







大家好,最近呢我对并发编程展现出了兴趣(没办法,别人都会你不会说不过去啊),然后我就要奋发图强学好并发编程,那么接下来让我们一起进入学习吧。今天我们来学习一下线程安全性之原子性
我们一直在说线程安全,线程安全,那么他的定义是什么呢?
1、线程安全性定义
线程安全性定义:
当多个线程访问某个类的时候,不管运行时环境采用 何种调度策略或者这些进程将如何交替执行 ,并且在主调用代码中 不需要任何额外的同步或者协同 ,这个类都能表现出 正确的行为 ,那么就称这个类是线程安全的。
三大特性:
原子性:提供了互斥访问,同一时刻只能有一个线程对他进行操作。
可见性:一个线程对主内存的修改可以及时的让其他线程观察到(MESI加总线嗅探机制)。
有序性:一个线程观察其他线程中的指令执行顺序,由于cpu的指令重排优化,该观察结果一般杂乱无序。
2、Atomic
2.1 AtomicInteger
提起原子性,我们不得不提到JDK为我们提供好的Atomic类,他们都是通过CAS来完成原子性的。
我们为了更好的理解他的功能,我们来进行代码演示一些不是原子性操作的类。
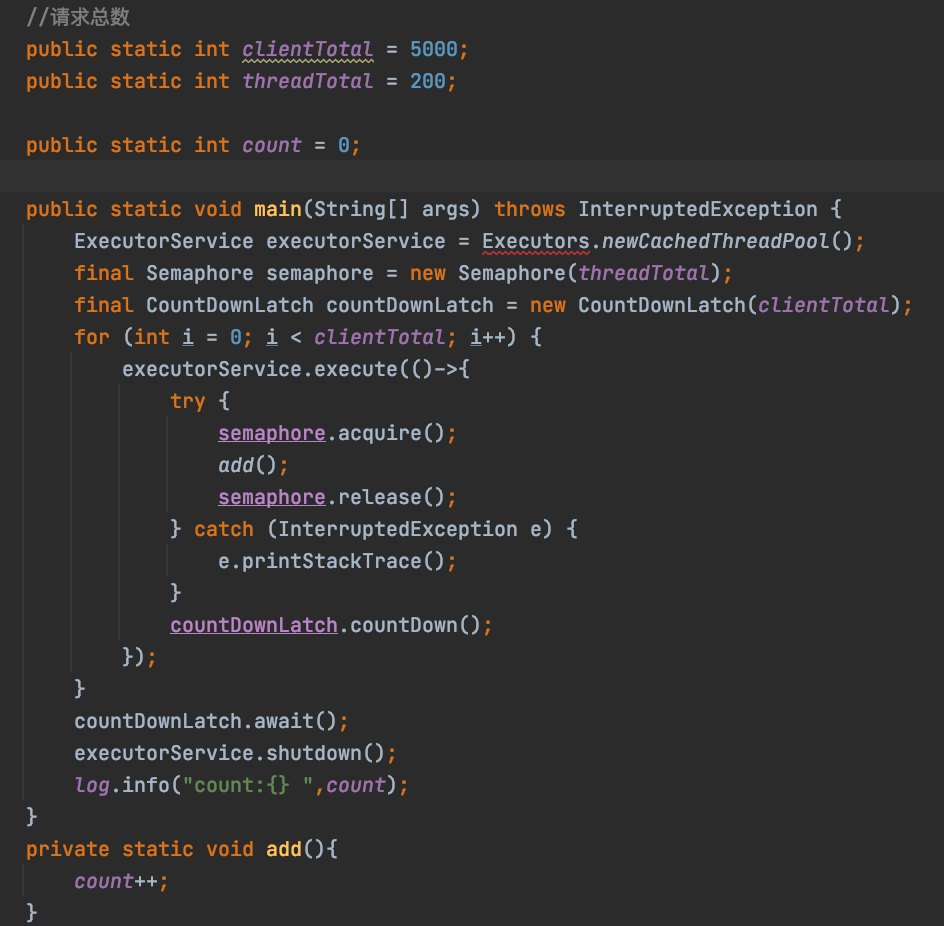
我们看看我上面写的代码,我们定义了用户数为5000,并发为200。我们使用Semaphore和CountDownLatch来实现的。那么我们知道上述代码的答案吗?我相信大家知道,上述方案不是线程安全的,所以执行结束后打印的count不会是5000,那么我们知道volatile可以保证内存可见性,那么我们加上试一下。
public static volatile int count = 0;
那么我们加上volatile关键字,大家知道执行结果是多少吗?
