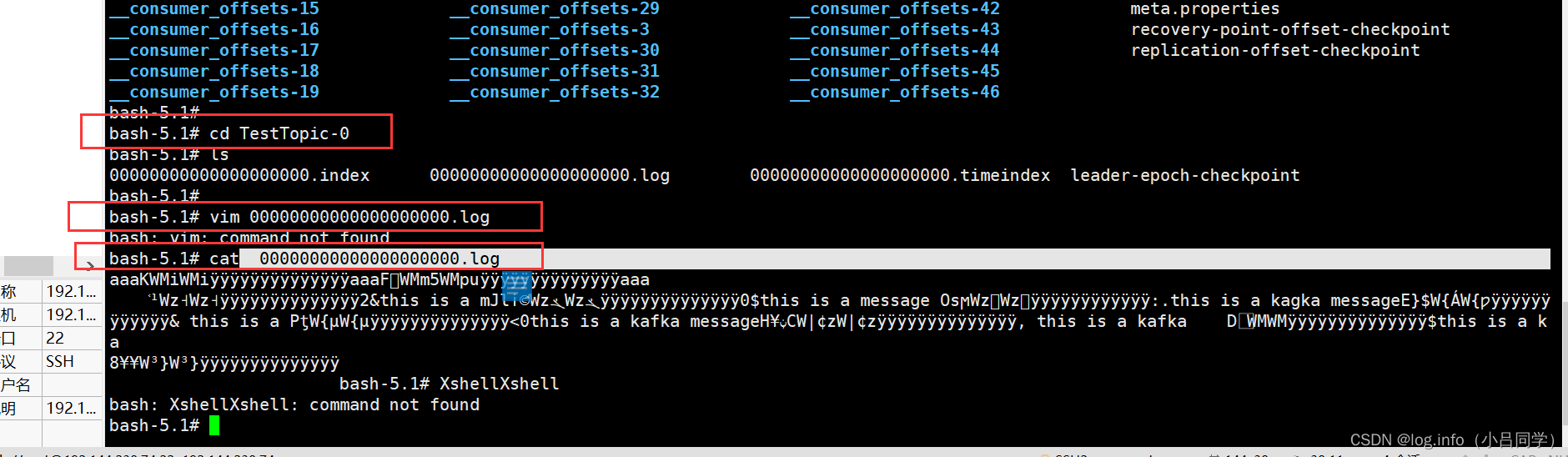
数据存储在 00000000000000000000.log 下 这不就是我们刚刚发送的消息么
# 增加分区 我们也可以给我们的主题增加分区 (现在是kafka不支持减少分区的)
kafka-topics.sh -alter--partitions 5--zookeeper 127.0.0.1:2181 --topic TestTopic22
kafka集群 对于kafka的集群我们只需要让他们 连接同一个zookeeper就可以了
# 名字kafka1 端口号 9093 id
docker run -d --name kafka1 -p 9093:9093 -e KAFKA_BROKER_ID=1 -e
# 连接同一个zookeeper不变化
KAFKA_ZOOKEEPER_CONNECT=127.0.0.1:2181 -e
#暴露端口 9093
KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9093 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 -t wurstmeister/kafka
docker run -d --name kafka2 -p 9094:9094 -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=127.0.0.1:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9094 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9094 -t wurstmeister/kafka
