







VSUM函数向量化
使用NEON intrinsic指令,实现图1所示vsum传统串行函数的向量化
1. serial
#include <iostream>
#include <ctime>
#include <arm_neon.h>
using namespace std;
int vsum(int* vec, int);
int main(){
int n = 10;
int nloops = 10;
int *x = new int[n];
srand(time(NULL));
for (int i = 0; i < n; i++){
x[i] = (int)(rand() % 10);
}
// x[i] = (float)(rand() % 10) + (float)rand() / RAND_MAX;
clock_t t = clock();
for (int i = 0; i < nloops; i ++){
vsum(x, n);
}
t = clock() - t;
std::cout << "axpy ave cost time(clock):" << t / nloops<< std::endl;
}
int vsum(int* vec, int n){
int s = 0;
for (int i = 0; i < n; i ++){
s += vec[i];
}
std::cout << s << std::endl;
return s;
}
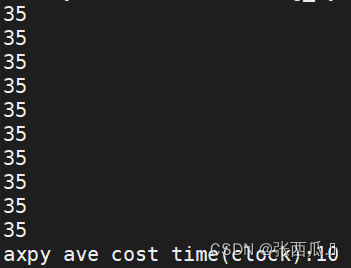
2. parallel
#include <iostream>
#include <ctime>
#include <arm_neon.h>
using namespace std;
int vsum_arm_neon(int* , int );
int main(){
int n = 10;
int nloops = 10;
int *x = new int[n];
srand(time(NULL));
for (int i = 0; i < n; i++){
x[i] = (int)(rand() % 10);
cout << x[i] << ' ';
}
cout << endl;
// x[i] = (float)(rand() % 10) + (float)rand() / RAND_MAX;
clock_t t = clock();
for (int i = 0; i < nloops; i ++){
vsum_arm_neon(x, n);
}
t = clock() - t;
std::cout << "axpy ave cost time(clock):" << t / nloops<< std::endl;
}
int vsum_arm_neon(int* vec, int n){
int32x4_t vx, vs;
int i, s = 0;
vs = vdupq_n_s32(0);
for (i = 0; i < n / 4 * 4; i += 4){
vx = vld1q_s32(vec + i);
vs = vaddq_s32(vs, vx);
}
s = vaddvq_s32(vs);
for (; i < n ; i ++){
s += vec[i];
}
cout << s << endl;
return s;
}
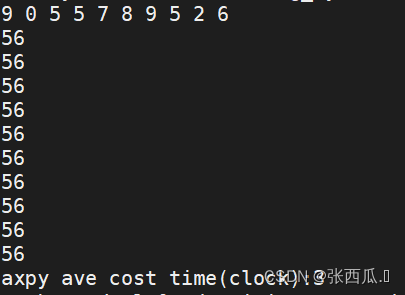
BGRA2RGB
1. serial
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
void bgra2rgb(const uint8_t *src, uint8_t *dst, int w, int h)
{
for (int i = 0; i < h; ++i)
{
for (int j = 0; j < w; j++)
{
dst[(i * w + j) * 3] = src[(i * w + j) * 4 + 2];
dst[(i * w + j) * 3 + 1] = src[(i * w + j) * 4 + 1];
dst[(i * w + j) * 3 + 2] = src[(i * w + j) * 4];
}
}
}
int main()
{
int nloop = 100;
const int w = 480;
const int h = 640;
uint8_t bgra_mat[w * h * 4];
uint8_t rgb_mat[w * h * 3];
srand(100);
for (int i = 0; i < w * h * 4; i++)
{
bgra_mat[i] = rand() % 256;
}
clock_t t = clock();
for (int iloop = 0; iloop < nloop; iloop++)
bgra2rgb(bgra_mat, rgb_mat, w, h);
t = clock() - t;
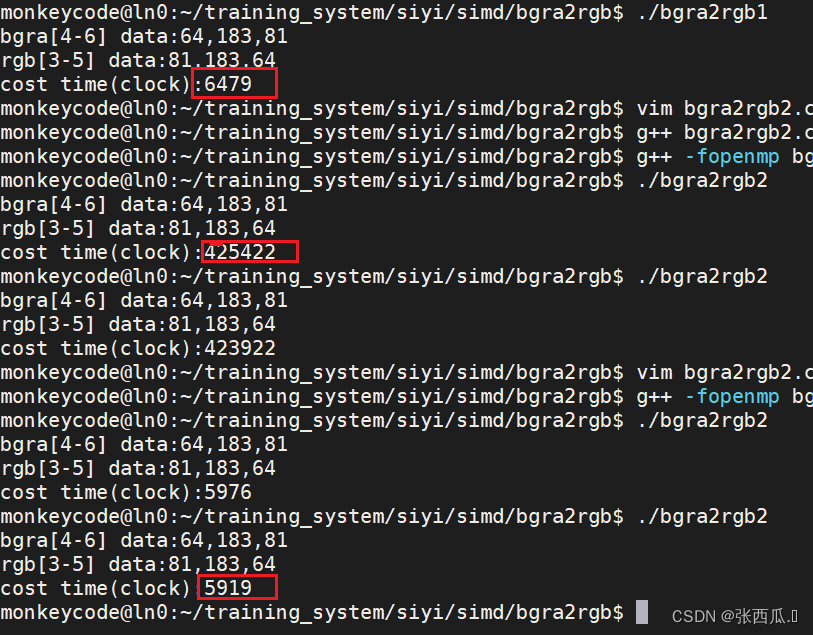
cout << "bgra[4-6] data:" << (int)bgra_mat[4] << "," << (int)bgra_mat[5] << "," << (int)bgra_mat[6] << endl;
cout << "rgb[3-5] data:" << (int)rgb_mat[3] << "," << (int)rgb_mat[4] << "," << (int)rgb_mat[5] << endl;
cout << "cost time(clock):" << t / nloop << endl;
}
2. parallel
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <omp.h>
using namespace std;
void bgra2rgb_arm_neon(const uint8_t *src, uint8_t *dst, int w, int h)
{
// #pragma omp parallel 加入线程创建开销很大
for (int i = 0; i < h; ++i)
{
#pragma omp simd simdlen(16)
for (int j = 0; j < w; j++)
{
dst[(i * w + j) * 3] = src[(i * w + j) * 4 + 2];
dst[(i * w + j) * 3 + 1] = src[(i * w + j) * 4 + 1];
dst[(i * w + j) * 3 + 2] = src[(i * w + j) * 4];
}
}
}
int main()
{
int nloop = 100;
const int w = 480;
const int h = 640;
uint8_t bgra_mat[w * h * 4];
uint8_t rgb_mat[w * h * 3];
srand(100);
for (int i = 0; i < w * h * 4; i++)
{
bgra_mat[i] = rand() % 256;
}
clock_t t = clock();
for (int iloop = 0; iloop < nloop; iloop++)
bgra2rgb_arm_neon(bgra_mat, rgb_mat, w, h);
t = clock() - t;
cout << "bgra[4-6] data:" << (int)bgra_mat[4] << "," << (int)bgra_mat[5] << "," << (int)bgra_mat[6] << endl;
cout << "rgb[3-5] data:" << (int)rgb_mat[3] << "," << (int)rgb_mat[4] << "," << (int)rgb_mat[5] << endl;
cout << "cost time(clock):" << t / nloop << endl;
}
GEMM

