






 本文深入探讨了逻辑回归的基础概念,包括Sigmoid函数的特性,如何用它来表示分类概率;接着解释了决策边界的概念,通过设置阈值进行数据分类;最后,介绍了似然函数在最大化概率上下文中的作用,它是找到最优参数的关键。通过这些理论,我们可以更好地理解和应用逻辑回归模型。
本文深入探讨了逻辑回归的基础概念,包括Sigmoid函数的特性,如何用它来表示分类概率;接着解释了决策边界的概念,通过设置阈值进行数据分类;最后,介绍了似然函数在最大化概率上下文中的作用,它是找到最优参数的关键。通过这些理论,我们可以更好地理解和应用逻辑回归模型。
目录
一、sigmod函数
exp 的全称是exponential,即指数函数。exp(x) 与ex 含义相同,只是写法不同。e 是自然常数,具体的值为2.7182 . .
设θTx 为横轴,fθ(x)为纵轴,那么它的图形如下:
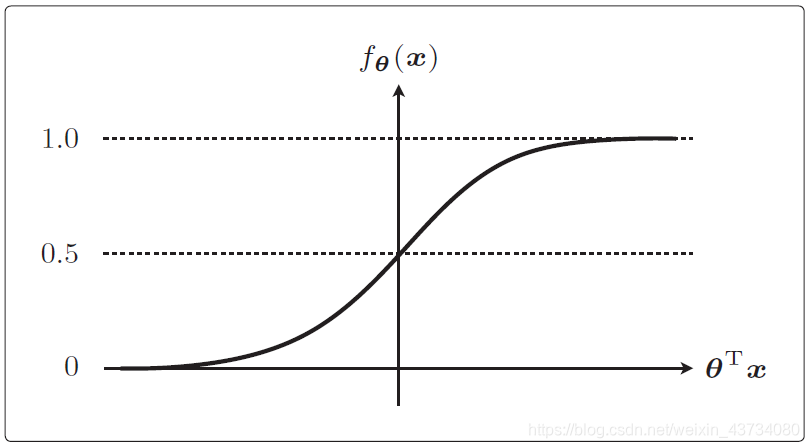
= 0 时fθ(x) = 0.5,以及0 < fθ(x) < 1 是sigmoid 函数的两个特征。
我们可以通过概率来考虑分类。因为sigmoid 函数的取值范围是0 < fθ(x) < 1,所以它可以作为概率来使用。
二、决策边界
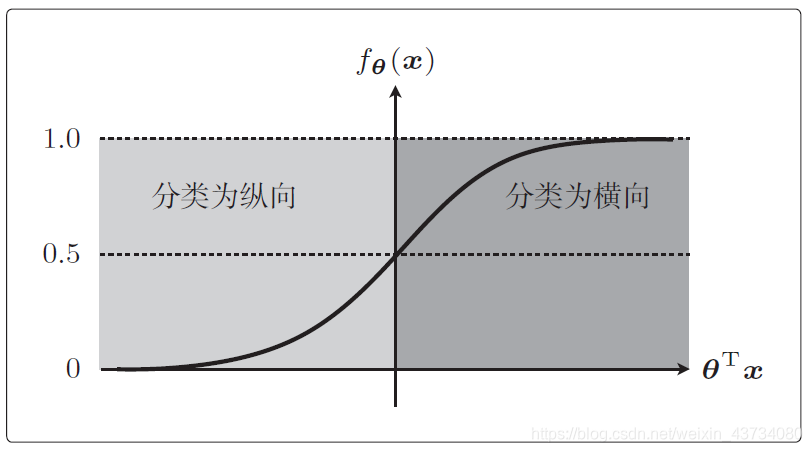
