







目录
————————————————————————————————————————
搭建前的准备
一台在虚拟机上完成网络配置且连上网络的CentOS7作为master,如果还没配置好,点击这里查看并完成。
进入实验
关闭防火墙
以下是centOS7关闭防火墙的命令,另外假如是centOS6的小伙伴请看这里centOS6 关闭命令
查看防火墙状态:
firewall-cmd --state
查看的结果显示:如是关闭状态:not running ;如是启动状态:running。
关闭防火墙:
systemctl stop firewalld
启动防火墙:
systemctl start firewalld
安装JDK并配置环境
- 在这里我们的master是完成网络配置的了,我们可以搜索并下载自己需要的应用。以下指令是搜索JDK的指令,在命令行直接键入就可以。
yum search jdk
执行命令后会出现好多结果,那么我们应该怎么选择呢?
我们首先是选择jdk1.8的版本啦,还有就是开发环境(Development Environment),所以选择下图的版本:
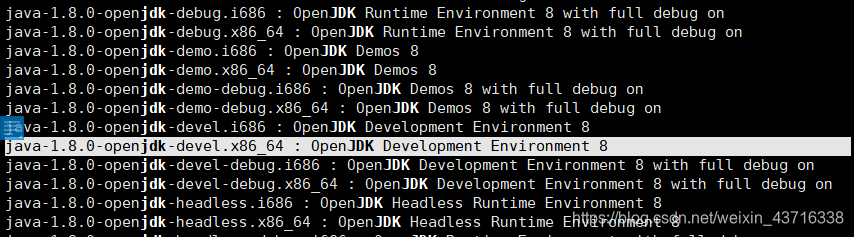
- 找到之后把“:”前的版本名字复制下来(现在用XShell连接了,方便操作),然后用来执行以下命令下载并安装:
yum install java-1.8.0-openjdk-devel.x86_64
- 完成下载并安装后,查看安装在哪个目录并配置Java环境,以下方法查看jdk路径:
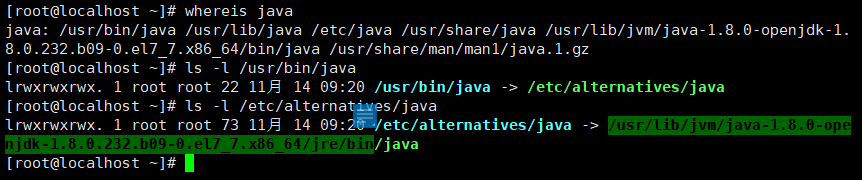
- 首先执行:whereis java;
- 然后ls -l 第一个路径;
- 继续l执行ls -l 第一次 ls 得出的结果路径;
- 最后复制图片选中部分(/bin之前的路径)。
- 用上面复制的路径去配置Java环境,执行下面指令打开配置文件:
vi /etc/profile
打开配置文件后,在末尾添加以下配置环境内容:

然后,执行“Esc+:wq”保存退出。
- 执行以下指令使配置环境生效:
source /etc/profile
对master克隆两份镜像
点击查看我的另一篇克隆记录,在这里只需要克隆两个即可,这里演示是slave1和slave2。
修改克隆镜像的IP地址
因为是对原始主机克隆出来的,ip地址也是一样的,每台机器的ip都不一样的,所以需要进行修改。
进入liunx的网络配置文件进行修改ip,最好是连续的吧,即master的ip的ip是192.168.80.200,那么slave1的就为192.168.80.201,方便记忆;如不知道,具体查看linux网络配置。
修改主机名及映射IP地址
执行“hostname”命令查看主机名,结果如下:

