






全卷积神经网络
数据预处理
下载下来的图片杂乱无章所以进行简单的预处理
import os
def myrename(path):
file_list=os.listdir(path)
for i,fi in enumerate(file_list):
old_name=os.path.join(path,fi)
new_name=os.path.join(path,str(i)+".jpg")
os.rename(old_name,new_name)
if __name__=="__main__":
path="D:/yinlichen/dataset/archive/data/cloudy/testing"
#D:\yinlichen\dataset\archive\data\cloudy\cloudy
myrename(path)
具体操作就是修改new_name=os.path.join(path,str(i)+".jpg")和path="D:/yinlichen/dataset/archive/data/cloudy/testing"这两块
因为该数据集没有划分训练集和测试集所以本文自行划分,并将所有数据汇总大抵成为
至此代码外的处理完成,接下来进行数据集的读取与操作
导入包
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
数据读取
然后进行
def readfile(path, label):
image_dir = sorted(os.listdir(path))
x = np.zeros((len(image_dir), 256, 256, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir)
img = cv2.imread(os.path.join(path, file))
x[i, :, :] = cv2.resize(img,(256, 256)
if label:
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
workspace_dir = "D:/yinlichen/dataset/archive/data/cloudy"
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
确定训练集测试集以及真实值的参照,从而用于检测模型建立的成功与否以及方便测试数据的检验
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(32),
transforms.ToTensor(),
])
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
batch_size = 32
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
搭建全连接卷积网络
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 256, 256]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 128, 128]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 128, 128]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 64, 64]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 64, 64]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 32, 32]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 32, 32]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 16, 16]
nn.Conv2d(512, 1024, 3, 1, 1), # [1024,16 , 16]
nn.BatchNorm2d(1024),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [1024, 8, 8]
nn.Conv2d(1024, 1024, 3, 1, 1), # [1024, 8, 8]
nn.BatchNorm2d(1024),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), #[1024, 4, 4]
)
#全连接分类器
self.fc = nn.Sequential(
nn.Linear(1024*4*4,32),
nn.ReLU(),
nn.Linear(32, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256,4)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
def params_count(model):
"""
Compute the number of parameters.
Args:
model (model): model to count the number of parameters.
"""
return np.sum([p.numel() for p in model.parameters()]).item()
如果修改了x[i, :, :] = cv2.resize(img,(256, 256)这一部分要记得修改模型参数,要不然会一直报错。还看不懂,在搭建网络时要记得上下对照,否则就会输入维度与实际维度不符合。
model = Classifier().cuda()
print('params num:', params_count(model))
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_epoch = 30
prediction_val = []
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train()
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
for i, data in enumerate(train_loader):
optimizer.zero_grad()
train_pred = model(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_set.__len__(), train_loss/train_set.__len__(), val_acc/val_set.__len__(), val_loss/val_set.__len__()))
经典老三样:归一,计算optim,带入损失函数。

