







一、什么是APR
APR(Apache Portable Runtime Libraries)是 Apache 可移植运行时库,它是用 C 语言实现的,其目的是向上层应用程序提供一个跨平台的操作系统接口库。Tomcat 可以用它来处理包括文件和网络 I/O
二、AprEndPoint
AprEndPonit与NioEndPoint类似,都是实现了非阻塞的I/O,
但是区别就是aprEndPoint是通过调用JNI调用本地的库实现非阻塞IO的。
本地库是使用C语言编写,当频繁的IO操作时,效率会高于java语言。
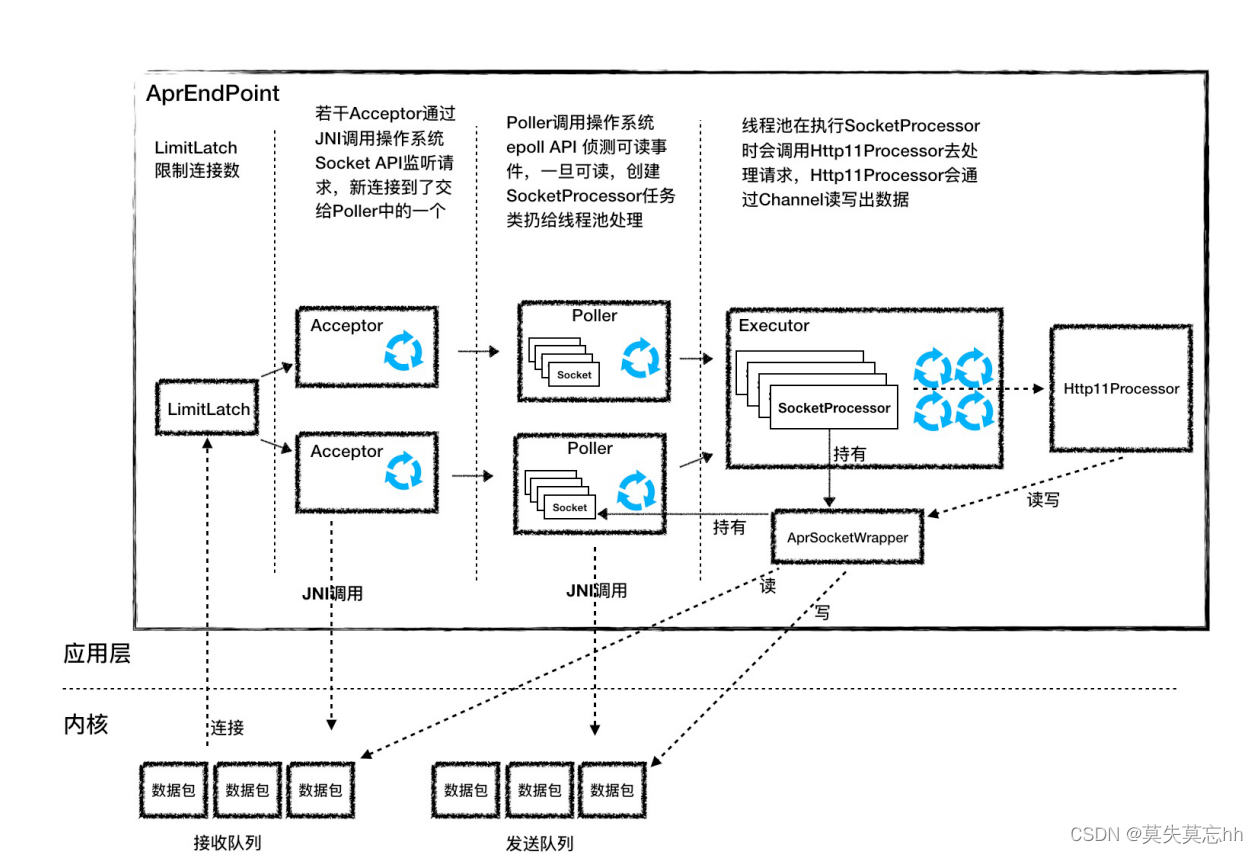
可以发现AprEndPoint的组件图跟NioAprEndPoint的特别类似。有区别的就是 Acceptor 与 Poller组件的实现。