1. serial
#include <iostream>
#include <ctime>
#include <omp.h>
using namespace std;
void dgemv(const int n, const int m, const double *const A,
const double *const x, double *y)
{
for (int i = 0; i < n; i++)
{
double y_tmp = 0.0;
for (int j = 0; j < m; j++)
{
y_tmp += A[i * m + j] * x[j];
}
y[i] = y_tmp;
}
return;
}
int main()
{
int nloop = 1000;
int n = 10240;
double *mat_A = new double[n * n];
double *vec_x = new double[n];
double *vec_y = new double[n];
srand(0);
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
vec_x[j] = (double)(rand() % 10) + (double)rand() / RAND_MAX * 3.14;
mat_A[i * n + j] = (double)(rand() % 10) + (double)rand() / RAND_MAX * 3.14;
}
vec_y[i] = 0.0;
}
clock_t t = clock();
for (int iloop = 0; iloop < nloop; iloop++)
{
dgemv(n, n, mat_A, vec_x, vec_y);
}
t = clock() - t;
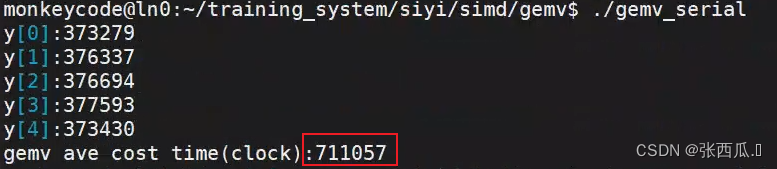
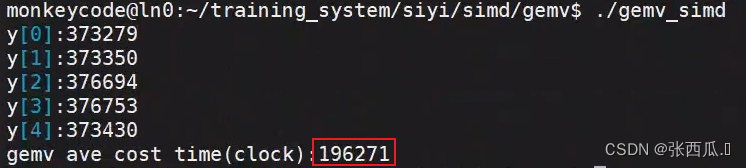
cout << "y[0]:" << vec_y[0] <<
endl;
cout << "y[1]:" << vec_y[1] << endl;
cout << "y[2]:" << vec_y[2] << endl;
cout << "y[3]:" << vec_y[3] << endl;
cout << "y[4]:" << vec_y[4] << endl;
cout << "gemv ave cost time(clock):" << t / nloop << endl;
}
2. simd
#include <iostream>
#include <ctime>
#include <omp.h>
#include <arm_neon.h>
using namespace std;
void dgemv(const int n, const int m, const double *const A,
const double *const x, double *y)
{
for (int i = 0; i < n; i += 2) // 1. i循环展开,放在j内循环展开
{
float64x2_t vy_tmp, v1, v2;
vy_tmp = vdupq_n_f64(0.0);
float64x2_t vy_tmp2, v11, v22;
vy_tmp2 = vdupq_n_f64(0.0);
for (int j = 0; j < m / 2 * 2; j += 2) // 2. j向量化
{
float64x2_t v1 = vld1q_f64(&A[i * m + j]);
float64x2_t v2 = vld1q_f64(&x[j]);
vy_tmp = vfmaq_f64(vy_tmp, v1, v2);
float64x2_t v11 = vld1q_f64(&A[(i + 1) * m + j]);
float64x2_t v22 = vld1q_f64(&x[j]);
vy_tmp2 = vfmaq_f64(vy_tmp, v1, v2);
}
y[i] = vaddvq_f64(vy_tmp);
y[i + 1] = vaddvq_f64(vy_tmp2);
}
return;
}
int main()
{
int nloop = 10;
int n = 10240;
double *mat_A = new double[n * n];
double *vec_x = new double[n];
double *vec_y = new double[n];
srand(0);
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
vec_x[j] = (double)(rand() % 10) + (double)rand() / RAND_MAX * 3.14;
mat_A[i * n + j] = (double)(rand() % 10) + (double)rand() / RAND_MAX * 3.14;
}
vec_y[i] = 0.0;
}
clock_t t = clock();
for (int iloop = 0; iloop < nloop; iloop++)
{
dgemv(n, n, mat_A, vec_x, vec_y);
}
t = clock() - t;
cout << "y[0]:" << vec_y[0] << endl;
cout << "y[1]:" << vec_y[1] << endl;
cout << "y[2]:" << vec_y[2] << endl;
cout << "y[3]:" << vec_y[3] << endl;
cout << "y[4]:" << vec_y[4] << endl;
cout << "gemv ave cost time(clock):" << t / nloop << endl;
}
test_if

1. serial
#include <iostream>
#include <ctime>
#include <arm_neon.h>
using namespace std;
void test_if(int n, int* a, int* b, float* x, float* y, float* z){
for (int i = 0; i < n; i ++){
if (a[i] > b[i]) z[i] = x[i] * y[i];
else z[i] = x[i] + y[i];
}
return;
}
int main()
{
int nloop = 1000;
int n = 10240;
int *vec_a = new int[n];
int *vec_b = new int[n];
float *vec_x = new float[n];
float *vec_y = new float[n];
float *vec_z = new float[n];
srand(0);
for (int i = 0; i < n; i++)
{
vec_a[i] = (int)(rand() % 256);
vec_b[i] = (int)(rand() % 256);
vec_x[i] = (float32_t)(rand() % 10) + (float32_t)rand() / RAND_MAX * 3.14;
vec_y[i] = (float32_t)(rand() % 10) + (float32_t)rand() / RAND_MAX * 3.14;
vec_z[i] = 0.0;
}
clock_t t = clock();
for (int iloop = 0; iloop < nloop; iloop++)
{
test_if(n, vec_a, vec_b, vec_x, vec_y, vec_z);
}
t = clock() - t;
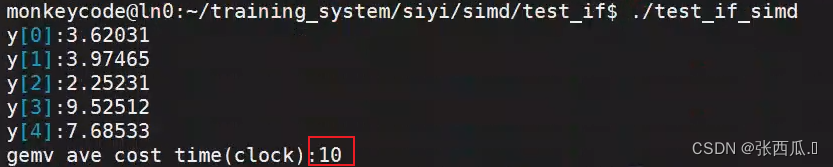
cout << "y[0]:" << vec_y[0] << endl;
cout << "y[1]:" << vec_y[1] << endl;
cout << "y[2]:" << vec_y[2] << endl;
cout << "y[3]:" << vec_y[3] << endl;
cout << "y[4]:" << vec_y[4] << endl;
cout << "gemv ave cost time(clock):" << t / nloop << endl;
}
2. simd
#include <iostream>
#include <ctime>
#include <arm_neon.h>
using namespace std;
void test_if_neon(int n, int* a, int* b, float* x, float* y, float* z){
for (int i = 0; i < n; i += 4){
float32x4_t vz1, vz2, res, xx, yy;
int32x4_t aa, bb;
uint32x4_t cmp;
xx = vld1q_f32(&xx[i]);
yy = vld1q_f32(&yy[i]);
aa = vld1q_s32(&aa[i]);
bb = vld1q_s32(&bb[i]);
cmp = vsubq_s32(aa, bb);
vz1 = vmulq_f32(xx, yy);
vz2 = vaddq_f32(xx, yy);
res = vbslq_f32(cmp, vz1, vz2);
vst1q_f32(&z[i], res);
}
return;
}
int main()
{
int nloop = 1000;
int n = 10240;
int *vec_a = new int[n];
int *vec_b = new int[n];
float *vec_x = new float[n];
float *vec_y = new float[n];
float *vec_z = new float[n];
srand(0);
for (int i = 0; i < n; i++)
{
vec_a[i] = (int)(rand() % 256);
vec_b[i] = (int)(rand() % 256);
vec_x[i] = (float32_t)(rand() % 10) + (float32_t)rand() / RAND_MAX * 3.14;
vec_y[i] = (float32_t)(rand() % 10) + (float32_t)rand() / RAND_MAX * 3.14;
vec_z[i] = 0.0;
}
clock_t t = clock();
for (int iloop = 0; iloop < nloop; iloop++)
{
test_if_neon(n, vec_a, vec_b, vec_x, vec_y, vec_z);
}
t = clock() - t;
cout << "y[0]:" << vec_y[0] << endl;
cout << "y[1]:" << vec_y[1] << endl;
cout << "y[2]:" << vec_y[2] << endl;
cout << "y[3]:" << vec_y[3] << endl;
cout << "y[4]:" << vec_y[4] << endl;
cout << "gemv ave cost time(clock):" << t / nloop << endl;
}

