







MYSQL
常用的SQL思路归类
1. 分组取TOP N条记录
思路:利用开窗函数排名(不支持开窗函数可自定义变量实现)
ROW_NUMBER()over() :生成密集不重复序号:1,2,3,4,5
rank()over():不密集有重复 1,1,3,4,5
dense_rank()over():密集有重复 1,1,2,3,4
示例:
leetcode直达
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
Department 表包含公司所有部门的信息。
| Id | Name |
|---|---|
| 1 | IT |
| 2 | Sales |
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
解释:
IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
代码:
# 通过开窗函数
select
Department,
Employee,
Salary
from
( select
a.Name as Employee,
b.Name as Department,
Salary,
dense_rank()over(partition by DepartmentId order by Salary desc) as rank1
from Employee a
inner join Department b
on a.DepartmentId = b.Id) tmp
where tmp.rank1<=3
# 通过变量的方式
select
a.Name as Employee,
b.Name as Department,
Salary
from (
select
DepartmentId,
Name,Salary,
@r := case when @DepartmentId != DepartmentId then 1 when @Salary = Salary then @r else @r :=@r + 1 end as rank1,
@Salary := Salary,
@DepartmentId := DepartmentId
from Employee a,
(select @r := 0,@Salary := null,@DepartmentId := null) b order by DepartmentId,Salary desc) tmp
join Department b
on tmp.DepartmentId = b.Id
where rank1 <= 3
2.分组累计(要加方法2)
思路:自关联并按照条件排序,然后判断是否为同一组数据,进行相加
示例:
| userId | visitDate | visitCount |
|---|---|---|
| u01 | 2017/1/21 | 5 |
| u02 | 2017/1/23 | 6 |
| u03 | 2017/1/22 | 8 |
| u04 | 2017/1/20 | 3 |
| u01 | 2017/1/23 | 6 |
| u01 | 2017/2/21 | 8 |
| u02 | 2017/1/23 | 6 |
| u01 | 2017/2/22 | 4 |
要求使用SQL统计出每个用户的累积访问次数,如下表所示:
| 用户id | 月份 | 小计 | 累积 |
|---|---|---|---|
| u01 | 2017-01 | 11 | 11 |
| u01 | 2017-02 | 12 | 23 |
| u02 | 2017-01 | 12 | 12 |
| u03 | 2017-01 | 8 | 8 |
| u04 | 2017-01 | 3 | 3 |
代码实现一:
#使用自定义变量实现
with a as
(select userid,visitdate,date_format(visitdate,"%Y-%m") as fdate,sum(visitCount) as group_sum from ms_sql1
group by userid,date_format(visitdate,"%Y-%m") order by userid,visitdate)
select userid as "用户id",fdate as "月份",group_sum as "小计",hj as "累计" from
(select userid,fdate,group_sum,
@r:= case when @id!=userid then group_sum else @r+group_sum end hj,
@id := userid,
@dt:=fdate from a,
(select @r:=0,@id:=0,@dt:=null) b order by userid,fdate) tmp
代码实现二:
with tmp as (
select userid,visitdate,date_format(visitdate,"%Y-%m") as fdate,sum(visitCount ) as group_sum from ms_sql1
group by userid,date_format(visitdate,"%Y-%m") order by userid,visitdate)
select
userid,
fdate,
group_sum,
(select sum(group_sum)
from tmp b
where b.userid=tmp.userid and b.fdate<=tmp.fdate)
from tmp
order by userid,visitdate
3.连续问题
思路:利用开窗函数lead(),lag(),row_number()先构造一列数据,再计算需求列与新构造列的关系(比如 构造列-需求列=1)通过where过滤出数据
4.行转列
思路:通过sum(case when)、sum(if())函数
分数表:
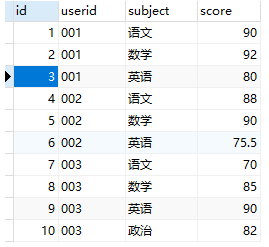
行转列后输出:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OMjJtCbv-1616222534789)(C:\Users\mgxx\AppData\Roaming\Typora\typora-user-images\image-20210306174218212.png)]](https://img-blog.csdnimg.cn/20210320144323771.png)
建表并插入数据:
DROP TABLE IF EXISTS tb_score;
CREATE TABLE tb_score(
id INT(11) NOT NULL auto_increment,
userid VARCHAR(20) NOT NULL COMMENT '用户id',
subject VARCHAR(20) COMMENT '科目',
score DOUBLE COMMENT '成绩',
PRIMARY KEY(id)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
INSERT INTO tb_score(userid,subject,score) VALUES ('001','语文',90);
INSERT INTO tb_score(userid,subject,score) VALUES ('001','数学',92);
INSERT INTO tb_score(userid,subject,score) VALUES ('001','英语',80);
INSERT INTO tb_score(userid,subject,score) VALUES ('002','语文',88);
INSERT INTO tb_score(userid,subject,score) VALUES ('002','数学',90);
INSERT INTO tb_score(userid,subject,score) VALUES ('002','英语',75.5);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','语文',70);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','数学',85);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','英语',90);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','政治',82);
实现代码一:
SELECT userid,
SUM(CASE `subject` WHEN '语文' THEN score ELSE 0 END) as '语文',
SUM(CASE `subject` WHEN '数学' THEN score ELSE 0 END) as '数学',
SUM(CASE `subject` WHEN '英语' THEN score ELSE 0 END) as '英语',
SUM(CASE `subject` WHEN '政治' THEN score ELSE 0 END) as '政治'
FROM tb_score
GROUP BY userid
解释:
SUM() 是为了能够使用GROUP BY根据userid进行分组,因为每一个userid对应的subject="语文"的记录只有一条,所以SUM() 的值就等于对应那一条记录的score的值。
假如userid =‘001’ and subject=‘语文’ 的记录有两条,则此时SUM() 的值将会是这两条记录的和,同理,使用Max()的值将会是这两条记录里面值最大的一个。但是正常情况下,一个user对应一个subject只有一个分数,因此可以使用SUM()、MAX()、MIN()、AVG()等聚合函数都可以达到行转列的效果。
实现代码二:动态转换
SET @EE='';
select @EE :=CONCAT(@EE,'sum(if(subject= \'',subject,'\',score,0)) as ',subject, ',') AS aa FROM (SELECT DISTINCT subject FROM tb_score) A ;
SET @QQ = CONCAT('select ifnull(userid,\'TOTAL\')as userid,',@EE,' sum(score) as TOTAL from tb_score group by userid WITH ROLLUP');
PREPARE stmt FROM @QQ;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
STINCT subject FROM tb_score) A ;
SET @QQ = CONCAT(‘select ifnull(userid,‘TOTAL’)as userid,’,@EE,’ sum(score) as TOTAL from tb_score group by userid WITH ROLLUP’);
PREPARE stmt FROM @QQ;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









