






一.安装master虚拟机
1.网络配置
ip a 或 ifconfig 查看网络信息
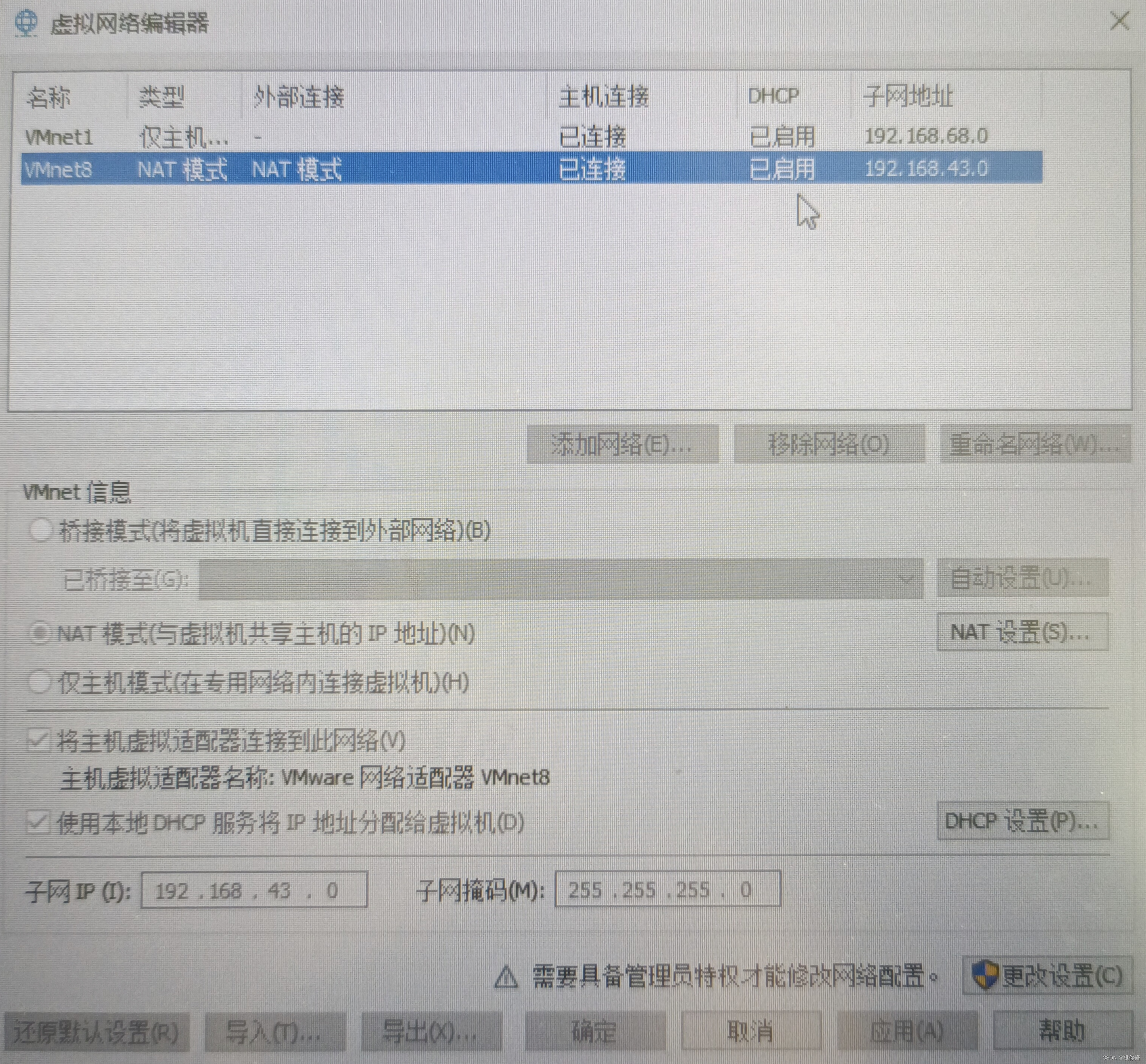
在虚拟网络编辑器中查看IP地址
我的是192.168.43.0
编辑网络配置文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="dhcp"修改为BOOTPROTO="static"
ONBOOT='no'修改为ONBOOT=‘yes'
添加静态设置:
IPADDR=192.168.43.100
NETMASK=255.255.255.0
GATEWAY=192.168.43.2
DNS1=114.114.114.114
重启网卡:systemctl restart network
克隆master虚拟机分别为slave1,slave2.并修改其网络配置文件中的IP地址。
2.修改主机名称及对应关系
修改主机名称:hostnamectl set-hostname 主机名称
查看主机名称:hostname
修改主机名与IP的对应:vi /etc/hosts
192.168.43.100 master
192.168.43.101 slave1
192.168.43.102 slave2
3.关闭防火墙
关闭防火墙:systemctl stop firewalld
永久关闭:systemctl disable firewalld
查看防火墙状态:systemctl status firewalld
4.时间同步设置
时间同步设置:服务器端ntp时间服务器与客户端ntpdate
搜索:yum search ntp
安装:yum install ntp ntpdate
配置:vi /etc/ntp.conf
restrict 192.168.43.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
重启时间服务:systemctl restart ntpd
客户端更新:ntpdate -u master
slave1 slave2 安装客户端:yum install ntpdate
更新时间:ntpdate -u master
5.三台免密操作
ssh-keygen -t rsa -P ''
ssh-copy-id 主机名称
二.hadoop的安装与配置
1.解压
上传hadoop的压缩包:hadoop-2.7.5.tar.gz
上传jdk的压缩包:jdk-8u162-linux-x64.tar.gz
tar -xzvf jdk-8u162-linux-x64.tar.gz -C /opt
tar -xzvf hadoop-2.7.5.tar.gz -C /opt
(这是我用的版本及我安装在了opt目录,根据要求进行更改)