矩阵转置 & 图像旋转
1. 矩阵转置
#include <iostream>
#include <ctime>
#include <arm_neon.h>
using namespace std;
void mat_trn(float *src, float *dst, int n, int m)
{
//src[i,j]-->dst[j,i]
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
{
dst[j * n + i] = src[i * m + j];
}
return;
}
void mat_trn_block_neon(float *src, float *dst, int n, int m)
{
int block_size = 4;
int nblock = n / block_size;
int mblock = m / block_size;
int i, j;
float32x4_t v_src0, v_src1, v_src2, v_src3;
float32x4x2_t v_tmp0, v_tmp1;
float64x2_t v_src0_long, v_src1_long, v_src2_long, v_src3_long;
//float64x2x2_t v_dst02_long,v_dst13_long;
//#pragma omp parallel for
for (int i = 0; i < n; i += block_size)
for (int j = 0; j < m; j += block_size)
{
v_src0 = vld1q_f32(&src[i * m + j]);
v_src1 = vld1q_f32(&src[(i + 1) * m + j]);
v_src2 = vld1q_f32(&src[(i + 2) * m + j]);
v_src3 = vld1q_f32(&src[(i + 3) * m + j]);
v_tmp0 = vtrnq_f32(v_src0, v_src1);
v_tmp1 = vtrnq_f32(v_src2, v_src3);
v_src0_long = vreinterpretq_f64_f32(v_tmp0.val[0]);
v_src1_long = vreinterpretq_f64_f32(v_tmp0.val[1]);
v_src2_long = vreinterpretq_f64_f32(v_tmp1.val[0]);
v_src3_long = vreinterpretq_f64_f32(v_tmp1.val[1]);
vst1q_f32(&dst[j * n + i], vreinterpretq_f32_f64(vtrn1q_f64(v_src0_long, v_src2_long)));
vst1q_f32(&dst[(j + 1) * n + i], vreinterpretq_f32_f64(vtrn1q_f64(v_src1_long, v_src3_long)));
vst1q_f32(&dst[(j + 2) * n + i], vreinterpretq_f32_f64(vtrn2q_f64(v_src0_long, v_src2_long)));
vst1q_f32(&dst[(j + 3) * n + i], vreinterpretq_f32_f64(vtrn2q_f64(v_src1_long, v_src3_long)));
}
}
int main()
{
int n = 1024;
float *src = new float[n * n];
float *dst = new float[n * n];
srand(time(NULL));
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
src[i * n + j] = i * 3.14 + j * 0.314;
}
clock_t t = clock();
for (int iloop = 0; iloop < 1000; iloop++)
mat_trn(src, dst, n, n);
t = clock() - t;
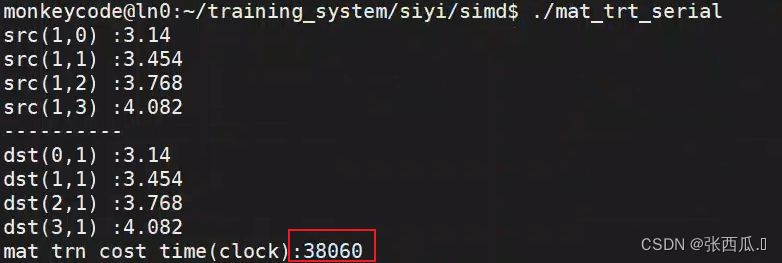
cout << "src(1,0) :" << src[1 * n + 0] << endl;
cout << "src(1,1) :" << src[1 * n + 1] << endl;
cout << "src(1,2) :" << src[1 * n + 2] << endl;
cout << "src(1,3) :" << src[1 * n + 3] << endl;
cout << "----------" << endl;
cout << "dst(0,1) :" << dst[0 * n + 1] << endl;
cout << "dst(1,1) :" << dst[1 * n + 1] << endl;
cout << "dst(2,1) :" << dst[2 * n + 1] << endl;
cout << "dst(3,1) :" << dst[3 * n + 1] << endl;
cout << "mat trn cost time(clock):" << t / 1000 << endl;
}
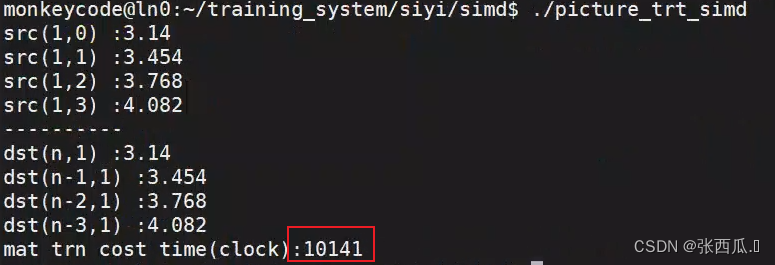
2. 图片转置
#include <iostream>
#include <ctime>
#include <arm_neon.h>
using namespace std;
void mat_trn(float *src, float *dst, int n, int m)
{
//src[i,j]-->dst[j,i]
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
{
dst[j * n + i] = src[i * m + j];
}
return;
}
void mat_trn_block_neon(float *src, float *dst, int n, int m)
{
int block_size = 4;
int nblock = n / block_size;
int mblock = m / block_size;
int i, j;
float32x4_t v_src0, v_src1, v_src2, v_src3;
float32x4x2_t v_tmp0, v_tmp1;
float64x2_t v_src0_long, v_src1_long, v_src2_long, v_src3_long;
//float64x2x2_t v_dst02_long,v_dst13_long;
//#pragma omp parallel for
for (int i = 0; i < n; i += block_size)
for (int j = 0; j < m; j += block_size)
{
v_src0 = vld1q_f32(&src[i * m + j]);
v_src1 = vld1q_f32(&src[(i + 1) * m + j]);
v_src2 = vld1q_f32(&src[(i + 2) * m + j]);
v_src3 = vld1q_f32(&src[(i + 3) * m + j]);
// vrev64q_f32(v_src0);
// vrev64q_f32(v_src1);
// vrev64q_f32(v_src2);
// vrev64q_f32(v_src3);
v_tmp0 = vtrnq_f32(v_src0, v_src1);
v_tmp1 = vtrnq_f32(v_src2, v_src3);
v_src0_long = vreinterpretq_f64_f32(v_tmp0.val[0]);
v_src1_long = vreinterpretq_f64_f32(v_tmp0.val[1]);
v_src2_long = vreinterpretq_f64_f32(v_tmp1.val[0]);
v_src3_long = vreinterpretq_f64_f32(v_tmp1.val[1]);
vst1q_f32(&dst[(n - j - 1) * n + i], vreinterpretq_f32_f64(vtrn1q_f64(v_src0_long, v_src2_long)));
vst1q_f32(&dst[(n - j - 2) * n + i], vreinterpretq_f32_f64(vtrn1q_f64(v_src1_long, v_src3_long)));
vst1q_f32(&dst[(n - j - 3) * n + i], vreinterpretq_f32_f64(vtrn2q_f64(v_src0_long, v_src2_long)));
vst1q_f32(&dst[(n - j - 4) * n + i], vreinterpretq_f32_f64(vtrn2q_f64(v_src1_long, v_src3_long)));
}
}
int main()
{
int n = 1024;
float *src = new float[n * n];
float *dst = new float[n * n];
srand(time(NULL));
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
src[i * n + j] = i * 3.14 + j * 0.314;
}
clock_t t = clock();
for (int iloop = 0; iloop < 1000; iloop++)
mat_trn_block_neon(src, dst, n, n);
t = clock() - t;
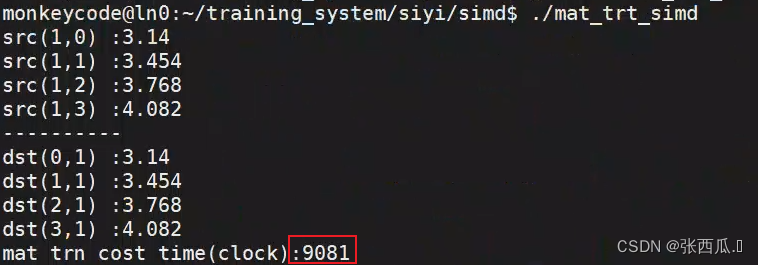
cout << "src(1,0) :" << src[1 * n + 0] << endl;
cout << "src(1,1) :" << src[1 * n + 1] << endl;
cout << "src(1,2) :" << src[1 * n + 2] << endl;
cout << "src(1,3) :" << src[1 * n + 3] << endl;
cout << "----------" << endl;
cout << "dst(n,1) :" << dst[(n - 1) * n + 1] << endl;
cout << "dst(n-1,1) :" << dst[(n - 2) * n + 1] << endl;
cout << "dst(n-2,1) :" << dst[(n - 3) * n + 1] << endl;
cout << "dst(n-3,1) :" << dst[(n - 4) * n + 1] << endl;
cout << "mat trn cost time(clock):" << t / 1000 << endl;
}
😍StellarSim(基础优化+OpenMP+SIMD)
程序简介&项目要求

