






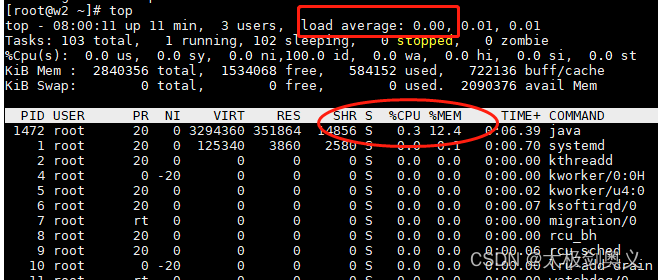
top查看java进程cpu使用率
cpu使用率过大(正常使用率为60%左右),确认负载load值是否比较高(超过cpu核心数,即较高),如果很高,说明有大量线程排队,如果load比较低,但是cpu很高,说明系统运行比较流畅,只是业务比较繁忙。
- cpu使用率:cpu使用的百分比
- 负载load值:等待cpu的进程数
查看具体线程的cpu使用率
- top -H -p <pid>
查看进程下所有的线程,如果几个线程一直占用cpu接近100%,说明这个线程可能循环执行业务或者持续做fgc。
如果线程都是平均的受用cpu,说明线程在繁忙执行业务引起的。
也可以通过arthas工具,快速的检查具体线程执行:
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar <pid>
然后输入dashboard命令查看具体线程执行情况
检查jvm gc状况
- jstat -gc pid
通过jstat命令监控GC情况,观察Full GC情况。一般的,Full GC会引起cpu占用率超高,但是不会接近全部占用掉(如4核心,最高会接近400%)
尝试增加内存:
-Xmx8g -Xms8g
-Xmx16g -Xms16g
Full GC少了,但是cpu还是使用较高。
定位业务代码问题
- top -H -p <pid> 来查看该进程中有那些线程cpu过高(一般超过80%就是比较高)
- 通过线程id的16进制,用于在jstack日志中查找对应的堆栈信息:printf “%x\n” <threadid> 如:5d3
- jstack <pid> > jstack.log ,grep ‘5d3’ jstack.log
- 检查有没有lock 和block:grep BLOCK jstack.log -C 20
通过BLOCK的线程,找到阻塞原因。
由于业务代码出现了synchronized,观察发现会产生较大的对象,造成jvm在短时间内穿件大量的临时对象,并发量一上来,就导致了大量的gc
定位到具体方法后,使用arthas 跟踪方法执行时间
trace com.xxx.xxx.xxx.xxx.freeResourceQuery.FreeResourceQueryActionImpl queryFreeRes
定位到耗时较长的方法
调整gc
将垃圾收集器调整CMS到G1
CMS虽然并发收集低停顿,但是有三个明显的缺陷
- mark sweep算法会导致内存碎片比较多
- CMS的并发能力比较依赖与cpu资源,并发回收垃圾时,收集垃圾线程可能占用用户线程的资源,导致用户程序性能下降。
- 并发清除阶段,用户线程依旧在执行,会产生所谓的“浮动垃圾”,本次垃圾收集无法处理浮动垃圾,需要到下一次次啊能处理。如果浮动垃圾太多,会触发新的垃圾回收,导致性能降低。如果因为内存碎片过多二导致压缩任务不得不执行,那么stop-the-world的时间比其他任务gc类型都长,需要考虑压缩任务在发生频率以及执行时间
设置g1
-Xmx32g -Xms 32g -Xss512k -XX:+UseG1GC -XX:PermSize=256m -XX:+PrintGCDetails