- Acceptor的作用是监听连接,并建立连接的,Apr组件本质是通过JNI 调用操作系统的4个API: socket、bind、listen、accept.是通过JNI native关键字修饰的方法。 而NioAprEndPoint是调用Java的NIO。
- **Poller **acceptor接收到一个新的socket连接后,会把这个socket交给poller去处理,Poller不是调用java NIO里的Selector来查询状态,而是通过JNI调用apr里的poll方法,APR又是调用操作系统的 epoll api来实现的。其中有一个参数可以控制,当数据到达时才建立连接,这样优化了性能。
三、其他方面的优化
3.1 缓冲区的不同
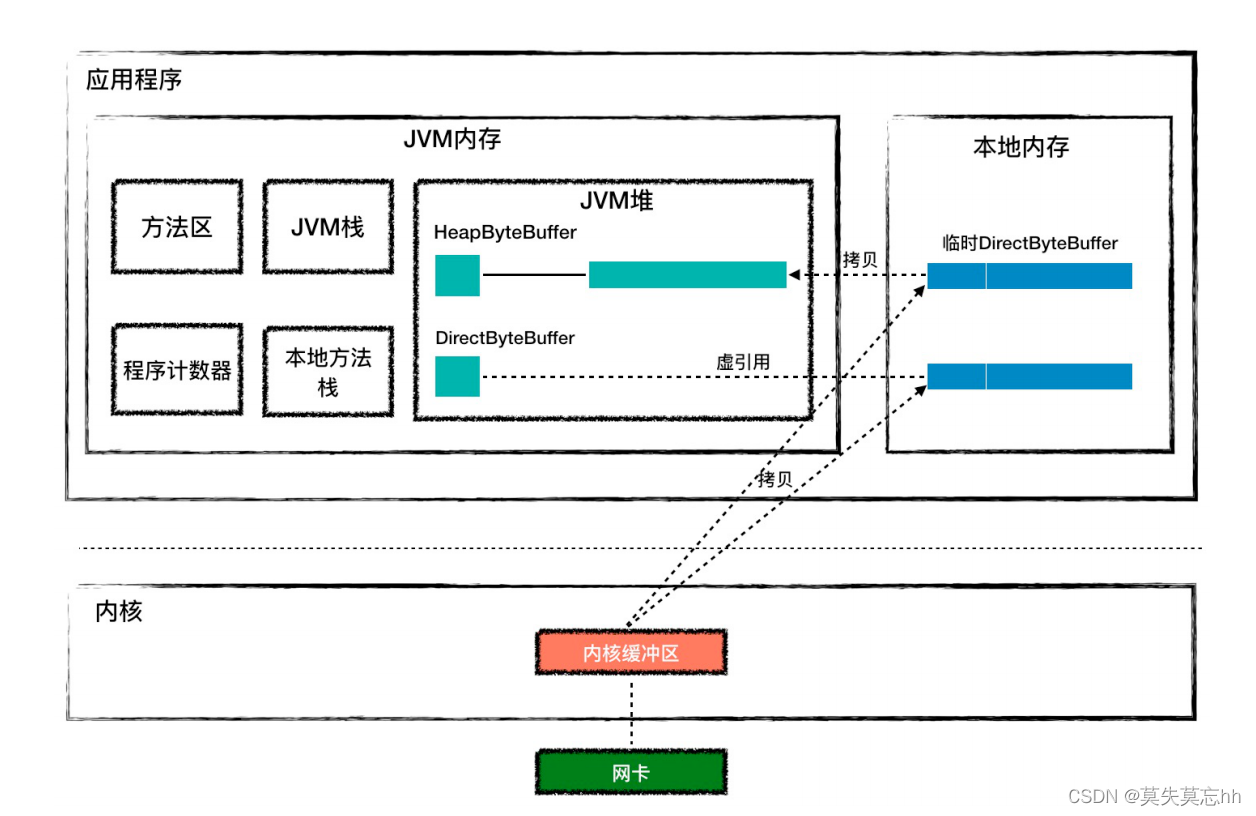