性能分析 & gprof & 热点函数图
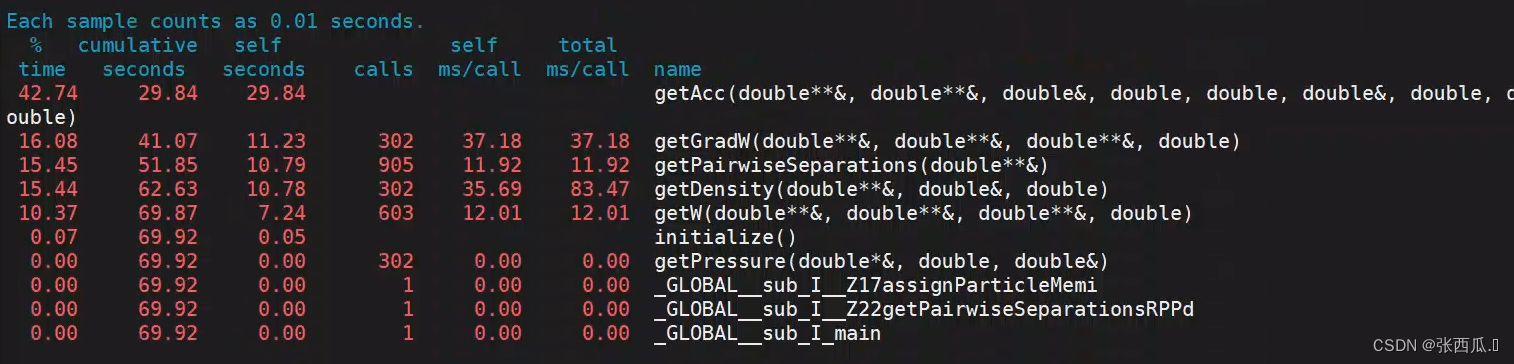
makefile
优化思路
SIMD
getaAcc
提出常量
wx[i][j]改循环顺序
多线程
void getAcc(double** &pos, double** &vel, double &m, const double h, const double k, double &n, double lmbda, const double nu)
{
getDensity(pos, m, h);
getPressure(rho, k, n);
getPairwiseSeparations(pos);
getGradW(dx, dy, dz, h);
for (int j = 0; j < N; j++) {
for (int i = 0; i < N; i++) {
// P[j]/pow(rho[j],2)常量 vdump wx[i][j]改循环顺序
acc[0][j] -= m * ( P[j]/pow(rho[j],2) + pow(P[i]/rho[i],2) ) * wx[i][j]; // wx[i][j] = -1 * wx[j][i]
acc[1][j] -= m * ( P[j]/pow(rho[j],2) + pow(P[i]/rho[i],2) ) * wy[i][j];
acc[2][j] -= m * ( P[j]/pow(rho[j],2) + pow(P[i]/rho[i],2) ) * wz[i][j];
}
}
for (int j = 0; j < N; j++) {
acc[0][j] -= lmbda * pos[0][j];
acc[1][j] -= lmbda * pos[1][j];
acc[2][j] -= lmbda * pos[2][j];
}
for (int j = 0; j < N; j++) {
acc[0][j] -= nu * vel[0][j];
acc[1][j] -= nu * vel[1][j];
acc[2][j] -= nu * vel[2][j];
}
}
void getAcc(double** &pos, double** &vel, double &m, const double h, const double k, double &n, double lmbda, const double nu)
{
getDensity(pos, m, h);
getPressure(rho, k, n);
getPairwiseSeparations(pos);
getGradW(dx, dy, dz, h);
float64x2_t v_m = vdupq_n_f64(m);
{
#pragma omp for
for (int j = 0; j < N; j++) {
// 向量化
float64x2_t v_tmp = vdupq_n_f64(P[j]/pow(rho[j], 2));
float64x2_t v_acc0 = vdupq_n_f64(0.0);
float64x2_t v_acc1 = vdupq_n_f64(0.0);
float64x2_t v_acc2 = vdupq_n_f64(0.0);
float64x2_t v_P, v_rho, v_wx, v_wy, v_wz, v_tmp2;
float64x2_t v1 = vdupq_n_f64(-1.0); // wx[j][i] = -wx[i][j]
float64_t acc0, acc1, acc2;
for (int i = 0; i < N/2*2; i+=2) {
v_tmp2 = vdivq_f64_neon(vmulq_f64(v_P, v_P), vmulq_f64(v_rho, v_rho));
v_wx = vld1q_f64(&wx[j][i]);
v_wy = vld1q_f64(&wy[j][i]);
v_wz = vld1q_f64(&wz[j][i]);
v_wx = vmulq_f64(v_wx, v1);
v_wy = vmulq_f64(v_wy, v1);
v_wz = vmulq_f64(v_wx, v1);
//乘加操作
v_acc0 = vmlaq_f64(v_acc0, vmulq_f64(v_m,v_wx), vaddq_f64(v_tmp, v_tmp2));
v_acc1 = vmlaq_f64(v_acc1, vmulq_f64(v_m,v_wy), vaddq_f64(v_tmp, v_tmp2));
v_acc2 = vmlaq_f64(v_acc2, vmulq_f64(v_m,v_wz), vaddq_f64(v_tmp, v_tmp2));
}
acc0 = vaddvq_f64(v_acc0);
acc1 = vaddvq_f64(v_acc1);
acc2 = vaddvq_f64(v_acc2);
for(int i = N/2*2; i < N; i++)
{
acc0 += m * ( P[j]/pow(rho[j], 2) + pow(P[i]/rho[i],2) ) * wx[j][i];
acc1 += m * ( P[j]/pow(rho[j], 2) + pow(P[i]/rho[i],2) ) * wy[j][i];
acc2 += m * ( P[j]/pow(rho[j], 2) + pow(P[i]/rho[i],2) ) * wz[j][i];
}
acc[0][j] += acc0;
acc[1][j] += acc1;
acc[2][j] += acc2;
}
#pragma omp for
// float64x2_t v_lamda = vdupq_n_f64(lmbda);
for (int j = 0; j < N; j++) {
acc[0][j] -= lmbda * pos[0][j];
acc[1][j] -= lmbda * pos[1][j];
acc[2][j] -= lmbda * pos[2][j];
}
#pragma omp for
for (int j = 0; j < N; j++) {
acc[0][j] -= nu * vel[0][j];
acc[1][j] -= nu * vel[1][j];
acc[2][j] -= nu * vel[2][j];
}
}
getGradW
循环展开
void getGradW(double** &dx, double** &dy, double** &dz, const double h)
{
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
r[i][j] = sqrt(pow(dx[i][j],2.0) + pow(dy[i][j],2.0) + pow(dz[i][j],2.0));
gradPara[i][j] = -2 * exp(-pow(r[i][j],2) / pow(h,2)) / pow(h,5) / pow(pi,(3/2));
wx[i][j] = gradPara[i][j]*dx[i][j];
wy[i][j] = gradPara[i][j]*dy[i][j];
wz[i][j] = gradPara[i][j]*dz[i][j];
//fprintf(stdout, "%12.6f", wy[i][j]);
//fflush(stdout);
}
//fprintf(stdout,"\n");
}
}
void getGradW(double** &dx, double** &dy, double** &dz, const double h)
{
//- 寄存器变量 + 循环展开
double val0 = 1.0 / pow(h,5) / pow(pi,(3/2));
double val1 = 1.0 / pow(h, 2);
#pragma omp parallel for schedule(auto) collapse(2)
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j += 4) {
register double x0 = dx[i][j+0];
register double x1 = dx[i][j+1];
register double x2 = dx[i][j+2];
register double x3 = dx[i][j+3];
register double y0 = dy[i][j+0];
register double y1 = dy[i][j+1];
register double y2 = dy[i][j+2];
register double y3 = dy[i][j+3];
register double z0 = dz[i][j+0];
register double z1 = dz[i][j+1];
register double z2 = dz[i][j+2];
register double z3 = dz[i][j+3];
register double tmp0 = sqrt(pow(x0,2.0) + pow(y0,2.0) + pow(z0,2.0));
register double tmp1 = sqrt(pow(x1,2.0) + pow(y1,2.0) + pow(z1,2.0));
register double tmp2 = sqrt(pow(x2,2.0) + pow(y2,2.0) + pow(z2,2.0));
register double tmp3 = sqrt(pow(x3,2.0) + pow(y3,2.0) + pow(z3,2.0));
tmp0 = -2 * val0 * exp( - val1 * pow(tmp0, 2) );
tmp1 = -2 * val0 * exp( - val1 * pow(tmp1, 2) );
tmp2 = -2 * val0 * exp( - val1 * pow(tmp2, 2) );
tmp3 = -2 * val0 * exp( - val1 * pow(tmp3, 2) );
wx[i][j+0] = tmp0 * x0;
wx[i][j+1] = tmp1 * x1;
wx[i][j+2] = tmp2 * x2;
wx[i][j+3] = tmp3 * x3;
wy[i][j+0] = tmp0 * y0;
wy[i][j+1] = tmp1 * y1;
wy[i][j+2] = tmp2 * y2;
wy[i][j+3] = tmp3 * y3;
wz[i][j+0] = tmp0 * z0;
wz[i][j+1] = tmp1 * z1;
wz[i][j+2] = tmp2 * z2;
wz[i][j+3] = tmp3 * z3;
}
}
}
getPairwiseSeparations
循环展开
void getPairwiseSeparations(double** &pos)
{
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
dx[i][j] = pos[0][j] - pos[0][i]; // dx[j][i] = pos[0][i] - pos[0][j] = -dx[i][j]
dy[i][j] = pos[1][j] - pos[1][i]; // double 64位 128寄存器放两个
dz[i][j] = pos[2][j] - pos[2][i];
//fprintf(stdout, "%12.6f", dz[i][j]);
//fflush(stdout);
}
//fprintf(stdout,"\n");
}
}
void getPairwiseSeparations(double** &pos)
{
#pragma omp for
for (int i = 0; i < N; i++) {
float64x2_t vi0 = vdupq_n_f64(pos[0][i]);
float64x2_t vi1 = vdupq_n_f64(pos[1][i]);
float64x2_t vi2 = vdupq_n_f64(pos[2][i]);
for (int j = 0; j < N/2*2; j+=2) {
float64x2_t vj0 = vld1q_f64(&pos[0][j]);
float64x2_t vj1 = vld1q_f64(&pos[1][j]);
float64x2_t vj2 = vld1q_f64(&pos[2][j]);
vst1q_f64(&dx[i][j],vsubq_f64(vj0,vi0));
vst1q_f64(&dy[i][j],vsubq_f64(vj1,vi1));
vst1q_f64(&dz[i][j],vsubq_f64(vj2,vi2));
}
for (int j = N/2*2; j < N; j++) {
dx[i][j] = pos[0][j] - pos[0][i];
dy[i][j] = pos[1][j] - pos[1][i];
dz[i][j] = pos[2][j] - pos[2][i];
//fprintf(stdout, "%12.6f", dz[i][j]);
//fflush(stdout);
}
//fprintf(stdout,"\n");
}
}
getDensity
void getDensity(double** &pos, double &m, const double h)
{
getPairwiseSeparations(pos);
getW(dx, dy, dz, h);
for (int j = 0; j < N; j++) {
for (int i = 0; i < N; i++) {
rho[j] += m * W[i][j];
}
//fprintf(stdout, "%12.6f", rho[j]);
//fflush(stdout);
//fprintf(stdout,"\n");
}
}
void getDensity(double** &pos, double &m, const double h)
{
getPairwiseSeparations(pos);
getW(dx, dy, dz, h);
//- SIMD向量化
#pragma omp parallel for schedule(auto)
for (int j = 0; j < N; j++) {
double sum = 0.0;
float64x2_t vec0 = vdupq_n_f64(0.0);
float64x2_t vec1 = vdupq_n_f64(0.0);
float64x2_t temp = vdupq_n_f64(0.0);
for (int i = 0; i < N/4*4; i += 4) {
vec0 = vld1q_f64(&W[j][i+0]);
vec1 = vld1q_f64(&W[j][i+2]);
temp = vaddq_f64(temp, vec0);
temp = vaddq_f64(temp, vec1);
}
sum = vaddvq_f64(temp);
for ( int i = N/4*4; i < N; i++ ) {
sum += W[j][i];
}
rho[j] += - m * sum;
}
}
getPressure
void getPressure(double* &rho, const double k, double &n)
{
for (int j = 0; j < N; j++) {
P[j] = k * pow(rho[j], (1+1/n));
//fprintf(stdout, "%12.6f\n", P[j]);
}
}
OpenMP
- main函数中开启
- 函数中就不用开启线程了,否则一直开关,效率没有提升
精度
- 串行
- openmp + simd
加速比
以单核结果为基准,进行强可拓展性测试
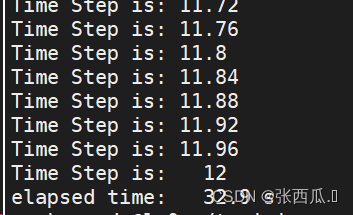
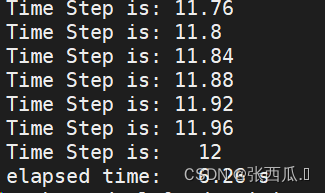
elapsed time: 170s
elapsed time: 32.9 s(5.16)
elapsed time: 6.26 s(27.16)