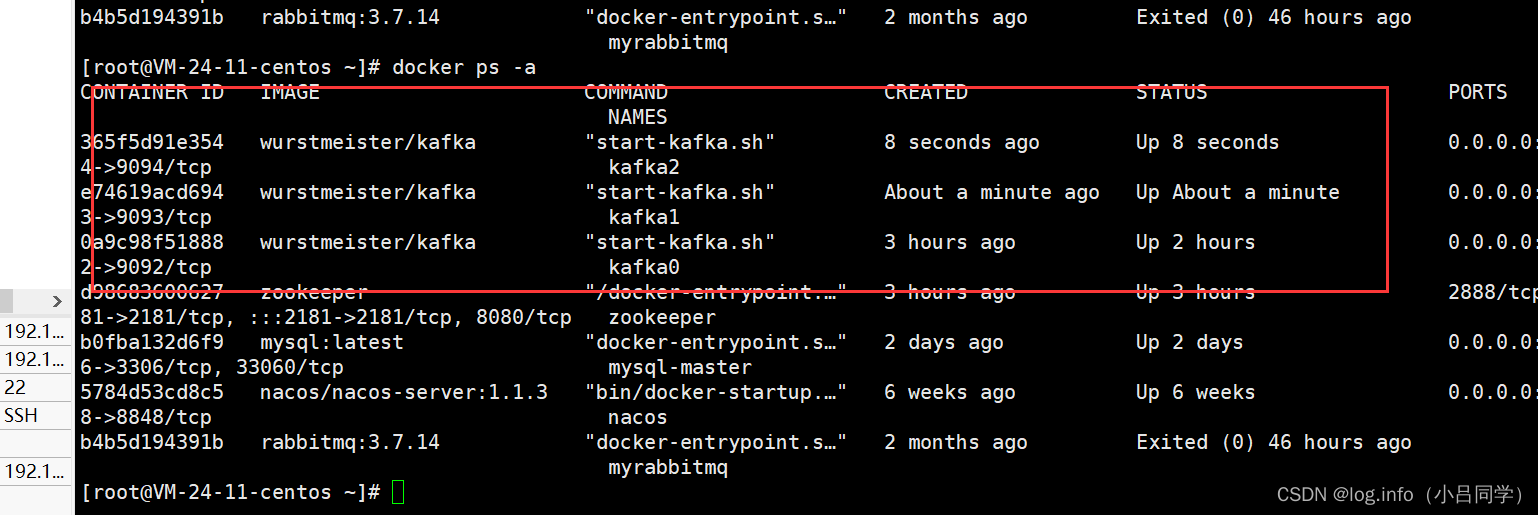
我们只要让他们保证连接同一个zookeeper就可以让他们做成一个集群
我此时可以在zookeeper列表中查到

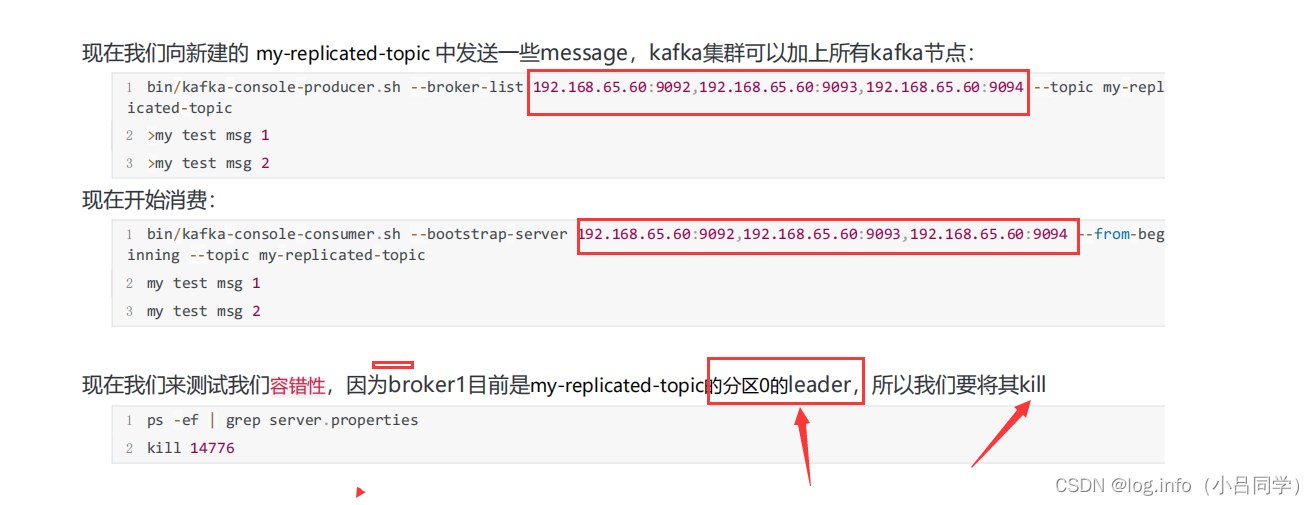
现在我们创建一个新的topic,副本数设置为3,分区数设置为5:
kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 3 --partitions 5 --topic TestTopic3333
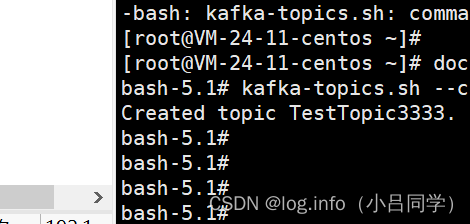

我本地服务器卡 我就用别人的图了啊@@@@@@@@@@@@@@@@@@

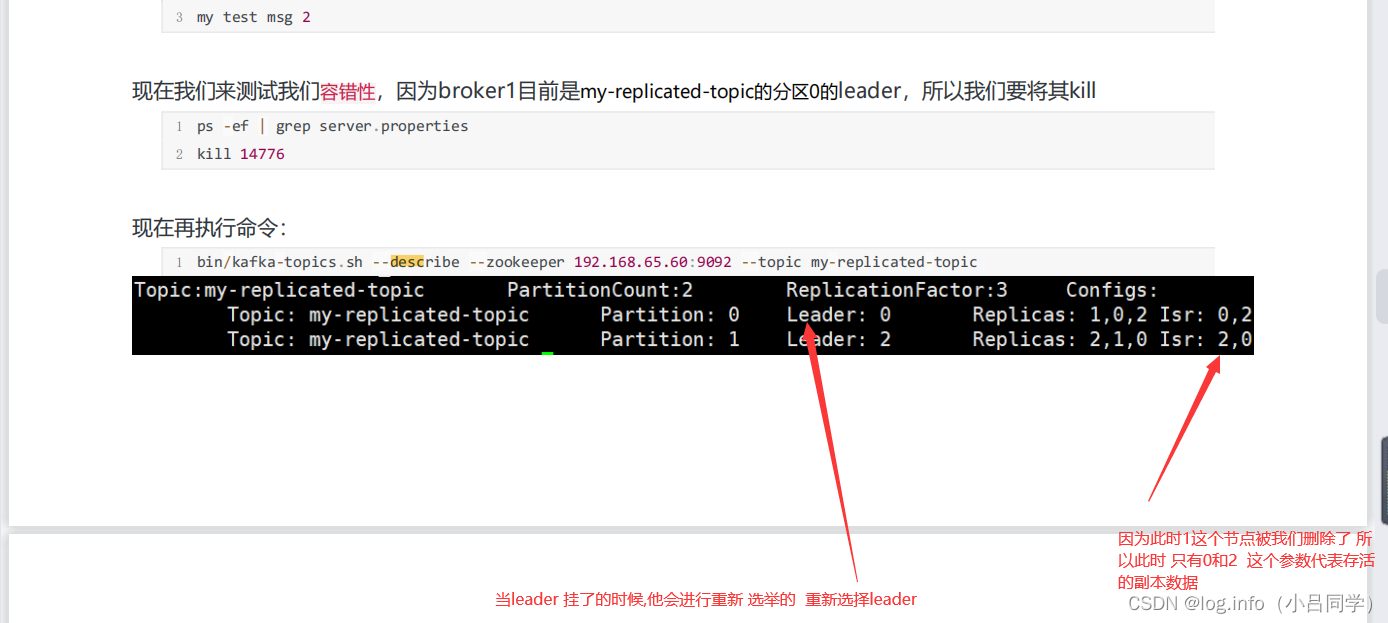
因为我们此时建立了3个集群
此时这里的副本数就是3个 分别为1,2,3 ,分区0的主副本是0,分区1的主副本是2
kafka的集群式针对于分区来说的
这里我都有说明
我们接下来看一看我们java代码怎么连接我们kafka 进行收发消息
#
加入pom
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>
private final static String TOPIC_NAME = "Allen-Reclica-topic1";
public static void main(String[] args) {
Properties props = new Properties();
// 连接kafka的ip:端口
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.101:9092,192.168.0.101:9093,192.168.0.101:9094");
props.put(ProducerConfig.ACKS_CONFIG, "1");
props.put(ProducerConfig.RETRIES_CONFIG, 3);
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 1; i <= 5; i++) {
Order order = new Order(i, 100 + i, 1, 100);
// kafka提供的发送消息的类
ProducerRecord<String, String> producerRecord =
new ProducerRecord<String, String>
// 我此时指定分区0 如果不指定的话 默认会根据key进行hash散列 // key value
(TOPIC_NAME , 0, order.getOrderId().toString(), JSON.toJSONString(order));
/ 底层是用了线程Future 我们可以 .get 阻塞他
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("同步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());
}
producer.close();
}
## 具体可以参照这个
https://blog.csdn.net/pengweismile/article/details/117675490















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