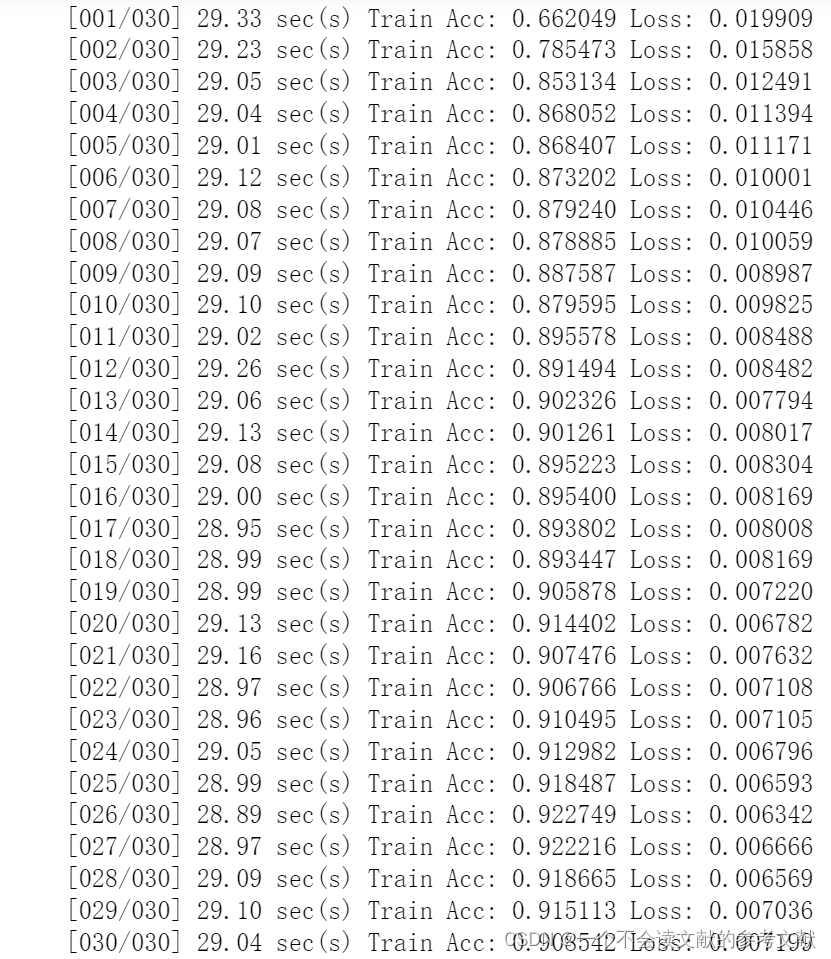
其实25层就可以停止了,我实在是太困了,所以就没有修改参数。他已经出现过拟合了
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
val_label = np.argmax(val_pred.cpu().data.numpy(), axis=1)
for y in val_label:
prediction_val.append(y)
然后就是 带入混淆矩阵中了,我感觉没有什么太大意义,所以就没怎么描述,我感觉就宛如皮尔逊相关系数矩阵一样,啊不对就好像那个seaborn包里的那个拼图一样给大家瞅一眼
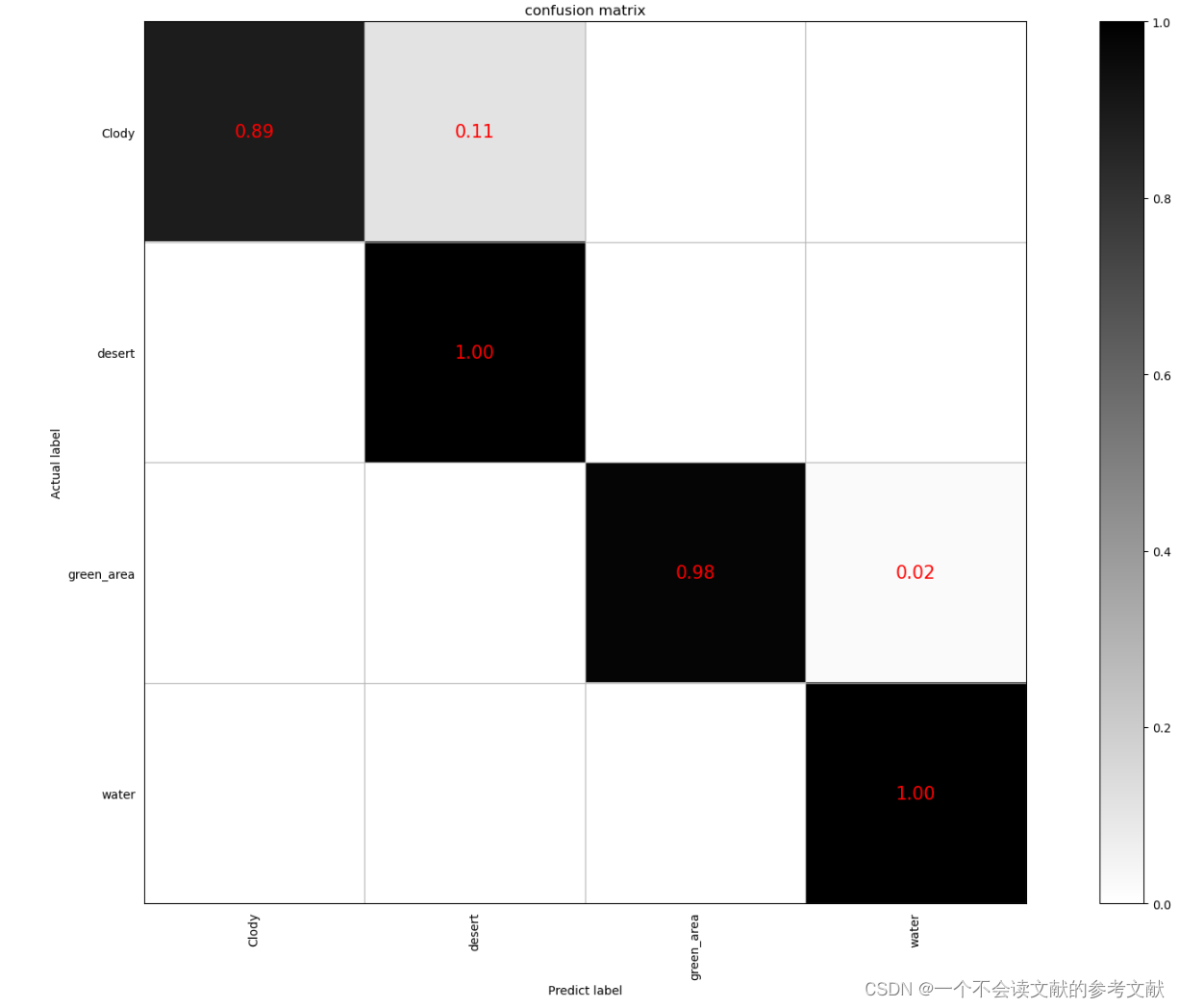
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
classes = ['Clody', 'desert', 'green_area', 'water']
y_true = val_y.copy()
y_pred = prediction_val.copy()
cm = confusion_matrix(y_true, y_pred)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print(cm_normalized)
def plot_confusion_matrix(cm, savename, title='Confusion Matrix'):
plt.figure(figsize=(22, 14), dpi=100)
np.set_printoptions(precision=2)
# 在混淆矩阵中每格的概率值
ind_array = np.arange(len(classes))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.2f" % (c,), color='red', fontsize=15, va='center', ha='center')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.binary)
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation=90)
plt.yticks(xlocations, classes)
plt.ylabel('Actual label')
plt.xlabel('Predict label')
# offset the tick
tick_marks = np.array(range(len(classes))) + 0.5
plt.gca().set_xticks(tick_marks, minor=True)
plt.gca().set_yticks(tick_marks, minor=True)
plt.gca().xaxis.set_ticks_position('none')
plt.gca().yaxis.set_ticks_position('none')
plt.grid(True, which='minor', linestyle='-')
plt.gcf().subplots_adjust(bottom=0.15)
# show confusion matrix
plt.savefig(savename, format='png')
plt.show()
plot_confusion_matrix(cm_normalized, 'confusion_matrix.png', title='confusion matrix')
train_val_x = np.concatenate((train_x, val_x), axis=0)#两个数组拼接
train_val_y = np.concatenate((train_y, val_y), axis=0)
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
model_best = Classifier().cuda()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model_best.parameters(), lr=0.001)
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
然后就保存就行了~~~~~















 2059
2059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