2.改名(便于使用)
mv /opt/jdk1.8.0_162 /opt/jdk18
mv /opt/hadoop-2.7.5 /opt/hadoop
3.环境变量配置
vi /etc/profile
添加:export JAVA_HOME=/opt/jdk18
export HADOOP_HOME=/opt/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
加载环境资源:source /etc/profile
输入:java hadoop 不出错则环境变量配置正确
4.配置hadoop文件
在/opt/hadoop/etc/hadoop目录下
1)vi hadoop-env.sh
export JAVA_HOME=/opt/jdk18(jdk安装目录)
2)vi core-site.xml(核心组件文件) 3)vi hdfs-site.xml(文件系统配置文件)
3)vi hdfs-site.xml(文件系统配置文件) 4)vi yarn-site.xml(yarn的站点配置文件)
4)vi yarn-site.xml(yarn的站点配置文件)
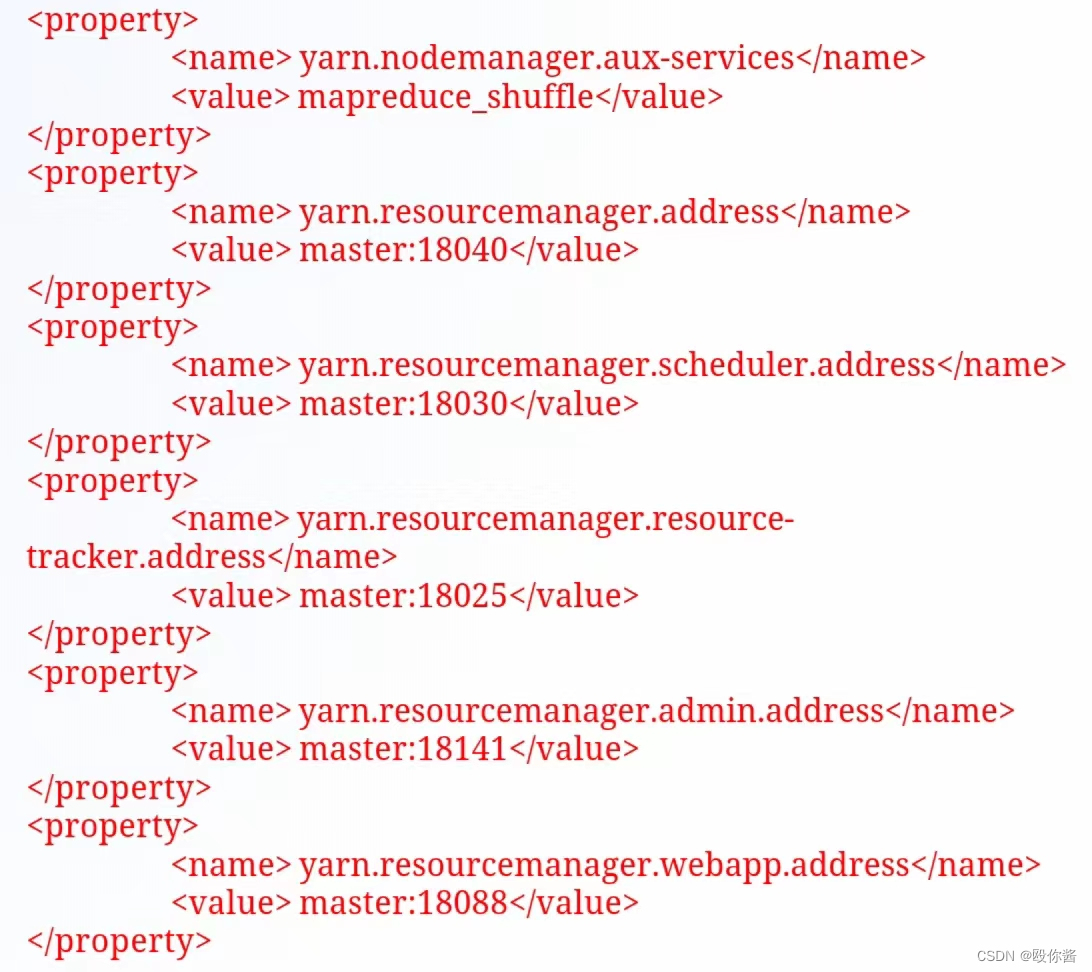
5)cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
6)vi slaves
需要删除原来文件里面localhost那一行
slave1
slave2
5.所有配置文件复制到slave1与slave2
scp -r /opt/* root@slave1:/opt
scp -r /opt/* root@slave2:/opt
scp /etc/profile slave1:/etc
scp /etc/profile slave2:/etc
分别登录slave1与slave2加载环境变量source /etc/profile
6.在master主机中进行格式化:
hdfs namenode -format
出现successfully formatted则格式化成功。
7.在master主机中启动hadoop集群:start-all.sh&&start-yarn.sh
master输入jps出现:ResourceManager NameNode SecondaryNameNode Jps四个进程
slave1与slave2输入jps出现:Jps NodeManager DataNode三个进程则Hadoop启动成功。
8.关闭集群:stop-all.sh















 2966
2966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