💕IPP移植
简介
Intel® Integrated Performance Primitives,英特尔集成性能基元(简称 IPP),
为信号、数据和图像处理特定应用领域,提供 simd 优化的一组全面的函数库工
程文件组织架构。 oneAPI为X86架构专享,不开源或无源码,上层用户代码改写代价过大,所以需要编写适配arm架构的移植替代现在需要将 IPP 软件从 X86 平台移植到 ARM 平台上。
完成移植的函数
• 指数函数
• 三角函数
• 采样函数—tone生成函数、Triangle生成函数
保证接口一致,类型规范
使用simd技术进行并行化
命名规范



✌ exp
代码思路
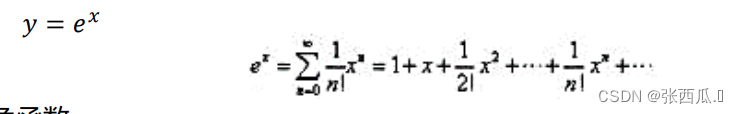
- 泰勒级数每个对于之前的级数都乘一个系数,然后加到
vexp总和中 - 直到
vterm < vprec进行比较,然后跳出循环,赋值给内存 - 处理尾部
代码
- ARM移植
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <arm_neon.h>
#include "/thfs1/home/monkeycode/training_system/siyi/simd/ipp/include/ipp.h"
IppStatus ippsExp_32f_A24(const Ipp32f *pSrc, Ipp32f *pDst, Ipp32s len)
{
float32x4_t vtemp2, vtemp1, vterm, rec, recip, vx;
float32x4_t vexp;
for (int i = 0; i < len / 4 * 4; i += 4)
{
float32_t y = 2.0;
vx = vld1q_f32(&pSrc[i]);
vexp = vaddq_f32(vld1q_f32(&pSrc[i]), vdupq_n_f32(1.0)); // 获得 1 + x 的值
vterm = vld1q_f32(&pSrc[i]); //所对应的前一项级数
for (int j = 0; fabs(vmaxvq_f32(vterm)) > 1e-7; j++) // 当O(x^n) > 1e-7 继续算泰勒级数
{
vtemp1 = vdupq_n_f32(y); // y是泰勒级数对应的次数
rec = vrecpeq_f32(vtemp1); // 1 / y
recip = vmulq_f32(vrecpsq_f32(vtemp1, rec), rec); // 获得vtemp1的倒数 1/y 万分之一的精度
// recip1 = vmul_f32(vrecpsq_f32(vtemp1, recip), recip); // 获得vtemp1的倒数 1/ y 基本能达到完全精度
vtemp1 = vmulq_f32(vterm, vx); // () * x
vterm = vmulq_f32(vtemp1, recip); // () * x * 1/ y
vexp = vaddq_f32(vexp, vterm);
y++;
}
vst1q_f32(pDst + i, vexp);
}
for (int i = len / 4 * 4; i < len; i++)
{
float32_t term = pSrc[i];
float32_t x = pSrc[i];
float32_t exp = 1 + term;
for (int j = 2; fabs(term) > 1e-7; j++)
{
term = term * x / j;
exp += term;
}
pDst[i] = exp;
}
}
int main()
{
const Ipp32f A[5] = {4.885, -2.87, 3.809, -4.953, 3.31};
Ipp32f B[5] = {0};
Ipp32s len = 5;
ippsExp_32f_A24(A, B, len);
for (int i = 0; i < 5; i++)
{
printf("%lf\t", B[i]);
}
printf("\n");
return 0;
}
- x86测试
#include<stdio.h>
#include "/opt/intel/oneapi/ipp/latest/include/ipp.h"
/* Next two defines are created to simplify code reading and understanding */
#define EXIT_MAIN exitLine: /* Label for Exit */
#define check_sts(st) if((st) != ippStsNoErr) goto exitLine; /* Go to Exit if Intel(R) Integrated Primitives (Intel(R) IPP) function returned status different from ippStsNoErr */
int main()
{
int len = 5;
int i;
Ipp32f pSrc[5] = {4.885, -2.87, 3.809, -4.953, 3.31};
Ipp32f pDst[5] = {0.0, 0.0, 0.0, 0.0, 0.0};
IppStatus status;
int scale = 0; //without scaling
printf("\n\nSource vector\n");
for (i = 0; i < len; i++)
{
printf("%.3f; ", pSrc[i]);
}
check_sts(status = ippsExp_32f_A11(pSrc, pDst, len));
printf("\n\nResult\n");
for (i = 0; i < len; i++) printf("%.5f; ", pDst[i]);
printf("\n\n");
EXIT_MAIN
printf("Exit status %d (%s)\n", (int)status, ippGetStatusString(status));
return (int)status;
}
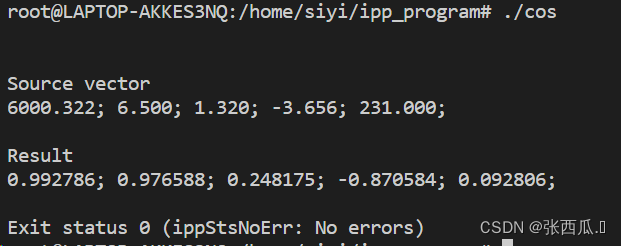
测试结果


