






Pytorch 深度学习实践 第9讲kaggle-Otto Group Product Classification Challenge-
数据集在kaggle搜索引擎上查找otto就能出来
本文采用Pytorch进行简单的运算
因为我用的anaconda所以就有分开了代码块,如果用的pycharm的话可以直接跳转到最后
Anaconda的操作方法
首先引入包
import torch
from torch.autograd import Variable
from torchvision import datasets,transforms
from torch.utils.data import Dataset,DataLoader
import pandas as pd
from torch.utils.data import DataLoader#For constructing Dataloader
import torch.nn.functional as F#for using function relu()
import torch.nn as nn
import torch.optim as optim#For constructing Optimizer
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
其次建立对数据的处理
这时候你就应该打开下载的csv文件进行观察了或者直接读入数据然后看看数据类型
数据类型决定了你能不能跑这个程序。
如果是object你就需要替换
然后进行切片即可
数据处理第一种方法就是去csv文件中修改数据类型
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x,y,test_size=0.3)
Xtest = torch.from_numpy(Xtest.values)
Ytest = torch.from_numpy(Ytest)
class Dataset(Dataset):
def __init__(self, data,label):
self.len = data.shape[0] # shape(多少行,多少列)
self.x_data = torch.from_numpy(data.values)
self.y_data = torch.from_numpy(label)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
train_dataset = Dataset(Xtrain,Ytrain)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
我当时这样处理后发现在最后就没办法直接算,总会有runtimeerror于是借鉴了Kaggle的更改方法
数据处理第二种方法就是直接替换
class OttoDataset(Dataset):
def __init__(self):
xy = np.loadtxt('D:/yinlichen/dataset/otto/train.csv',delimiter=',',skiprows = 1, usecols = np.arange(1,94))
df = pd.read_csv('D:/yinlichen/dataset/otto/train.csv', sep = ',')
df['target'] = df['target'].map({'Class_1': 1, 'Class_2': 2,
'Class_3': 3, 'Class_4': 4,
'Class_5': 5, 'Class_6': 6,
'Class_7': 7, 'Class_8': 8,
'Class_9': 9})
df['target'] = df['target'].astype('float64')
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:])
self.y_data = torch.tensor(df['target'].values)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = OttoDataset()
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True)
直接给那个替换了,简单暴力然后进行数据类型转换。
再接着就是大家熟悉的模型建立了
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = nn.Linear(93, 64)
self.l2 = nn.Linear(64,32)
self.l3 = nn.Linear(32,16)
self.l4 = nn.Linear(16,9)