使用G1收集器替换CMS的理由:
- G1最大的好处是性能:由于它高度的并行化,因此在应用停止时间这个指标上比其他的gc算法都要好。
- 我们应用的对象分配比率在短时间内显著的提升变化,使用G1减少内存碎片。由于内存块比较小,进行内存压缩整理的代价压缩整理的代价比较小,相比其他GC算法,可以有效的规避内存碎片的问题。
- G1比较合适内存比较大的应用,一般来说至少6G以上。
使用arthas精确定位
arthas常用命令
- dashboard:当前系统的实时数据面板
- thread:查看当前JVM的线程堆栈信息
- jvm:查看当前jvm的信息
- sc:查看jvm已加载的类信息
- sm:查看已加载类的方法信息
- jad:反编译指定已加载类的源码
- classloader:查看classloader的继承树,urls 类的加载信息,使用class拉的人去getResource
- monitor:方法执行监控
- watch:方法执行数据观测
- trace:方法内部调用路径,并输出方法路径上的每个节点上耗时
- stack:输出当前方法被调用的调用路径
- tt:方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调进行观测
- reset:重置增强类,将被arthas增强过的类全部还原
- quit:退出arthas客户端,其他arthas客户端不会受到影响
- shutdown:关闭所有arthas服务端,所有arthas客户端全部关闭
trace追踪耗时
使用trace时跟踪业务代码之外的函数方法耗时是比较高效的办法。业务代码耗时一般通过链路跟踪就能反馈出来。
问题:
- 浏览器访问接口耗时较长,通过浏览器F12查看接口调用耗时
- 通过controller打印耗时做对比,是否存在差异较大的情况
- 通过上游服务(调用方)观察调用链耗时部分。
- 确定是否由于某个方法还是下游链调用缓慢问题
- 可能是由于网络流读取
抓包分析
安装tcpdump
yum -y install tcpdump
本机服务抓包
tcpdump -i any 8080 -n -X -s 0 -w tcp.cap
访问接口如:
curl http://172.0.0.1:8080/test
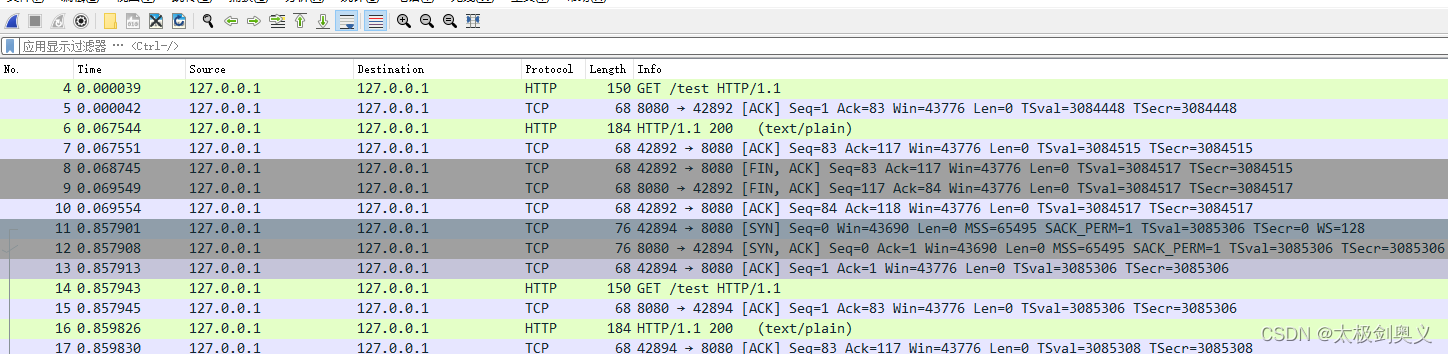
使用wireshark查看 tcp.cap文件
通过127.0.0.1访问服务相当于本机进程通信不走网卡,所以几乎没有网络耗时,如果http请求耗时很低,说明问题的原因时网络问题,如果耗时很长,说明时spring boot服务问题
- 从框架层面处理
trace org.springframework.web.servlet.FrameworkServlet processRequest
跟着调用时间较长的方法一直跟踪。
定位到由于大对象序列化时,耗时较长
处理方法
1、精简序列化字段,将不需要的字段去除掉
2、使用fastjson序列化成String,返回出去,跳出框架使用的序列化,或者直接使用fastjson覆盖序列化方式。















 4994
4994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









