







文章目录
一、认识编解码网络
编解码模型分为编码器和解码器两部分,编码器通常输入的是一个信息量比较大的数据。
二、什么是编解码网络?
编解码结构的网络模型又叫encoder-decoder模型,顾名思义,编解码模型就像一个压缩器和解压器的组合,它们分别负责对输入到各自网络当中的信息进行压缩和解压,因此成为编解码模型。
三、编解码的作用
- 编码器的作用就是把这些大量的数据进行压缩,提取特征,通过编码器输出的结果一般是一组对于原数据而提取的特征向量。
- 解码器的作用则是对编码器输出的特征向量进行解码,以期望得到原始数据相同或相近的结果。
四、编解码网络的种类
深度学习中的编解码网络的种类有很多,最常见的就是seq2seq, AE, VAE等模型。
举个例子, SEQ2SEQ网络模型就像一个翻译模型, 输入是一个序列(比如一个英文句子),输出也是一个序列( 比如该英文句子所对应的法文翻译)。
编解码模型是RNN最重要的一个变种: NvsM (输入与输出序列长度不同)。 在机器翻译中:输入(hello)-> 输出(你好)。输入是1个英文单词,输出为2个汉字。 在对话机器中:我们提(输入)一个问题,机器会自动生成(输出)回答,这里的输入和输出显然是长度没有确定的序列(sequences).
一个邮件对话的场景
下图中展示的是一个邮件对话的应用场景,图中的Encoder和Decoder都只展示了一层的普通的LSTMCell。从上面的结构中,我们可以看到,整个模型结构还是非常简单的。EncoderCell最后一个时刻的状态就是上面说的中间语义向量, 它将作为DecoderCell的初始状态。然后在DecoderCell中,每个时刻的输出将会作为下一个时刻的输入。

深入理解Encoder
Encoder部分应该是非常容易理解的,就是一个RNNCell (RNN,GRU,LSTM 等)结构。我们向Encoder中输入一个字/词(一般是表示这个字/词的一个实数向量),直到我们输入这个句子的最后一个字/词,然后输出整个句子的语义向量c (一般情况下,C是最后一个输出)。因为RNN的特点就是把前面每一步的输入信息都考虑进来了,所以理论上这个C就能够把整个句子的信息都包含了,我们可以把C当成这个句子的一个语义表示,也就是一个句向量。在Decoder中,我们根据Encoder得到的句向量一步一步地把蕴含在其中的信息分析出来。
我们可以先这样来理解:在Encoder中我们得到了一个涵盖了整个句子信息的实数向量C,现在我们一步一步的从C中抽取信息。首先给Decoder输入一个启动信号,然后Decoder根据对c解码,就能够计算出当前的概率分布了,同理,根据c可以计算每一步的概率分布.以此类推直到预测到结束的特殊标志“”,才结束预测。
五、基于N vs M的RNN网络
5.1 什么是SEQ 2 SEQ(N vs M)?
SEQ 2 SEQ是RNN最重要的一个变种: N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
5.2 SEQ 2 SEQ的结构及编解码过程
原始的NvsN RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
因此,Encoder- Decoder结构先将输入数据编码成一个上下文向量c:拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中。


decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。

5.3 SEQ2SEQ生成对联的过程

在SEQ2SEQ中,当前时间的隐藏状态由上一时间的状态和当前时间输入决定的,即:ht = f(ht-1, xt), 获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后的语义向量:C = q(h1, h2, h3, …, hxn), 当然,有一种最简单的方法是将最后的隐藏层作为语义向量C,即:C = q(h1, h2, h3, …, htx) = htx.
解码过程可以看做编码的逆过程。这个阶段,我们根据给定的语义向量C和之前已经生成的输出序列y1, y2, …, yt-1来预测下一个输出的单词yt, 即:
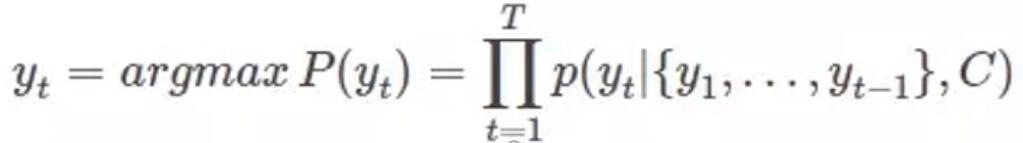
或者写作:
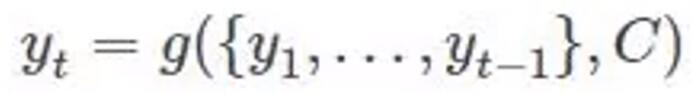
在RNN中,也可以简化成:

5.4 应用场景
- 机器翻译:Encoder-Decoder的最经典应用。
- 文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列。
- 阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
- 语音识别:输入是语音信号序列,输出是文字序列。
- 诗词生成:让机器为你写诗并不是一个遥远的梦,即给定诗词的上一句来生成下一句。
- 对话生成:通过海量的数据来训练模型,做出一个智能体,可以回答任何开放性的问题。
六、实战:SEQ2SEQ识别验证码
github仓库地址:https://github.com/liu1073811240/SEQ2SEQ















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