def forward(self,x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
return self.l4(x)
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
然后训练模型嘛
loss = 0
for epoch in range(10):
model.train()
for batch_idx, (data,target) in enumerate(train_loader):
data, target = Variable(data).float(),Variable(target).type(torch.LongTensor)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target-1)
loss.backward()
optimizer.step()
训练完模型以后就开始调整模式了和model.train() 对应的就是model.eval()
model.eval()
xyTest = np.loadtxt('D:/yinlichen/dataset/otto/test.csv',delimiter=',',skiprows = 1, usecols = np.arange(1,94))
df1 = pd.read_csv('D:/yinlichen/dataset/otto/test.csv',sep=',')
xy_pred = torch.from_numpy(xyTest[:,:])
id_col = df1['id']
class_list = ['id','Class_1','Class_2','Class_3','Class_4','Class_5',
'Class_6','Class_7','Class_8','Class_9']
class_list2 = ['Class_1','Class_2','Class_3','Class_4','Class_5',
'Class_6','Class_7','Class_8','Class_9']
d = pd.DataFrame(0, index=np.arange(xy_pred.shape[0]), columns=class_list)
d['id'] = df1['id']
d[class_list2] = d[class_list2].astype('float')
d.dtypes
根据要求类型设置csv输出类型
然后就到了生成csv文件的过程了
classify = 'Class_'
#print(df1.iloc[2,1:])
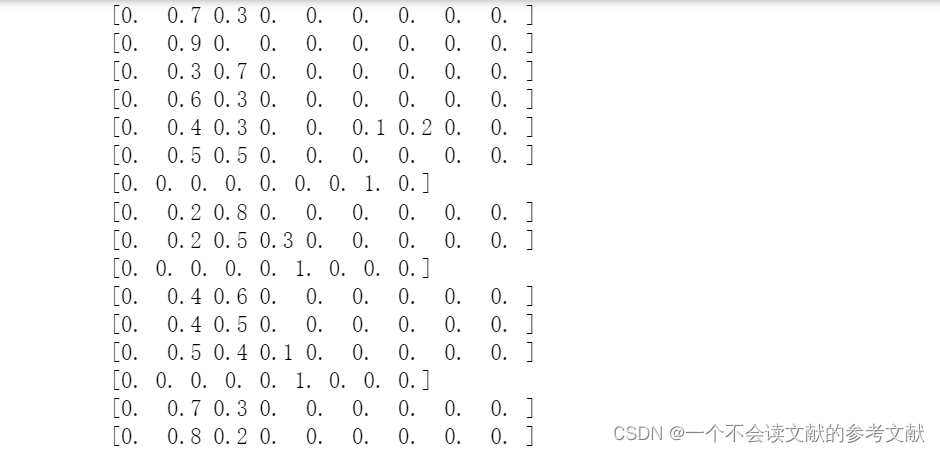
for i in range(xy_pred.shape[0]):
output = model(Variable(xy_pred[i]).float())
row = F.softmax(output).data
classes = row.numpy()
classes = np.around(classes, decimals=1)
print(classes)
d.loc[i,1:] = classes
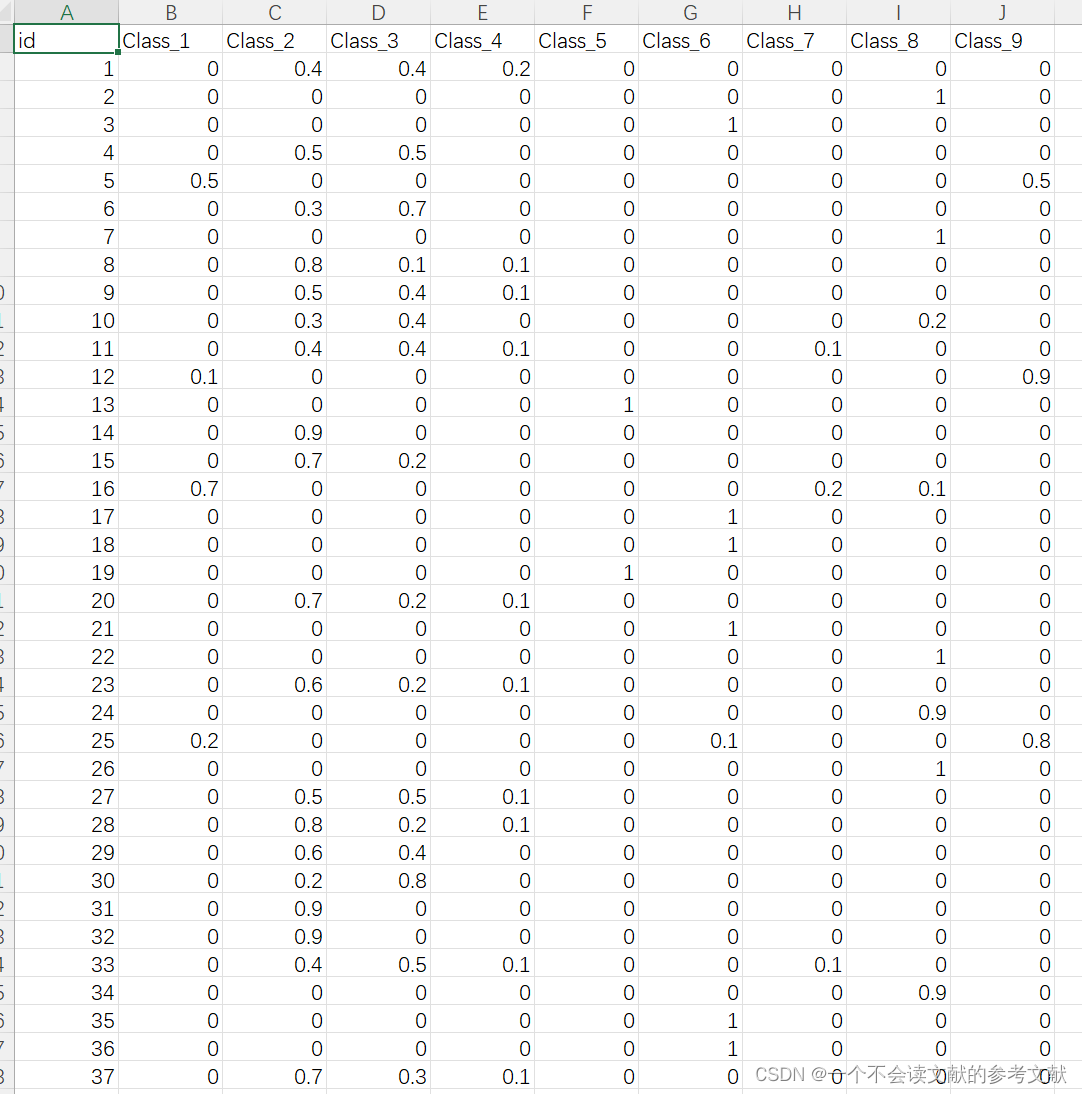
然后就是保存csv
d.to_csv('submission1.csv',index = False)
其实模型都大差不差,问题就在于你怎么做特征工程,有一说一确实不太好做。
Pycharm运行代码
import torch
from torch.autograd import Variable
from torchvision import datasets,transforms
from torch.utils.data import Dataset,DataLoader
import pandas as pd
from torch.utils.data import DataLoader#For constructing Dataloader
import torch.nn.functional as F#for using function relu()
import torch.nn as nn
import torch.optim as optim#For constructing Optimizer
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
class OttoDataset(Dataset):
def __init__(self):
xy = np.loadtxt('D:/yinlichen/dataset/otto/train.csv',delimiter=',',skiprows = 1, usecols = np.arange(1,94))