刚才说到把表达式θ(x)当作概率来使用,那么接下来我们就把未知数据x 是横向图像的概率作为fθ(x)。其表达式是这样的。
条件概率。这是在给出x 数据时y = 1,即图像为横向的概率。假如fθ(x)的计算结果是0.7,你认为这是什么意思呢?fθ(x) = 0.7 的意思是图像为横向的概率是70% 吧。一般来说这样就可以把x 分类为横向。如果fθ(x) = 0.2,横向的概率为20%、纵向的概率为80%,这种状态可以分类为纵向。常以0.5 为阈值,然后把fθ(x) 的结果与它相比较,从而分类横向或纵向。
则公式可以写为:
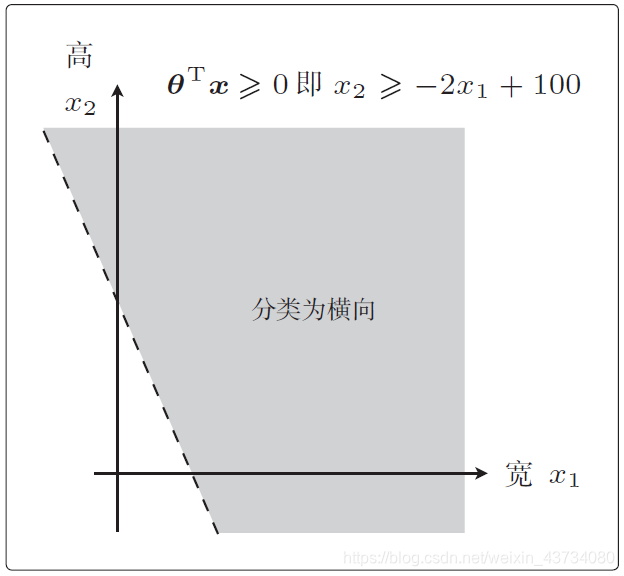
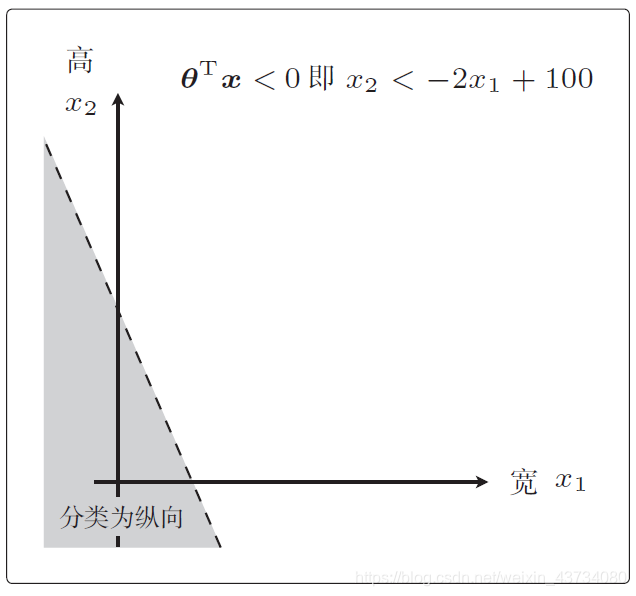
也就是说,我们将 这条直线作为边界线,就可以把这条线两侧的数据分类为横向和纵向了,这样用于数据分类的直线称为决策边界。
实际应用时这个决策边界似乎不能正确地分类图像,这是因为我们决定参数时太随意了,如下图:
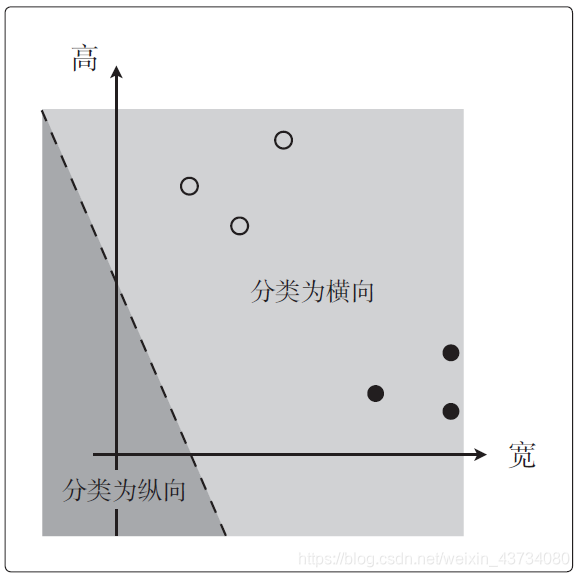
为了求得正确的参数θ 而定义目标函数,进行微分,然后求参数的更新表达式,这种算法就称为逻辑回归。
三、似然函数
基于上述内容我们来求参数的更新表达式
一开始我们把x 为横向的概率P(y = 1|x) 定义为fθ(x) 了。基于这一点,你认为训练数据的标签y 和fθ(x) 是什么样的关系会比较理想呢?
