







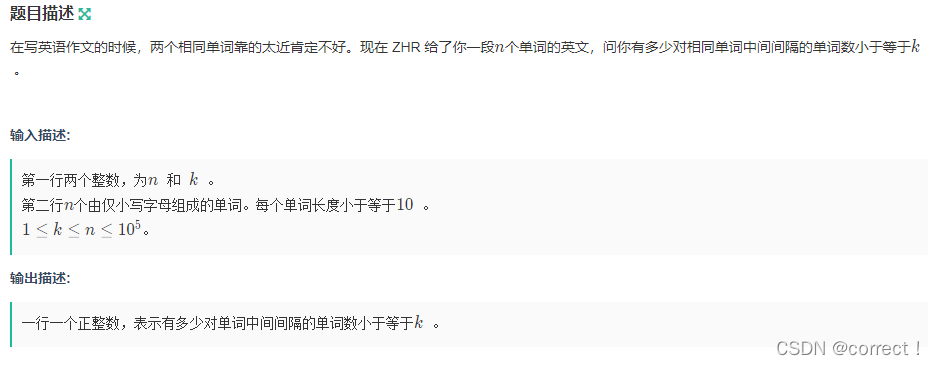
题目链接
想到了双指针的写法,看了题解之后感觉题解中的算法太妙了,记录一下
需要的是
i
<
j
i < j
i<j 且
s
[
i
]
=
s
[
j
]
s[ i ] = s[ j ]
s[i]=s[j] 且
i
i
i 和
j
j
j 之间的间隔不超过
k
k
k (
j
−
i
−
1
j - i - 1
j−i−1
≤
\leq
≤
k
k
k )
等价于
s
[
i
]
=
s
[
j
]
s[ i ] = s[ j ]
s[i]=s[j] 且
j
−
1
j - 1
j−1
≥
\ge
≥ i
≥
\ge
≥
j
−
k
−
1
j - k - 1
j−k−1
枚举
j
j
j
m
p
[
]
mp[ ]
mp[] 的定义是:
m
p
[
s
]
mp[ s ]
mp[s] 表示
s
s
s 前面与
s
s
s 间隔
k
k
k 个之内 满足题设的个数
当计算到
s
[
j
]
s[ j ]
s[j] 的时候,
m
p
[
]
mp[ ]
mp[] 中存放的是
s
[
j
−
k
−
2
]
s[ j - k - 2]
s[j−k−2] 到
s
[
j
−
1
]
s[ j - 1 ]
s[j−1] 中每个字符串出现的次数,因为
s
[
j
−
k
−
2
]
s[ j - k - 2]
s[j−k−2] 对计算
s
[
j
]
s[ j ]
s[j] 的结果没有贡献,如果不清除其影响反而会影响结果,因此需要先消除其影响,直接在
m
p
[
]
mp[ ]
mp[] 中把
s
[
j
−
k
−
2
]
−
−
s[ j - k - 2 ]--
s[j−k−2]−− 即可,那么和当前字符串相同且间隔不超过
k
k
k 且位于该字符串前面的字符串的个数为
m
p
[
s
[
i
]
]
mp[ s[ i ] ]
mp[s[i]],在后续的计算中,如果有字符串
s
[
p
]
s[ p ]
s[p] 和
s
[
i
]
s[i]
s[i] 相同,则
s
[
p
]
s[p]
s[p] 的结果需要多加一次
s
[
i
]
s[i]
s[i] 所造成的影响,因此
m
p
[
s
[
i
]
]
+
+
mp[ s[ i ] ]++
mp[s[i]]++,后续也会同上一样被消去的
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int n, k;
const int N = 1e5 + 10;
string s[N];
map<string, int > mp;
int main(){
freopen("in.in", "r", stdin);
freopen("out.out", "w", stdout);
ios::sync_with_stdio(false);
cin >> n >> k;
for (int i = 1; i <= n; i++){
cin >> s[i];
}
ll ans = 0;
/*
* mp[i] 表示 s 前面与 s 间隔 k 个之内 满足题设的个数
* 明显答案就是 mp[i]的累加和
* 当计算到 mp[i] 的时候 此时 mp[] 中存放的是 [i - k - 2, i - 1] 中每个字符串出现的次数
* 计算 mp[i] 不需要 mp[i - k - 2] 的值 需要去除它对答案的影响 因此 mp[i - k - 2]-- 将该字符串移除
* 此后 mp[i] 将影响后续 mp[i + 1, i + k + 1] 的答案 因此 mp[i]++ 表示该字符串在当前区间内多出现了一次
* 不得不说 这个算法设计的相当巧妙
*
*/
for (int i = 1; i <= n; i++){
if (i - k - 2 >= 1)mp[s[i - k - 2]]--;
ans += mp[s[i]];
mp[s[i]]++;
}
cout << ans << "\n";
return 0;
}














 3997
3997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









