







CUFD: An encoder-decoder network for visible and infrared image fusion based on common and unique feature decomposition
红外和可见光融合:基于共性和唯一特性分解的编解码网络
源图像的浅层特征包含图像的丰富信息,深层特征更注重如何提取源图像的热量信息;深层和浅层特征具有不同的电磁相位。
目前红外和可见光融合存在的一些问题:
大多数算法融合只注重保持红外图像的像素强度分布。
许多传统的基于深度学习的图像融合算法在融合前对图像进行了不同层次的分解;但是在每一层上采用相同的转换方式,忽略了同一层上的多模态图像的特征图显示出很大的可变性,表示不同的特征或物理含义。
在深层和浅层特征中,大多数采用深度特征去保持目标的显著性,忽略了浅层特征包含的细节信息。
总体来说就是:
设计一个IM-AGE编解码网络,提取图像特征,将图像特征根据特征映射分为公共部分和为一部分,对于不同部分采用不同的融合规则,最后进行重建。
公共部分和独特部分:

在对特征图进行分析时,左上和右上(树和草丛)这些不重要的部分在两幅图像的特征图上看起来很相似。 因此,我们称这部分为公共部分。
独特部分就是展示科技暗光和红外特征图之间差异的部分(如:上图最后一列的图像显示),在最终融合时要求在独特的部分保持更高程度的信息;同时在可见光和红外光两种特征图像中亮度越大(像素越高)的部分通常是属于自己的独特部分。
特征映射
特征映射越深层的所保留的细节信息会越少,专注于去提取源图像的显著区域;
特征映射分解
整体流程图
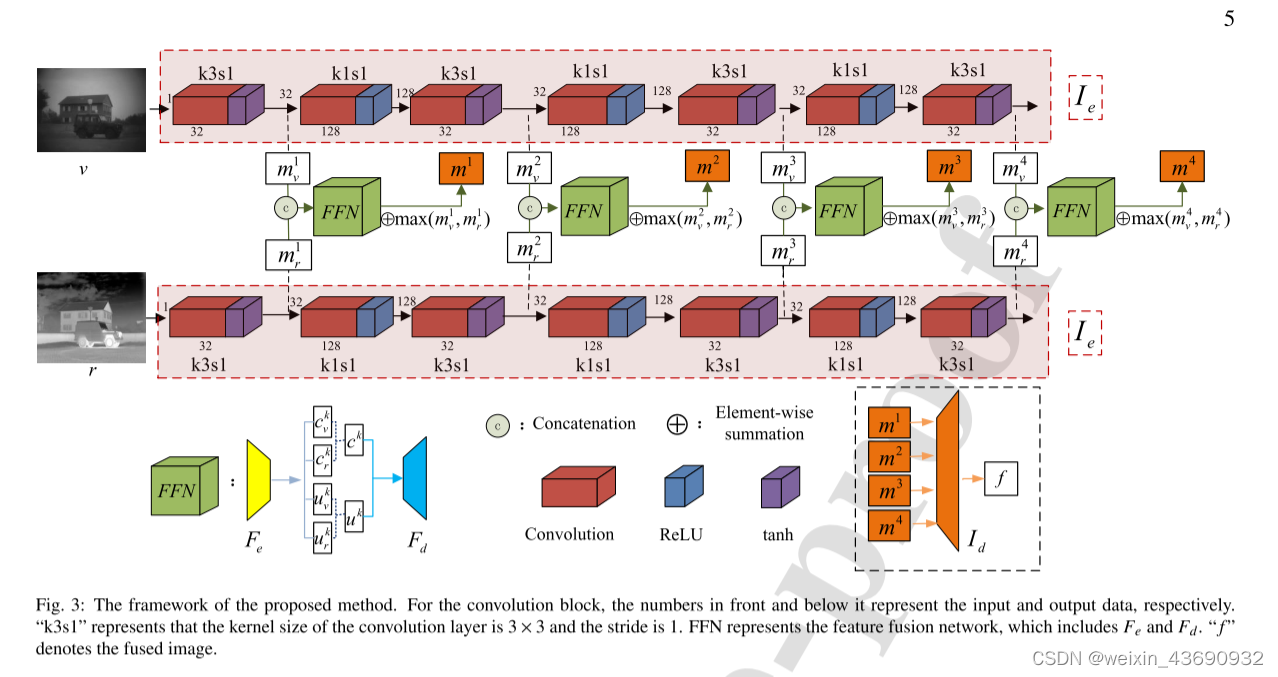
该框架包含两对编码器-解码器网络,即图像编码器-解码器网络(定义为Ie和Id,以及特征编码器-解码器网络(定义为Fe和Fd) 这两对编解码网络起着不同的作用,具有不同的网络结构。