我记得学习回归的时候你也问过这个问题。既然fθ(x) 是x 为横向时的概率……那么在y = 1时fθ(x) = 1,y = 0 时fθ(x) = 0 的关系就是理想
● y = 1的时候,我们希望概率P(y = 1|x) 是最大的
● y = 0 的时候,我们希望概率P(y = 0|x) 是最大的
P(y = 1|x) 是图像为横向的概率,P(y = 0|x) 是图像为纵向的概率,这适用于全部的训练数据。对于一开始列举的那6 个训练数据,我们期待的最大概率是这样的
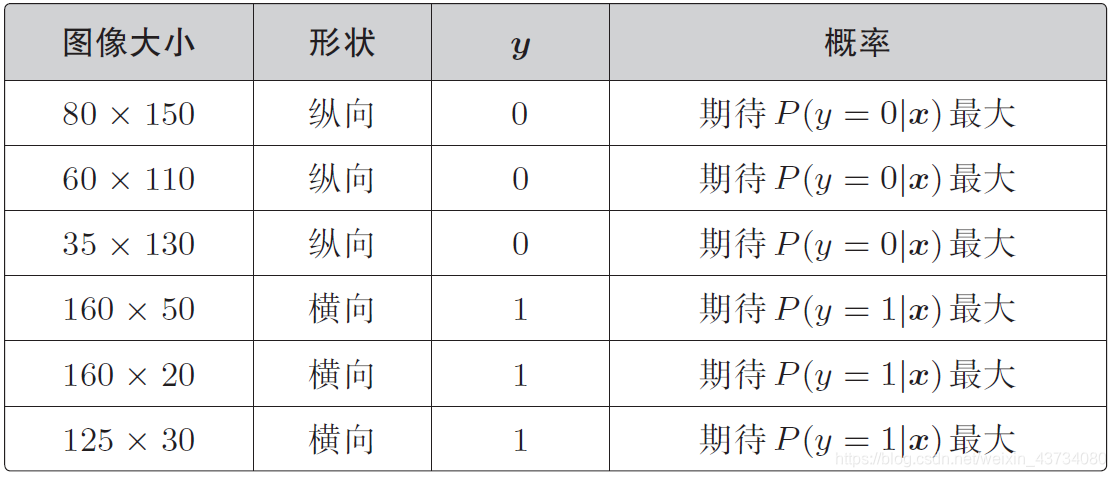
而且,假定所有的训练数据都是互不影响、独立发生的,这种情况下整体的概率就可以用下面的联合概率来表示。
且联合概率的表达式一般化
当
当
比起区分各种情况的写法,汇总到一个表达式的写法更简单。如何得到使这个目标函数最大化的参数θ,回归的时候处理的是误差,所以要最小化,而现在考虑的是联合概率,我们希望概率尽可能大,所以要最大化。这里的目标函数L(θ) 也被称为似然,函数的名字L 取自似然的英文单词Likelihood 的首字母。它的意思是最近似的。我们可以认为似然函数L(θ) 中,使其值最大的参数θ 能够最近似地说明训练数据。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