HeapByteBuffer 与 DirectByteBuffer的区别
- HeapByteBuffer复制的时候,数据需要从内核先复杂到 本地内存的临时buffer中,然后再从临时buffer 复制到jvm堆里面,这样会防止在复制的过程中 发生GC
- **DirectByteBuffer也是在 **在jvm堆里面分配内存,而数组的内存是从本地内存分配的。DirectByteBuffer 对象中有个 long 类型字段 address,记录着本地内存的地址,在接收数据的时候,内存地址传递给 C 程序C 程序会将网络数据从内核拷贝到这个本地内存,JVM 可以直接读取这个本地内存,这种方式少了一次复制,所以效率也就会更高
AprEndPoint就是使用DirectByteBuffer缓存取,可以减少拷贝次数。
3.2 零拷贝技术
正常情况,当我们tomcat发生IO时,例如:读取一个数据,然后通过网络发送处理,工作流程如下:
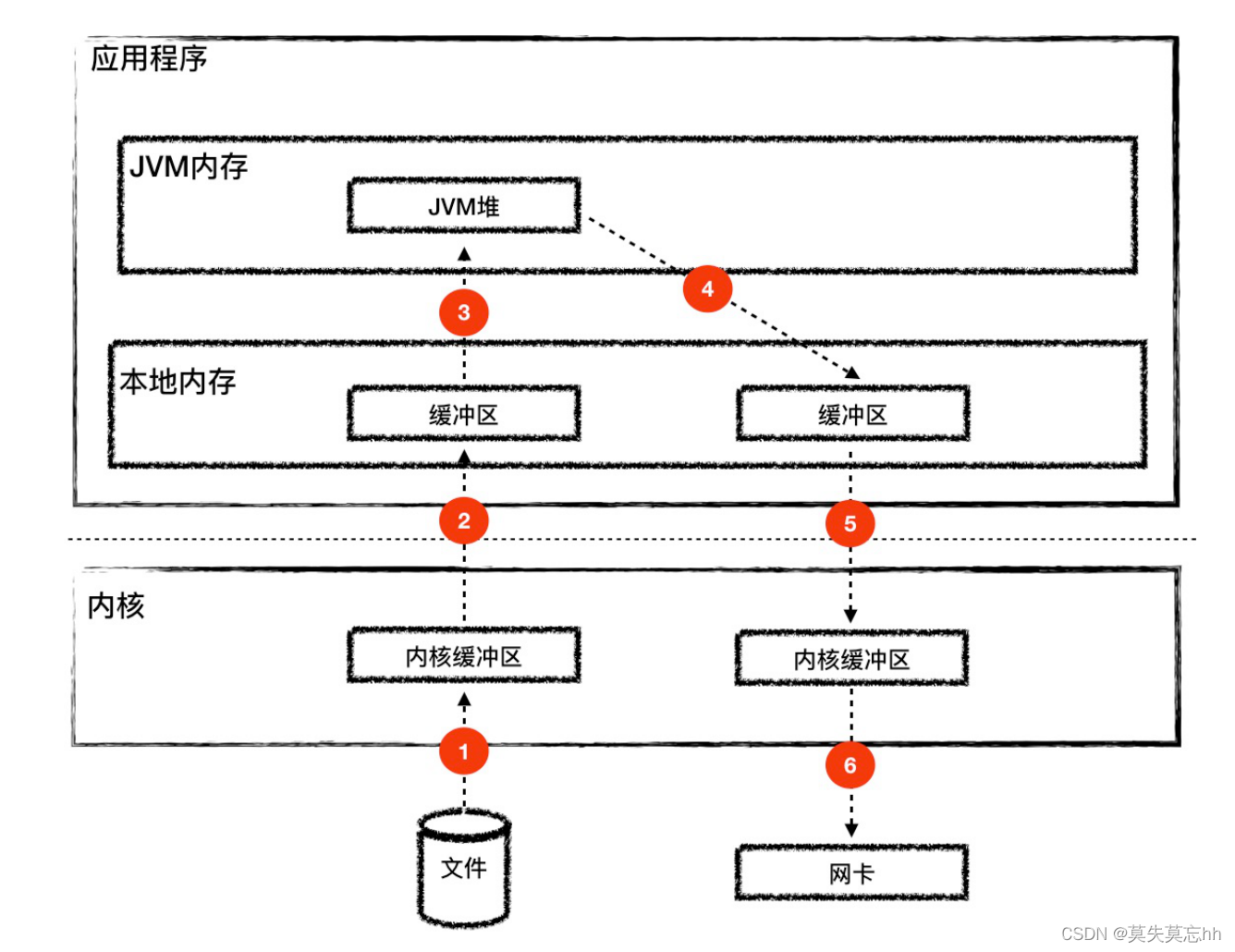
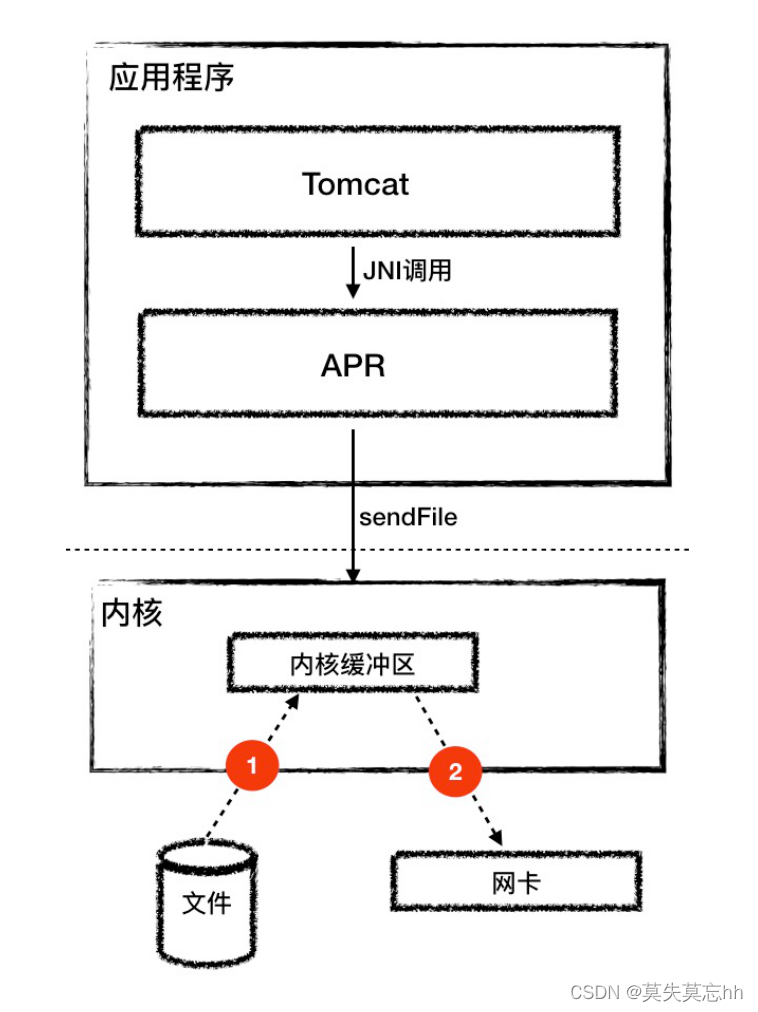
数据发生了6次拷贝,多次在内核态 与用户态之间转换,会耗费大量的cpu资源。但是sendfile可以进行优化,不经过核心到用户态的 拷贝。这其实就是零拷贝技术。
零拷贝的意思 是数据不用在 用户态 和 核心态之间拷贝
参考
极客时间-深入理解Tomcat















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









