








 超级会员免费看
超级会员免费看


目录
三、随机梯度下降法( Stochastic Gradient Descent)
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价受诸多因素影响。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如 图1 所示。
数据下载链接:https://pan.baidu.com/s/1IEuef7z5EZropO-tJUnvbw
提取码:dkmo
图1
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
线性回归模型
模型的求解即是通过数据拟合出每个和
。其中,
和
分别表示该线性模型的权重和偏置。一维情况下,
和
是直线的斜率和截距。
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
思考:
为什么要以均方误差作为损失函数?即将模型在每个训练样本上的预测误差加和,来衡量整体样本的准确性。这是因为损失函数的设计不仅仅要考虑“合理性”,同样需要考虑“易解性”,这个问题在后面的内容中会详细阐述。
线性回归模型的神经网络结构
神经网络的标准结构中每个神经元由加权和与非线性变换构成,然后将多个神经元分层的摆放并连接形成神经网络。线性回归模型可以认为是神经网络模型的一种极简特例,是一个只有加权和、没有非线性变换的神经元(无需形成网络),如 图2 所示。
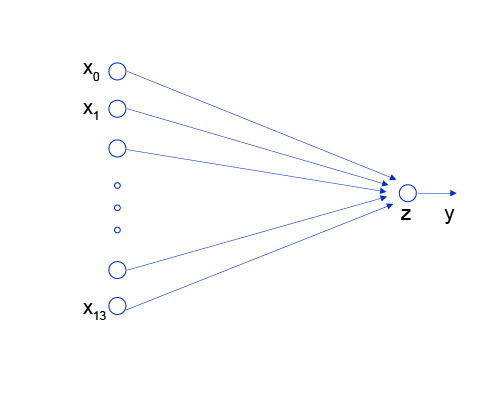
图2
构建波士顿房价预测任务的神经网络模型
深度学习不仅实现了模型的端到端学习,还推动了人工智能进入工业大生产阶段,产生了标准化、自动化和模块化的通用框架。不同场景的深度学习模型具备一定的通用性,五个步骤即可完成模型的构建和训练,如 图3 所示。
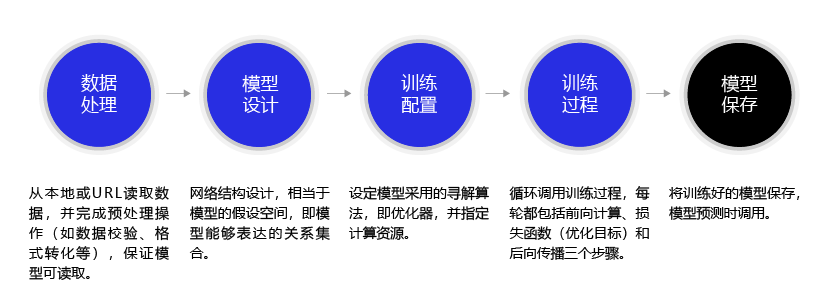
图3:构建神经网络/深度学习模型的基本步骤
正是由于深度学习的建模和训练的过程存在通用性,在构建不同的模型时,只有模型三要素不同,其它步骤基本一致,深度学习框架才有用武之地。
一、数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
说明:
- 本教程中的代码都可以在AI Studio上直接运行,Print结果都是基于程序真实运行的结果。
- 由于是真实案例,代码之间存在依赖关系,因此需要读者逐条、全部运行,否则会导致命令执行报错。
1.1 读入数据
通过如下代码读入数据,了解下波士顿房价的数据集结构,数据存放在本地目录下housing.data文件中。
# 导入需要用到的package
import numpy as np
import json
# 读入训练数据
datafile = 'D:/NoteBook/housing.data'
data = np.fromfile(datafile, sep=' ')
data打印结果
array([6.320e-03, 1.800e+01, 2.310e+00, ..., 3.969e+02, 7.880e+00,
1.190e+01])
1.2 数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个(影响房价的特征)和一个
(该类型房屋的均价)。
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0]//feature_num, feature_num])# 查看数据
x = data[0]
print(x.shape)
print(x)打印结果
(14,) [6.320e-03 1.800e+01 2.310e+00 0.000e+00 5.380e-01 6.575e+00 6.520e+01 4.090e+00 1.000e+00 2.960e+02 1.530e+01 3.969e+02 4.980e+00 2.400e+01]
1.3 数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。为什么要对数据集进行拆分,而不能直接应用于模型训练呢?这与学生时代的授课和考试关系比较类似,如 图4 所示。