答案是 小于等于5000,可能大家对这个结果不理解,为什么会这样,不是保证内存可见了吗。其实确实保证内存可见了,但是count++,不是原子性操作,相当于先赋值再加1,是两步操作。这样的时候就会出现问题,这也就是为什么volatile的特性有不保证原子性。我们使用Atomic类可以解决这个问题,因为它是原子性操作。
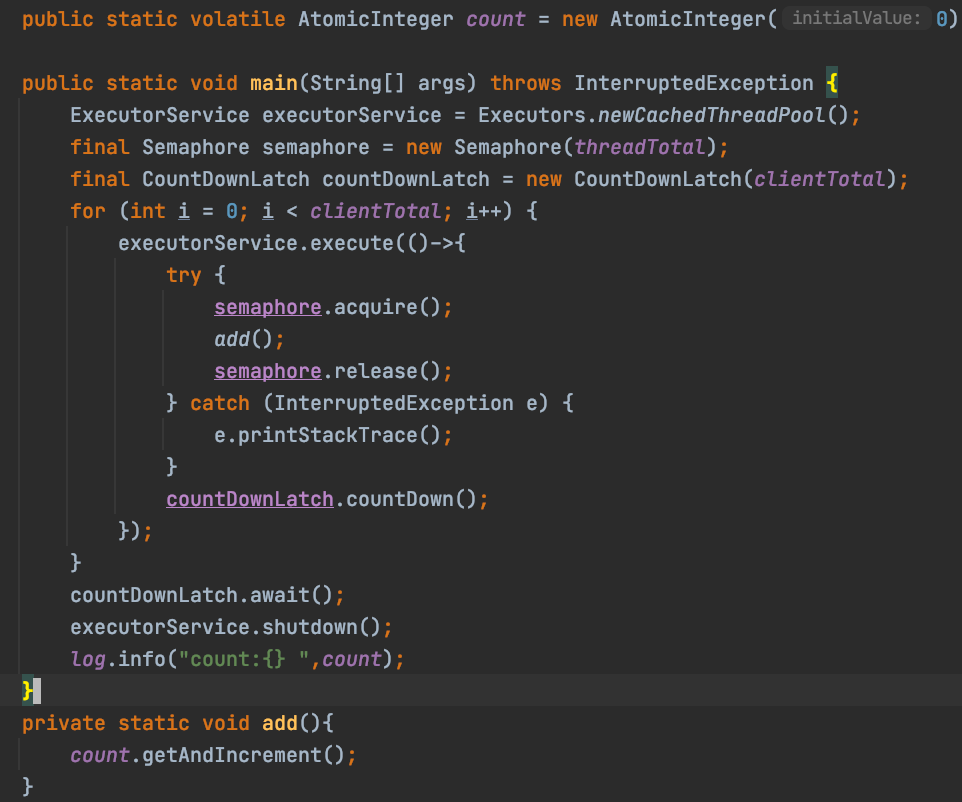
那么他为什么可以保证原子性呢,接下来我们看看getAndIncrement()方法都干了什么。
private static void add(){
//调用 getAndIncrement()
count.getAndIncrement();
}
public final int getAndIncrement() {
//调用 unsafe 类的getAndAddInt 方法,将自身引用,以及值,还有相加的1传递进去了
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
我们着重的看一下getAndAddInt这个方法,方法参数中第一个参数代表的是当前类的引用,第二个参数代表当前的值,第三个参数代表要加多少。
首先定义一个var5的变量,然后从主存中获取值,接着走do while循环。其中有个很重要的方法,也就是compareAndSwapInt,比较然后替换。这个方法的意思也就是说。我拿我当前值和内存中的值进行比较。如果一只则添加,如果不一致则继续比较从内存拿值,等到一致的时候,则添加返回。
我们看这个compareAndSwapInt的方法名的首字母。我们可以看出来,其实这就是CAS!
