






爬虫并发神器 gevent
gevent协程(单线程,不存在线程间的切换)在遇到io(input,output 网络,文件读写等…)的情况自动切换
aiohttp与gevent属于同类型模块,gevent写法上更简单(个人感觉),这两个就不做比较了
测试前提条件:单核cpu跑满,成功率相近
测试的一些参数,如线程数量,协程每次执行的数量,在保证成功率的情况下都有调整,废话不多说直接上代码,
import gevent
from gevent import monkey
monkey.patch_all()
import requests
import time
import threading
sunNum = 0
failNum = 0
errNum = 0
def GetData(url):
global sunNum, failNum, errNum
try:
resp = requests.get(url, timeout=2)
if resp.status_code == 200:
sunNum += 1
else:
failNum += 1
except:
errNum += 1
startTime = time.time()
geventtask = []
for i in range(5000):
if len(geventtask) >= 500:
gevent.joinall(geventtask)
# print(sunNum, failNum)
geventtask = []
else:
geventtask.append(gevent.spawn(GetData,"https://www.baidu.com/"))
if geventtask:
gevent.joinall(geventtask)
print(sunNum, failNum,errNum)
print("gevent:",time.time()-startTime)
协程访问五千次百度41.5s
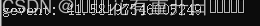
def GetData2(url,num):
global sunNum, failNum,errNum
startTime = time.time()
for i in range(50):
try:
resp = requests.get(url, timeout=2)
if resp.status_code == 200:
sunNum += 1
else:
failNum += 1
except:
errNum += 1
print(num,time.time() - startTime)
tedList = []
startTime = time.time()
for i in range(100):
t = threading.Thread(target=GetData2, args=("https://www.baidu.com/",i))
t.start()
tedList.append(t)
try:
for p in tedList:
p.join()
except Exception as e:
print(str(e))
print(sunNum, failNum, errNum)
print(time.time() - startTime)
线程内部循环总共5000 41.7s

def GetData3(url):
global sunNum, failNum,errNum
try:
resp = requests.get(url, timeout=2)
if resp.status_code == 200:
sunNum += 1
else:
failNum += 1
except:
errNum += 1
tedList = []
startTime = time.time()
for i in range(50):
for i in range(100):
t = threading.Thread(target=GetData3, args=("https://www.baidu.com/",))
t.start()
tedList.append(t)
try:
for p in tedList:
p.join()
except Exception as e:
print(str(e))
print(sunNum, failNum, errNum)
print(time.time() - startTime)
循环开启线程 75.8
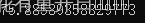
总结: 无io操作(百度首页的网络io)也可忽略的情况 ,协程与在不进行线程重复开启的情况下速度基本一致
测试网络io 更换目标链接"https://httpbin.org/get",其他参数不变

协程65.2s

线程82.5s

速度就明显了
读写的io就不测了,拿数据库操作来说,多线程操作一个游标会报错,需要加锁,或者每个线程一个游标或者数据先放入队列等等,属实有些不太方便;协程是单线程不存在这个情况.
感兴趣的小伙伴也可以自己测试.
纸上得来终觉浅,绝知此事要躬行.















 6680
6680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









