







文章目录
一:保存、读取模型参数指令
import torch
def model():
...
net = model()
net.train()
torch.save(net, './model')
torch.save(net.state_dict(), './model_state_dict')
torch.save({'epoch': epochID + 1, 'state_dict': model.state_dict(), 'best_loss': lossMIN,
'optimizer': optimizer.state_dict(),'alpha': loss.alpha, 'gamma': loss.gamma},
'./model_multi_params'
)
net2 = torch.load('./model')
net3 = model()
net3.load_state_dict(torch.load('./model_state_dict'))
#torch.load等一系列操作都是用来加载模型、模型参数等类似的文件
二:专业展示网络结构的方式
from torchsummary import summary
def model():
pass
model = model()
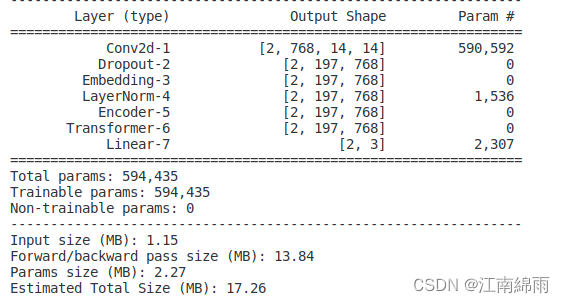
summary(model,input_size=[(3, 224, 224)], batch_size=2, device="cpu")
注意device='cpu'不能不写,否则会报错。打印结果如下图:
三:.npy文件的读取
np.save生成的文件后缀都是.npy,若用来保存pytorch模型的输出特征,需要先从GPU切换到CPU,然后才能有效执行np.save,生成.npy文件。
下面将VIT比较少见的.npy格式模型参数加载,并选择性的放入模型中:
【setp1】看一看长啥样

打印出的结果:

【step2】看一看VIT源码中的加载方法



可见,基本思路就是先打印出预训练模型的参数,对照着想用的模块名称,用copy_覆盖掉当前模型的对应模块的参数,即可!(注意numpy和torch的格式转换)
四:模型预训练参数的各种哦融合方法
- 两个模型参数不一致,只想加载一致的且属于backbone的模型参数
pretrained_dict = torch.load(pretrained_model)
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if (k in model_dict and 'Prediction' not in k)}
model_dict.update(pretrained_dict) #更新
model.load_state_dict(model_dict)
- 大模型加载到小模型、小模型加载到大模型、不一致的模型参数曲一致的互融
model_A.load_state_dict(model_B_state_dict, strict = False)
详情可看:
1.讨论Pytorch中模型加载时参数不一致的情况
2.Pytorch加载预训练模型小结
五:torch.load()的参数细节
torch.load(f, map_location=None, pickle_module=pickle, **pickle_load_args)
对于cpu、不同gpu之间版本的转换而言,map_location参数决定了它。
使用方法如下:
model_path = "./cuda_model.pth"
model = torch.load(model_path)
print(next(model.parameters()).device)
结果为:
cuda:0
model_path = "./cuda_model.pth"
model = torch.load(model_path, map_location=torch.device('cpu'))
#或者 model = torch.load(model_path, map_location={'cuda:0':'cpu'})
#类似的也可以在不同gpu间转换 model = torch.load(model_path, map_location={'cuda:0':'cuda:1'})
print(next(model.parameters()).device)
结果为:
cpu














 1194
1194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