2.2 AtomicLong
AtomicLong这个类和AtomicInteger使用方式是一样的,我们来看一下例子:
//请求总数
public static int clientTotal = 5000;
public static int threadTotal = 200;
public static AtomicLong count = new AtomicLong(0);
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{} ",count);
}
private static void add(){
count.getAndIncrement();
}
我们现在就是使用了AtomicLong 是可以保证原子性的。
那么他的底层实现呢
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
我们可以明显的看到也是使用了CAS逻辑算法。
2.3 LongAdder
比如我是做大数据实时处理平台的,经常会遇到在flink中统计某一个组件的进入数据的数量处理的数量,以及没有校验通过的数量,这个时候呢,我们经常会遇到求总量的需求,这个时候我们可以采用LongAddr,这个是在java 1.8 之后产生的。
我们来看一下,样例代码:
//请求总数
public static int clientTotal = 5000;
public static int threadTotal = 200;
public static LongAdder count = new LongAdder();
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{} ",count);
}
private static void add(){
count.increment();
}
我们可以看到在使用上仅仅有了一点点的差别,那么为什么会出现这个LongAdder呢,因为在使用AtomicLong的时候,假如出现资源竞争激烈的情况下,就会出现频繁的去内存获取值,然后进行计算和替换,那么这个时候,就会造成性能影响。
在LongAdder中就不会出现这个问题。其实呢在jdk中,对于普通的double变量和long变量,jvm允许将一个64位的读操作或者写操作拆分成两个32位的操作。
那么LongAdder的核心思想是什么呢,将热点数据分离,也就是说,其实大概意思就是将他本身的值给做成了一个数组,然后线程来了,hash到某个点上进行更新,最终的值就是累计求和的结果,但是这个也会出现一个问题,那么就是在高并发频繁更新的时候,有可能会导致数据有一些误差。
2.4 AtomicBoolean
这个类呢我也就不做代码演示了,我们看一下底层的逻辑即可:
public final boolean compareAndSet(boolean expect, boolean update) {
int e = expect ? 1 : 0;
int u = update ? 1 : 0;
return unsafe.compareAndSwapInt(this, valueOffset, e, u);
}
我们看这个方法,其实逻辑的底层是将我们的boolean类型转换成了我们的int类型来进行计算,并且使用了unsafe类的casInt方法。
2.5 AtomicReference
我们来看看他的使用
private static AtomicReference<Integer> count = new AtomicReference<>(0);
public static void main(String[] args) {
count.compareAndSet(0,1);
count.compareAndSet(0,1);
count.compareAndSet(1,3);
log.info(String.valueOf(count.get()));
}
我们可以看到和Atomic的其他类使用方式类似,将一个引用对象包装为原子性。
2.6 ABA问题
其实我们在这里就可以发现一个问题,这个问题是什么呢,也就是假如我的初始值是0,我就修改为1,假如我的初始值是1,我就修改为0,这个时候中间的值发生了变化,假如有其他线程在用这个值的时候,其中做了变化,但是其他人不知道,这个也就是CAS的ABA问题。
解决这个问题也就是加版本的问题,例如我更新为0,那么就是0版本,改成2就是1版本以此类推,类似这样的操作是可以解决ABA问题的。只要修改过,就发生变化。
2.7 AtomicStampedReference
这个类的出现,就是为了解决ABA问题。
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
例子也就不举了,但是这里我们看到他新增了一个版本的比较。
3、总结
1、我们介绍了一些Atomic包下面的CAS原理,也就是Unsafe.compareAndSwapXXX,他的核心原理就是比较然后替换。
2、接着我们看了AtomicLong和LongAdder,在高并发情况不是那么多的时候,可以使用LongAdder增加运行效率。
3、ABA问题也就是在我们的多线程下,对值进行修改后,又恢复原值,其他线程并不会知道其中的更新过程,这个也就是ABA问题。
4、为了解决CAS的ABA问题,也就有了AtomicStampReference,这个类是借助于版本号比较。
好了,谢谢大家的观看,我是胖子,一个热爱学习的码畜。














 5140
5140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









