







1、要解决什么问题?
在构建机器学习模型时,训练数据Xs与测试数据Xt的分布不一致。导致我们训练出的模型的鲁棒性变差,并且在测试中可能很难有一个好结果。一般,将训练数据所在的数据域称为源域(surce domain)测试数据所在的数据域称为目标域(target domain)。
2、解决思路?
得到某种映射,使
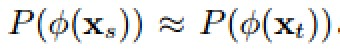
进而,使得两者条件分布相似,即: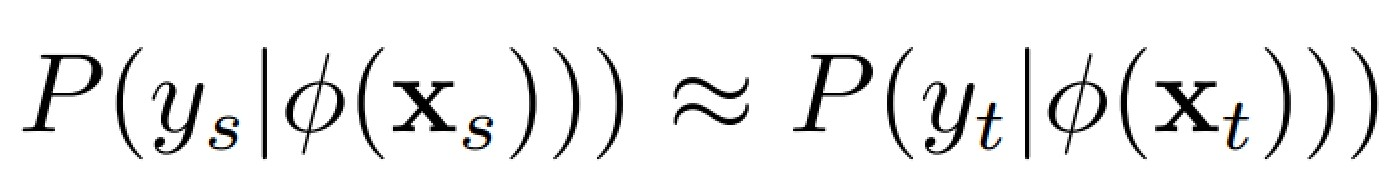
2、如何?
1)衡量两个域的分布距离(两者之间有多不相似)
衡量方法
最大平均差异(maximum mean discrepancy)
参考网上定义为:基于两个分布的样本,通过寻找在样本空间上的连续函数f,求不同分布的样本在f上的函数值的均值,通过把两个均值作差可以得到两个分布对应于f的mean discrepancy。寻找一个f使得这个mean discrepancy有最大值,就得到了MMD。最后取MMD作为检验统计量(test statistic),从而判断两个分布是否相同。如果这个值足够小,就认为两个分布相同,否则就认为它们不相同。同时这个值也用来判断两个分布之间的相似程度。而在迁移学习中,我们这个f一般是用高斯核函数(RBF)
2)最小化分布距离
最小化MMD的过程就是在迫使不同域中样本之间的差异应该保持一致。
如何最小化?
Reference
[1]: https://blog.csdn.net/qq_36375505/article/details/88618837
[2]: https://blog.csdn.net/tunhuzhuang1836/article/details/78058184















 3251
3251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