图像编码器-解码器网络:Ie从原始图像中提取四组不同深度的特征映射。 然后,Id基于这四组特征映射重建图像。
特征编码器-解码器网络FFN:Fe将特征映射分解为公共部分和唯一部分,然后Fd进行重构基于这两个部分的特征映射。
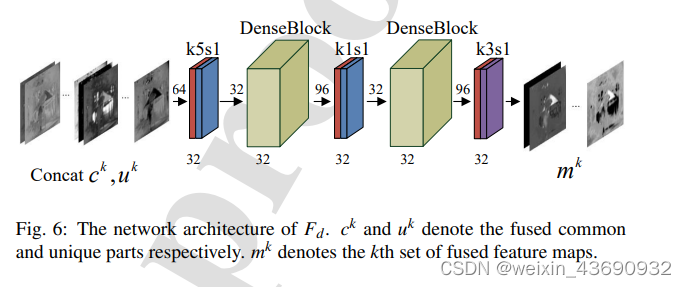
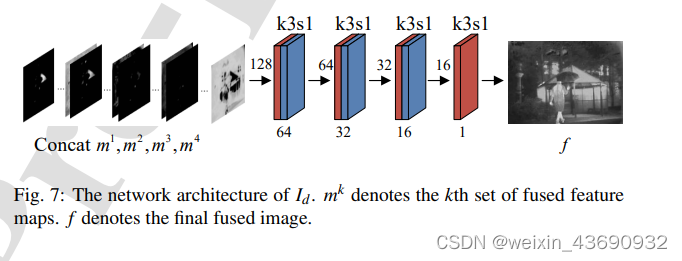
“K3S1”表示卷积层的内核大小为33,步幅为1。
卷积块前面和下面的数字分别表示输入和输出数据。
同一组可见光(v)和红外光(r)成对的送入Fe中,分成公共和独特部分后再次在Fd中实现重构输出+max(Mv,Mr)得到Mi**,最后四组Mi再次一同送入Id中进行组合重构,产生最后的融合图像。**
采用max(Mv,Mr)最大像素值规则对独特部分进行保留(像素高、亮度大的一般为图像的独特部分,如在图2中:可见光的帐篷、红外光的人)
融合操作完成后,其余两个解码器(Fd、Id)实现相应的重构功能。特征编码器实现特征重建,图像解码器生成融合图像。将同一层中的公共部分和唯一部分输入到Fd,以生成一组重构的特征地图,表示为Fd(ck,uk)。此外,我们添加了一个补充块,以进一步确保突出区域的保存,其定义为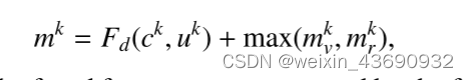
FNN的流程
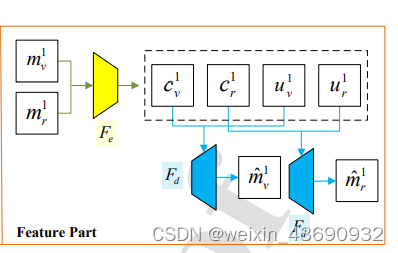
注意:是可见光的公共部分Cv和独特部分Uv一起成为M’v;M’v、M’r就是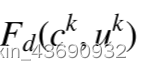 结果
结果
特征编码器Fe
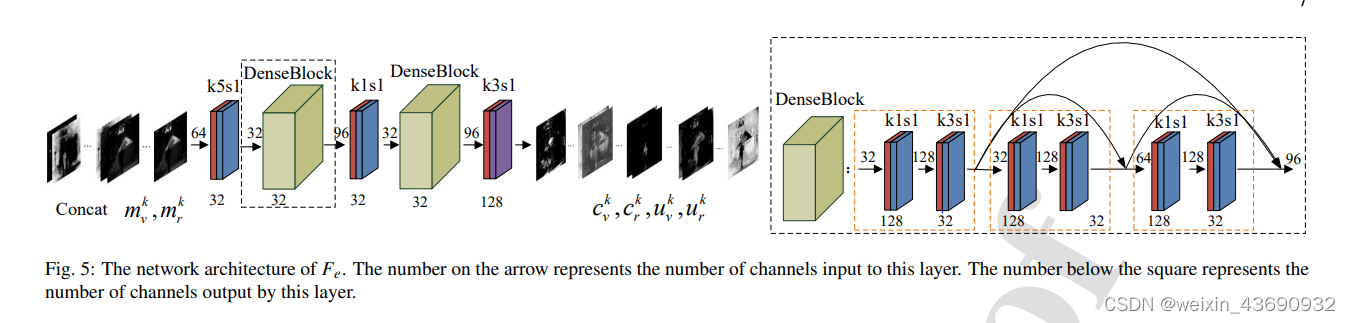
将特征图分为公共部分和独特部分
特征解码器Fd















 6868
6868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