上图是输出默认的主机名,如果在集群里使用这个默认名字会不方便管理,所以我们要修改名字。
详细点击这IP映射主机名。
免密登录
主服务器(master)配置免密登录(SSH)到从服务器(slave1)和从服务器(slave2)。
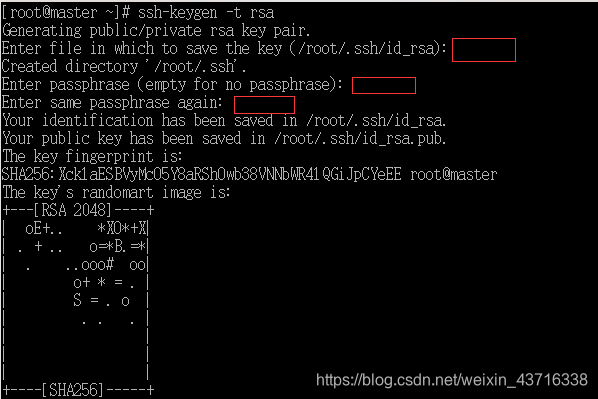
- 主节点(master)机器中创建ssh秘钥,输入如下命令,红框位置直接回车即可。
ssh-keygen -t rsa
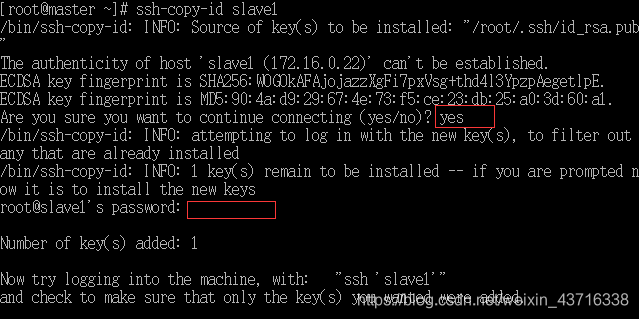
- 将公钥拷贝到从节点1(slave1)机器,第一个红框位置输入yes,第二个红输位置输入root密码。
ssh-copy-id slave1
- 将公钥拷贝到从节点2(slave2)机器, 第一个红框位置输入yes,第二个红输位置输入root密码。
ssh-copy-id slave2
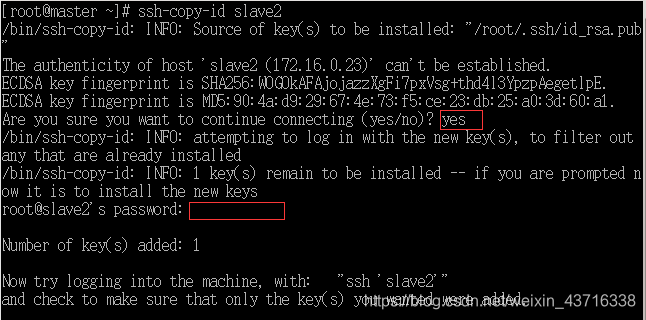
- 同样道理,将公钥拷贝到主节点(master)本机。
ssh-copy-id master
- 验证由主节点(master)机器通过ssh方式免密登录到从节点1(slave1)。
ssh slave1

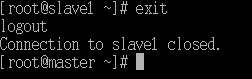
- 退出从节点1(slave1)
exit
- 验证由主节点(master)机器通过ssh方式免密登录到从节点2(slave2)
ssh slave2

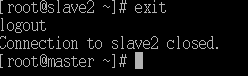
- 退出从节点2(slave2)
exit
- 以上只是实现了由master主机到slave1和slave2免密登录,那么slave1和slave2到master,还有slave1到slave2,这两种情况是还没有实现免密登录的,需要免密登录重复上述步骤就可以啦。
准备所需要的Hadoop安装包
- 用Xshell执行rz指令进行上传即可,然后解压指令:
tar xzvf (.tar.gz后缀名的安装包名) -C 指定解压到的目录
“ -C” 参数:大写,用来指定解压路径目录
在这里,以下就选择解压目录为 /opt
- 修改解压后为文件名为hadoop
mv /opt/hadoop-2.7.4 /opt/hadoop

配置master主机的相关文件
配置/etc/profile环境变量文件
在刚刚配置好的/etc/profile文件末尾加上以下的配置路径:

这里,我的hadoop路径是“/opt/hadoop”,你要寻找你的解压路径在哪了。
然后,按键Esc,按键:wq保存退出,刷新配置文件:
source /etc/profile
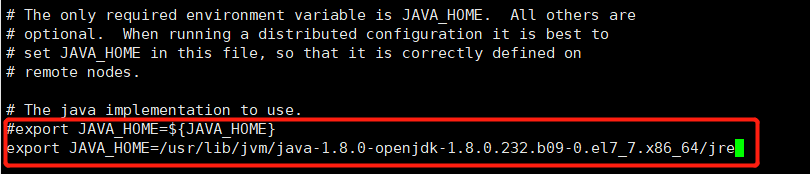
配置/opt/hadoop/etc/hadoop/hadoop-env.sh文件
执行命令打开配置文件:
vi /opt/hadoop/etc/hadoop/hadoop-env.sh
修改配置文件,注释方框里的第一行JAVA_HOME路径默认值,添加自己本机的java路径(可以参考java环境里的路径)。
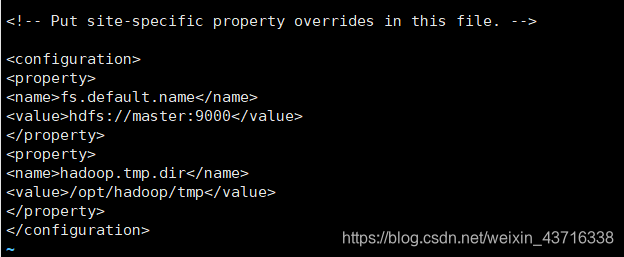
配置/opt/hadoop/etc/hadoop/core-site.xml文件
vi /opt/hadoop/etc/hadoop/core-site.xml
在如下图位置添加以下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
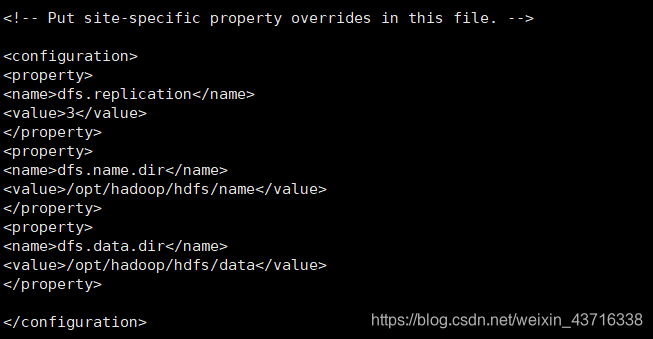
配置/opt/hadoop/etc/hadoop/hdfs-site.xml文件
vi /opt/hadoop/etc/hadoop/hdfs-site.xml
在如下图位置添加以下内容:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hdfs/data</value>
</property>
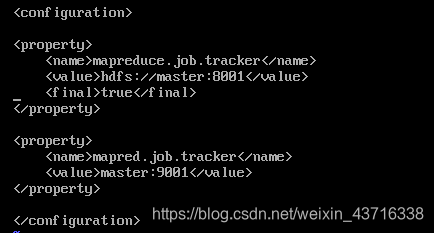
配置/opt/hadoop/etc/hadoop/mapred-site.xml文件
这个文件名的文件是不存在的,需要我们复制/opt/hadoop/etc/hadoop/mapred-site.xml.tmplate 文件改为名为mapred-site.xml 。
cp /opt/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/etc/hadoop/mapred-site.xml
接着编辑/opt/hadoop/etc/hadoop/mapred-site.xml文件,在如下图位置添加以下内容:
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://master:8001</value>
<final>true</final>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
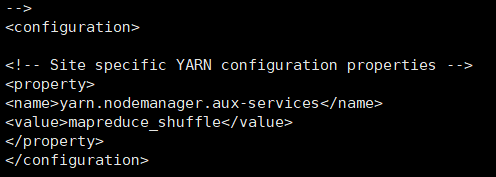
配置/opt/hadoop/etc/hadoop/yarn-site.xml文件
vi /opt/hadoop/etc/hadoop/yarn-site.xml
在如下图位置添加以下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
在如下图位置添加以下内容:
配置/opt/hadoop/etc/hadoop/slaves文件
vi /opt/hadoop/etc/hadoop/slaves
打开后,文件内容如下:

接着,按键dd删除首行,按键i添加如下内容;
slave1
slave2

为什么要这样做呢?很容易理解啦,作为老大的master,当然需要份作为小弟
slave的花名册啦!
拷贝配置文件到从服务器
- 拷贝主节点(master)主机/etc/profile到从节点1(slave1)主机/etc下
scp /etc/profile slave1:/etc

- 拷贝主节点(master)主机/etc/profile到从节点2(slave2)主机/etc下
scp /etc/profile slave2:/etc

- 拷贝主节点(master)主机/opt/hadoop到从节点1(slave1)主机/opt下
scp -r /opt/hadoop slave1:/opt
- 拷贝主节点(master)主机/opt/hadoop到从节点2(slave2)主机/opt下
scp -r /opt/hadoop slave2:/opt
- 切换到从节点1(slave1)机器上,输入如下指令:
source /etc/profile

6. 切换到从节点2(slave2)机器上,输入如下指令:
source /etc/profile

格式化HDFS
切换到主节点(master)机器上,命令行中执行如下指令,格式化hdfs:
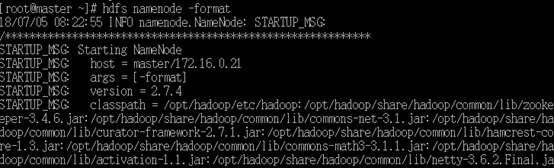
hdfs namenode -format
图片示例:
启动集群并查看进程
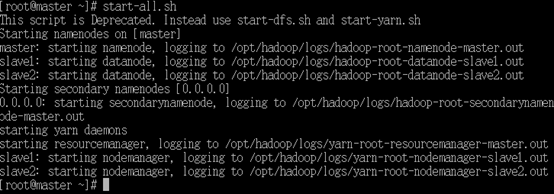
- 主节点(master)机器命令行中执行如下指令,启动集群:
start-all.sh
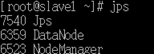
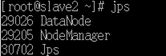
- 主节点(master)机器命令行中执行如下指令,查看进程:
命令“jps”用于查看进程情况
jps
主节点执行命令,进程正常启动:

slave1从节点执行命令,进程正常启动:
slave2从节点执行命令,进程正常启动:
到这里,所有的配置都完成了!
若有不足之处望留言!
——————END———————
Programmer:柘月十七















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