✌ sin
代码思路
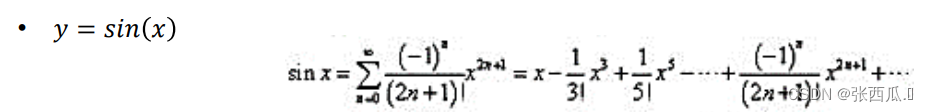
- 对于给的
x移动到[0,2pi]范围中 - 泰勒级数每个对于之前的级数都乘一个系数,然后加到
vsine总和中 - 直到
vterm < vprec进行比较,然后跳出循环,赋值给内存 - 处理尾部
代码
- ARM移植
#include <stdio.h>
#include <stdlib.h>
#include <arm_neon.h>
#include <math.h>
#include <omp.h>
#include "/thfs1/home/monkeycode/training_system/siyi/simd/ipp/include/ipp.h"
IppStatus ippsSin_32f_A21 (const Ipp32f* pSrc, Ipp32f* pDst, Ipp32s len){
float32x4_t vsine,vterm,vx,vz,vtemp1,rec,recip1,vtemp2,vfu,v2pi,rec1,recip2;
uint32x4_t vcmp;
vfu = vdupq_n_f32(-1.0); // 奇数偶数的符号
int32x4_t vk;
float32x4_t vprec = vdupq_n_f32(1e-7);
float32x4_t vpi = vdupq_n_f32(2*IPP_PI); // 2*pi
float32_t intK,temp2;
#pragma omp parallel for
for(int i=0;i<len/4*4;i+=4){
float32x4_t v2pi = vld1q_f32(&pSrc[i]);
rec1 = vrecpeq_f32(vpi);
recip2 = vmulq_f32(vrecpsq_f32(vpi,rec1),rec1);
vk = vcvtq_s32_f32(vmulq_f32(v2pi,recip2)); // 算一下要减去多少个周期
v2pi = vsubq_f32(v2pi,vmulq_f32(vcvtq_f32_s32(vk),vpi)); // 9 - 1* 2pi
vterm = v2pi;
vsine = v2pi; // vsine = x
vz = vmulq_f32(vsine,vsine);
intK = 1.0;
uint32_t flag = 1;
do{
intK+=2.0;
vtemp1=vmulq_f32(vmulq_f32(vterm,vfu),vz); // vtemp1 = -1 * x * x^2
temp2 = intK*(intK-1.0);
vtemp2 = vdupq_n_f32(temp2);
rec = vrecpeq_f32(vtemp2);
recip1= vmulq_f32(vrecpsq_f32(vtemp2,rec),rec); // 算系数 1/(2n + 1)!
vterm = vmulq_f32(vtemp1,recip1);// vtemp = -1 * x * x^ 2 * 1/(2n + 1)!
vsine = vaddq_f32(vsine,vterm);
vcmp = vcgtq_f32(vabsq_f32(vterm),vprec); //vterm > vprec = 1
flag = vmaxvq_u32(vcmp);
}while(flag!=0);
vst1q_f32(pDst+i,vsine);
}
for(int i=len/4*4;i<len;i++){
double dblSine,dblTerm,dblX,dblZ;
int intK,i,flag;
dblX=pSrc[i];
int k = (int)(dblX/(2*IPP_PI));
dblX=dblX-(2*IPP_PI)*k;
dblTerm=dblX;
dblSine=dblX;
intK = 1;
dblZ=dblX*dblX;
do{
intK = intK+2;
dblTerm = -dblTerm * dblZ/(intK*(intK-1));
dblSine = dblSine + dblTerm;
}while(fabs(dblTerm)>1e-7);
pDst[i]=dblSine;
}
}
int main(){
const Ipp32f A[4]= {6000.322,6231.5,1.32,-3.656};
Ipp32f B[4] = {0};
int len = 4;
ippsSin_32f_A21(A,B,len);
for(int i=0;i<len;i++){
printf("%lf\t",B[i]);
}
printf("\n");
return 0;
}
- x86测试
#include<stdio.h>
#include "/opt/intel/oneapi/ipp/latest/include/ipp.h"
/* Next two defines are created to simplify code reading and understanding */
#define EXIT_MAIN exitLine: /* Label for Exit */
#define check_sts(st) if((st) != ippStsNoErr) goto exitLine; /* Go to Exit if Intel(R) Integrated Primitives (Intel(R) IPP) function returned status different from ippStsNoErr */
int main()
{
int len = 4;
int i;
Ipp32f pSrc[4] = {6000.322, 6231.5, 1.32, -3.656};
Ipp32f pDst[4] = { 0.0, 0.0, 0.0, 0.0};
IppStatus status;
int scale = 0; //without scaling
printf("\n\nSource vector\n");
for (i = 0; i < len; i++)
{
printf("%.3f; ", pSrc[i]);
}
check_sts(status = ippsSin_32f_A21(pSrc, pDst, len));
printf("\n\nResult\n");
for (i = 0; i < len; i++) printf("%.6f; ", pDst[i]);
printf("\n\n");
EXIT_MAIN
printf("Exit status %d (%s)\n", (int)status, ippGetStatusString(status));
return (int)status;
测试结果