df = pd.read_csv('D:/yinlichen/dataset/otto/train.csv', sep = ',')
df['target'] = df['target'].map({'Class_1': 1, 'Class_2': 2,
'Class_3': 3, 'Class_4': 4,
'Class_5': 5, 'Class_6': 6,
'Class_7': 7, 'Class_8': 8,
'Class_9': 9})
df['target'] = df['target'].astype('float64')
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:])
self.y_data = torch.tensor(df['target'].values)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = OttoDataset()
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True)
dataset = OttoDataset()
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True)
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = nn.Linear(93, 46)
self.l2 = nn.Linear(46,18)
self.l3 = nn.Linear(18,9)
def forward(self,x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
return self.l3(x)
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
loss = 1000
for epoch in range(10):
model.train()
for batch_idx, (data,target) in enumerate(train_loader):
data, target = Variable(data).float(),Variable(target).type(torch.LongTensor)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target-1)
loss.backward()
optimizer.step()
model.eval()
xyTest = np.loadtxt('D:/yinlichen/dataset/otto/test.csv',delimiter=',',skiprows = 1, usecols = np.arange(1,94))
df1 = pd.read_csv('D:/yinlichen/dataset/otto/test.csv',sep=',')
xy_pred = torch.from_numpy(xyTest[:,:])
id_col = df1['id']
class_list = ['id','Class_1','Class_2','Class_3','Class_4','Class_5',
'Class_6','Class_7','Class_8','Class_9']
class_list2 = ['Class_1','Class_2','Class_3','Class_4','Class_5',
'Class_6','Class_7','Class_8','Class_9']
d = pd.DataFrame(0, index=np.arange(xy_pred.shape[0]), columns=class_list)
d['id'] = df1['id']
d[class_list2] = d[class_list2].astype('float')
classify = 'Class_'
#print(df1.iloc[2,1:])
for i in range(xy_pred.shape[0]):
output = model(Variable(xy_pred[i]).float())
row = F.softmax(output).data
classes = row.numpy()
classes = np.around(classes, decimals=1)
print(classes)
d.loc[i,1:] = classes
d.to_csv('submission1.csv',index = False)
有需要的可以私信联系我
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