✌cos
代码思路
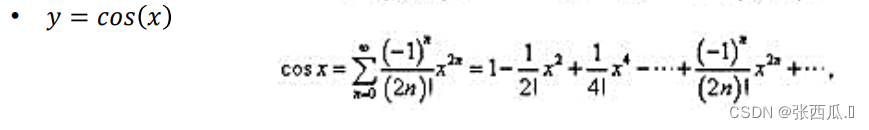
- 对于给的
x移动到[0,2pi]范围中 - 泰勒级数每个对于之前的级数都乘一个系数,然后加到
vcos总和中 - 直到
vterm < vprec进行比较,然后跳出循环,赋值给内存 - 处理尾部
- 与sin的区别是级数的起始不一样
代码
- ARM移植
#include <stdio.h>
#include <stdlib.h>
#include <arm_neon.h>
#include <math.h>
#include <omp.h>
#include "/thfs1/home/monkeycode/training_system/siyi/simd/ipp/include/ipp.h"
IppStatus ippsCos_32f_A21 (const Ipp32f* pSrc, Ipp32f* pDst, Ipp32s len){
float32x4_t vcos,vterm,vx,vz,vtemp1,rec,recip1,vtemp2,vfu,v2pi,rec1,recip2;
uint32x4_t vcmp;
vfu = vdupq_n_f32(-1.0);// 奇数偶数的符号
int32x4_t vk;
float32x4_t vprec = vdupq_n_f32(1e-7);
float32x4_t vpi = vdupq_n_f32(2*IPP_PI);// 2*pi
float32_t intK,temp2;
#pragma omp parallel for
for(int i=0;i<len/4*4;i+=4){
float32x4_t v2pi = vld1q_f32(&pSrc[i]);
rec1 = vrecpeq_f32(vpi);
recip2 = vmulq_f32(vrecpsq_f32(vpi,rec1),rec1);
vk = vcvtq_s32_f32(vmulq_f32(v2pi,recip2));// 算一下要减去多少个周期
v2pi = vsubq_f32(v2pi,vmulq_f32(vcvtq_f32_s32(vk),vpi));// 9 - 1* 2pi
vterm = vdupq_n_f32(1.0);
vcos = vdupq_n_f32(1.0);// vcos = 1
vz = vmulq_f32(v2pi,v2pi);
intK = 0.0;// 从0开始 0 2 4 6...
uint32_t flag = 1;
do{
intK+=2.0;
vtemp1=vmulq_f32(vmulq_f32(vterm,vfu),vz);// vtemp1 = -1 * 1 * x^2
temp2 = intK*(intK-1.0);
vtemp2 = vdupq_n_f32(temp2);
rec = vrecpeq_f32(vtemp2);
recip1= vmulq_f32(vrecpsq_f32(vtemp2,rec),rec);// 算系数 1/(2n)!
vterm = vmulq_f32(vtemp1,recip1);// vtemp = -1 * 1 * x^ 2 * 1/(2n)!
vcos = vaddq_f32(vcos,vterm);
vcmp = vcgtq_f32(vabsq_f32(vterm),vprec);//vterm > vprec = 1
flag = vmaxvq_u32(vcmp);
}while(flag!=0);
vst1q_f32(pDst+i,vcos);
}
for(int i=len/4*4;i<len;i++){
double term,mycos,x,z;
x = pSrc[i];
int k = (int)(x/(2*IPP_PI));
x=x-(2*IPP_PI)*k;
term = 1;
mycos = 1;
z = x*x;
double intk = 0.0,temp;
do{
intk+=2.0;
term = -term * z/(k*(k-1));
mycos+=term;
}while(fabs(term)>1e-7);
pDst[i]=mycos;
}
}
int main(){
const Ipp32f A[5]= {6000.322,6.5,1.32,-3.656,231};
Ipp32f B[5] = {0};
int len = 5;
ippsCos_32f_A21(A,B,len);
for(int i=0;i<len;i++){
printf("%lf\t",B[i]);
}
printf("\n");
// printf("%lf\t\n",cos(6000.322));
return 0;
}
- x86测试
#include<stdio.h>
#include "/opt/intel/oneapi/ipp/latest/include/ipp.h"
/* Next two defines are created to simplify code reading and understanding */
#define EXIT_MAIN exitLine: /* Label for Exit */
#define check_sts(st) if((st) != ippStsNoErr) goto exitLine; /* Go to Exit if Intel(R) Integrated Primitives (Intel(R) IPP) function returned status different from ippStsNoErr */
int main()
{
int len = 5;
int i;
Ipp32f pSrc[5] = {6000.322,6.5,1.32,-3.656,231};
Ipp32f pDst[5] = { 0.0, 0.0, 0.0, 0.0, 0.0};
IppStatus status;
int scale = 0; //without scaling
printf("\n\nSource vector\n");
for (i = 0; i < len; i++)
{
printf("%.3f; ", pSrc[i]);
}
check_sts(status = ippsCos_32f_A21(pSrc, pDst, len));
printf("\n\nResult\n");
for (i = 0; i < len; i++) printf("%.6f; ", pDst[i]);
printf("\n\n");
EXIT_MAIN
printf("Exit status %d (%s)\n", (int)status, ippGetStatusString(status));
return (int)status;

✌tone
代码思路

- 类似sinx cosx
- 首先要算出
x = 2*pi*f + fi,然后使其位于[0,2pi]区间,此时的x是一个数组,所以要循环算出所有的值 - 根据泰勒级数算出值,然后赋值到
pDst - 处理尾部数据
代码
- ARM移植
#include <stdio.h>
#include <stdlib.h>
#include <arm_neon.h>
#include <omp.h>
#include <math.h>
#include "/thfs1/home/monkeycode/training_system/siyi/simd/ipp/include/ipp.h"
IppStatus ippsTone_32f(Ipp32f* pDst, int len, Ipp32f magn, Ipp32f rFreq, Ipp32f* pPhase, IppHintAlgorithm hint){
float32x4_t vtemp,vxn,vphase,vx,rec,rec1,recip2,recip1,vterm,vcos,vz,vj,vmagn,vtemp1,vtemp2;
float32_t intK,temp2;
float32_t j[len];
for(int i=0;i<len;i++){
j[i]=i;// 为采样点赋初值 0 1 2 3 ...len - 1
}
uint32x4_t vcmp;
int32x4_t vk;
float32x4_t vfu = vdupq_n_f32(-1.0);
float32x4_t vprec = vdupq_n_f32(1e-7);
vmagn = vdupq_n_f32((Ipp32f)magn);// 幅值
float32x4_t vreq = vdupq_n_f32(rFreq);// 频率
float32x4_t vpi = vdupq_n_f32(2.0*IPP_PI);
for(int i=0;i<len/4*4;i+=4){
vphase = vld1q_f32(&pPhase[i]);// 相位 虽然应该不变,但是函数是给的数组
vj = vld1q_f32(&j[i]);
//vtemp1 = vmulq_f32(vmulq_f32(vpi,vdupq_n_f32(j)),vreq);
vtemp = vmulq_f32(vpi,vj);
vx = vaddq_f32(vmulq_f32(vtemp,vreq),vphase);
float32x4_t v2pi = vx;
rec1 = vrecpeq_f32(vpi);
recip2 = vmulq_f32(vrecpsq_f32(vpi,rec1),rec1);
vk = vcvtq_s32_f32(vmulq_f32(v2pi,recip2));
v2pi = vsubq_f32(v2pi,vmulq_f32(vcvtq_f32_s32(vk),vpi));// 级数之间相差的x^2
vterm = vdupq_n_f32(1.0);
vcos = vdupq_n_f32(1.0);
vz = vmulq_f32(v2pi,v2pi);// 级数之间相差的x^2
intK = 0.0;
uint32_t flag = 1;
do{
intK+=2.0;
vtemp1=vmulq_f32(vmulq_f32(vterm,vfu),vz);
temp2 = intK*(intK-1.0);
vtemp2 = vdupq_n_f32(temp2);
rec = vrecpeq_f32(vtemp2);
recip1= vmulq_f32(vrecpsq_f32(vtemp2,rec),rec);
vterm = vmulq_f32(vtemp1,recip1);
vcos = vaddq_f32(vcos,vterm);
vcmp = vcgtq_f32(vabsq_f32(vterm),vprec);
flag = vmaxvq_u32(vcmp);
}while(flag!=0);
vcos = vmulq_f32(vcos,vmagn);
vxn = vcos;
vst1q_f32(pDst+i,vxn);
}
for(int i=len/4*4;i<len;i++){
//相比y = cosx多一层循环,算的是n个采样点的cosx[i]值
Ipp32f tempc = 2*IPP_PI*j[i]*rFreq+pPhase[i];
Ipp32f x= tempc;
int k = (int)(x/(2*IPP_PI));
x=x-(2*IPP_PI)*k;
Ipp32f term = 1;
Ipp32f mycos = 1;
Ipp32f z = x*x;
double intk = 0.0,temp;
do{
intk+=2.0;
term = -term * z/(intk*(intk-1));
mycos += term;
}while(fabs(term)>1e-7);
Ipp32f xn = magn *mycos;
pDst[i]=xn;
}
}
int main(){
Ipp32f A[8];
int len = 8;
Ipp32f freq = 0.3;
Ipp32f B[8];
for(int i=0;i<8;i++){
B[i]=0.32;
}
Ipp32f magn = 4;
ippsTone_32f(A,len,magn,freq,B,ippAlgHintFast);
for(int i=0;i<8;i++){
//printf("%f %f\t",A[i].re,A[i].im);
printf("%f\t",A[i]);
}
printf("\n");
}
- x86测试
#include<stdio.h>
#include "/opt/intel/oneapi/ipp/latest/include/ipp.h"
/* Next two defines are created to simplify code reading and understanding */
#define EXIT_MAIN exitLine: /* Label for Exit */
#define check_sts(st) if((st) != ippStsNoErr) goto exitLine; /* Go to Exit if Intel(R) Integrated Primitives (Intel(R) IPP) function returned status different from ippStsNoErr */
int main()
{
Ipp32f A[8];
int len = 8;
Ipp32f freq = 0.3;
Ipp32f B[8];
for(int i=0;i<8;i++){
B[i]=0.32;
}
Ipp32f magn = 4;
IppStatus status;
check_sts(status = ippsTone_32f(A,len,magn,freq,B,ippAlgHintFast));
for(int i=0;i<8;i++){
//printf("%f %f\t",A[i].re,A[i].im);
printf("%f\t",A[i]);
}
printf("\n");
EXIT_MAIN
printf("Exit status %d (%s)\n", (int)status, ippGetStatusString(status));
return (int)status;
}


✌triangle
代码思路

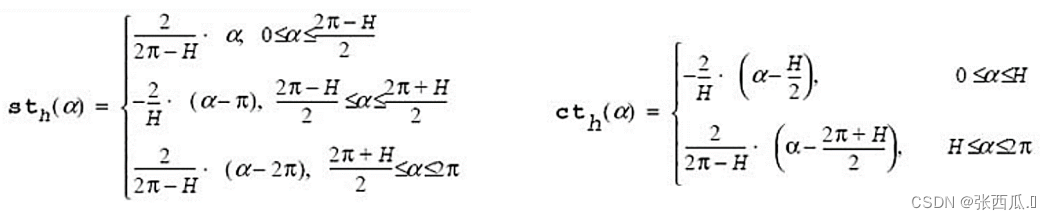
- 变换区间
[0, 2pi] - 求取cth、sth每个区间的值
- 根据比较选取具体的值
代码
- ARM移植
#include <stdio.h>
#include <stdlib.h>
#include <arm_neon.h>
#include <omp.h>
#include <math.h>
#include "/thfs1/home/monkeycode/training_system/siyi/simd/ipp/include/ipp.h"
IppStatus ippsTriangles_32fc(Ipp32fc* pDst, int len, Ipp32f magn, Ipp32f rFreq, Ipp32f
asym, Ipp32f* pPhase){
float32x4_t vtemp, vphase, vj, vx, vtrian1, vtrian2, vc1, vc2;
float32x4_t rec1, recip2;
float32x4_t sth1, sth2, sth3, vsthc1, vsthc2;
uint32x4_t vcmp, vcmp1, vcmp2;
float32x4_t vtrain1, vtrain2;
float32x4x2_t vxn;
int32x4_t vk;
float32_t j[len];
for (int i = 0; i < len; i ++) j[i] = i;
float32x4_t vmagn = vdupq_n_f32(magn);
float32x4_t vfreq = vdupq_n_f32(rFreq);
float32x4_t vasym = vdupq_n_f32(asym); // h
float32x4_t vpi = vdupq_n_f32(2.0*IPP_PI);
float32x4_t vpip = vdupq_n_f32(IPP_PI);
vasym = vaddq_f32(vasym, vpip); // H
for (int i = 0; i < len / 4 * 4; i += 4){
vphase = vld1q_f32(&pPhase[i]);
vj = vld1q_f32(&j[i]);
vtemp = vmulq_f32(vpi,vj); //2pix
vx = vaddq_f32(vmulq_f32(vtemp,vfreq),vphase); // 2pifx + fi
float32x4_t v2pi = vx;
rec1 = vrecpeq_f32(vpi);
recip2 = vmulq_f32(vrecpsq_f32(vpi,rec1),rec1);
vk = vcvtq_s32_f32(vmulq_f32(v2pi,recip2));
v2pi = vsubq_f32(v2pi,vmulq_f32(vcvtq_f32_s32(vk),vpi)); // 使其在[0,2pi]中
// 计算[0, pi]
vtrian1 = vdupq_n_f32(1.0);
rec1 = vrecpeq_f32(vasym);
recip2 = vmulq_f32(vrecpsq_f32(vasym, rec1), rec1);
vtrian1 = vsubq_f32(vtrian1, vmulq_f32(vmulq_n_f32(recip2, 2.0), v2pi));
sth2 = vdupq_n_f32(IPP_PI);
sth2 = vsubq_f32(sth2, v2pi);
sth2 = vmulq_f32(vmulq_n_f32(recip2, 2.0), sth2);
// 计算[pi, 2pi]
vc1 = vmulq_n_f32(vaddq_f32(vpi, vasym), 0.5);
vc2 = vsubq_f32(vpi, vasym);
rec1 = vrecpeq_f32(vc2);
recip2 = vmulq_f32(vrecpsq_f32(vc2,rec1),rec1);
vc2 = vmulq_n_f32(recip2, 2.0);
vtrian2 = vsubq_f32(vmulq_f32(vc2, v2pi), vmulq_f32(vc1, vc2));
sth1 = vmulq_f32(vc2, v2pi);
sth3 = vmulq_f32(vc2, vsubq_f32(v2pi, vpi));
// 计算[0, 2pi]
vcmp = vcgtq_f32(v2pi, vasym);
vtrain1 = vbslq_f32(vcmp, vtrian2, vtrian1);
vtrain1 = vmulq_f32(vtrain1, vmagn);
// 复数sth求解
vsthc1 = vmulq_n_f32(vsubq_f32(vpi, vasym), 0.5);
vsthc2 = vmulq_n_f32(vaddq_f32(vpi, vasym), 0.5);
vcmp1= vcgtq_f32(v2pi, vsthc1);
vcmp2 = vcgtq_f32(v2pi, vsthc2);
vtrain2 = vbslq_f32(vcmp1, sth2, sth1);
vtrain2 = vbslq_f32(vcmp2, sth3, vtrain2);
vtrain2 = vmulq_f32(vtrain2, vmagn);
vxn.val[0] = vtrain1;
vxn.val[1] = vtrain2;
vst2q_f32(&pDst[i].re, vxn);
}
for (int i = len / 4 * 4; i < len; i ++){
Ipp32fc xn;
Ipp32f tempc = 2*IPP_PI*j[i]*rFreq+pPhase[i];
Ipp32f x = tempc;
int k = (int)(x / 2 * IPP_PI);
x -= (2 * IPP_PI) * k;
Ipp32f H = IPP_PI + asym;
Ipp32f mytrain = 0.0;
Ipp32f mytrain1 = 0.0;
if (x < H) mytrain = -2.0 / H * x + 1.0;
else mytrain = 2 / (2 * IPP_PI - H) * (x - (2 * IPP_PI + H) / 2.0);
if (x < (2.0 * IPP_PI - H) * 0.5) mytrain1 = 2 / (2 * IPP_PI - H) * x;
else if (x > (2.0 * IPP_PI + H) * 0.5) mytrain1 = 2 / (2 * IPP_PI - H) * (x - 2 * IPP_PI);
else mytrain1 = -2.0 / H * (x - IPP_PI);
xn.re = mytrain*magn;
xn.im = mytrain1*magn;
pDst[i].re=xn.re;
pDst[i].im=xn.im;
}
}
int main(){
Ipp32fc A[8];
int len = 8;
Ipp32f freq = 0.3;
Ipp32f C = 1;
Ipp32f B[8];
for(int i=0;i<8;i++){
B[i]=0.32;
}
Ipp32f magn = 4;
ippsTriangles_32fc(A,len,magn,freq,C,B);
for(int i=0;i<8;i++){
printf("%f %f\t",A[i].re,A[i].im);
// printf("%f\t",A[i]);
}
printf("\n");
}
- x86测试代码
#include<stdio.h>
#include "/opt/intel/oneapi/ipp/latest/include/ipp.h"
/* Next two defines are created to simplify code reading and understanding */
#define EXIT_MAIN exitLine: /* Label for Exit */
#define check_sts(st) if((st) != ippStsNoErr) goto exitLine; /* Go to Exit if Intel(R) Integrated Primitives (Intel(R) IPP) function returned status different from ippStsNoErr */
int main()
{
Ipp32fc A[8];
int len = 8;
Ipp32f freq = 0.3;
Ipp32f B[8];
Ipp32f C = 1;
for(int i=0;i<8;i++){
B[i]=0.32;
}
Ipp32f magn = 4;
IppStatus status;
check_sts(status = ippsTriangle_32fc(A,len,magn,freq,C,B));
for(int i=0;i<8;i++){
printf("%f %f\t",A[i].re,A[i].im);
//printf("%f\t",A[i]);
}
printf("\n");
EXIT_MAIN
printf("Exit status %d (%s)\n", (int)status, ippGetStatusString(status));
return (int)status;
}
测试结果


- 三角波不存在泰勒级数展开问题,因此精度上还是比较高的
- 后几位小数不同可能是因为中间过程选取的不同寄存器,或者计算顺序影响
- 可以考虑不全部计算cth1 cth2,然后比较赋值,暂时还没想到只算一次的方法















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