上学时总有一些自作聪明的同学,平时不认真学习,考试前临阵抱佛脚,将习题死记硬背下来,但是成绩往往并不好。因为学校期望学生掌握的是知识,而不仅仅是习题本身。另出新的考题,才能鼓励学生努力去掌握习题背后的原理。同样我们期望模型学习的是任务的本质规律,而不是训练数据本身,模型训练未使用的数据,才能更真实的评估模型的效果。
在本案例中,我们将80%的数据用作训练集,20%用作测试集,实现代码如下。通过打印训练集的形状,可以发现共有404个样本,每个样本含有13个特征和1个预测值。
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
training_data.shape打印输出 (404, 14)
1.4 数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = \
training_data.max(axis=0), \
training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])1.5 封装成load data函数
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,实现方法如下。
def load_data():
# 从文件导入数据
datafile = 'D:/NoteBook/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]# 查看数据
print(x[0])
print(y[0])打印结果
[0. 0.18 0.07344184 0. 0.31481481 0.57750527 0.64160659 0.26920314 0. 0.22755741 0.28723404 1. 0.08967991] [0.42222222]
二、模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
如果将输入特征和输出预测值均以向量表示,输入特征x有13个分量,y有1个分量,那么参数权重的形状(shape)是13×1。假设我们以如下任意数字赋值参数做初始化:
w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,−0.1,−0.2,−0.3,−0.4,0.0]
w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]
w = np.array(w).reshape([13, 1])取出第1条样本数据,观察样本的特征向量与参数向量相乘的结果。
x1=x[0]
t = np.dot(x1, w)
print(t)打印结果
[0.69474855]
完整的线性回归公式,还需要初始化偏移量b,同样随意赋初值-0.2。那么,线性回归模型的完整输出是z=t+b,这个从特征和参数计算输出值的过程称为“前向计算”。
b = -0.2
z = t + b
print(z)打印结果
[0.49474855]
将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数w和b。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0)#每次随机数保持不变
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z基于Network类的定义,模型的计算过程如下所示。
net = Network(13)
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)打印输出
[2.39362982]
2.1 训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
通过模型计算x1表示的影响因素所对应的房价应该是z, 但实际数据告诉我们房价是y。这时我们需要有某种指标来衡量预测值z跟真实值y之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
上式中的Loss(简记为: L)通常也被称作损失函数,它是衡量模型好坏的指标。在回归问题中,均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数,在后续的章节中会更详细的介绍。对一个样本计算损失函数值的实现如下:
Loss = (y1 - z)*(y1 - z)
print(Loss)打印结果
[3.88644793]
因为计算损失函数时需要把每个样本的损失函数值都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数N。
在Network类下面添加损失函数的计算过程如下:
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost使用定义的Network类,可以方便的计算预测值和损失函数。需要注意的是,类中的变量x, w,b, z, error等均是向量。以变量x为例,共有两个维度,一个代表特征数量(值为13),一个代表样本数量,代码如下所示。
net = Network(13)
# 此处可以一次性计算多个样本的预测值和损失函数
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print('predict: ', z)
loss = net.loss(z, y1)
print('loss:', loss)打印结果
predict: [[2.39362982][2.46752393][2.02483479]] loss: 3.384496992612791
2.2 训练过程
上述计算过程描述了如何构建神经网络,通过神经网络完成预测值和损失函数的计算。接下来介绍如何求解参数w和b的数值,这个过程也称为模型训练过程。训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数Loss尽可能的小,也就是说找到一个参数解w和b,使得损失函数取得极小值。
我们先做一个小测试:如 图5 所示,基于微积分知识,求一条曲线在某个点的斜率等于函数在该点的导数值。那么大家思考下,当处于曲线的极值点时,该点的斜率是多少?
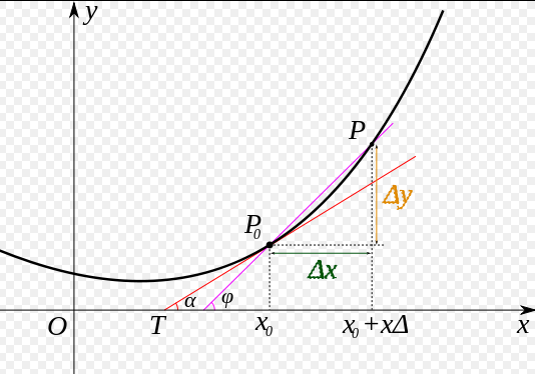
图5:曲线斜率等于导数值
这个问题并不难回答,处于曲线极值点时的斜率为0,即函数在极值点的导数为0。那么,让损失函数取极小值的w和b应该是下述方程组的解:
将样本数据(x,y)带入上面的方程组中即可求解出w和b的值,但是这种方法只对线性回归这样简单的任务有效。如果模型中含有非线性变换,或者损失函数不是均方差这种简单的形式,则很难通过上式求解。为了解决这个问题,下面我们将引入更加普适的数值求解方法:梯度下降法。
2.3 梯度下降法
在现实中存在大量的函数正向求解容易,但反向求解较难,被称为单向函数,这种函数在密码学中有大量的应用。密码锁的特点是可以迅速判断一个密钥是否是正确的(已知x,求y很容易),但是即使获取到密码锁系统,无法破解出正确的密钥是什么(已知y,求x很难)。
这种情况特别类似于一位想从山峰走到坡谷的盲人,他看不见坡谷在哪(无法逆向求解出Loss导数为0时的参数值),但可以伸脚探索身边的坡度(当前点的导数值,也称为梯度)。那么,求解Loss函数最小值可以这样实现:从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点。这种方法笔者称它为“盲人下坡法”。哦不,有个更正式的说法“梯度下降法”。
训练的关键是找到一组(w,b),使得损失函数L取极小值。我们先看一下损失函数L只随两个参数w5、w9变化时的简单情形,启发下寻解的思路。
这里我们将w0,w1,...,w12中除w5,w9之外的参数和b都固定下来,可以用图画出L(w5,w9)的形式。
net = Network(13)
losses = []
#只画出参数w5和w9在区间[-160, 160]的曲线部分,以及包含损失函数的极值
w5 = np.arange(-160.0, 160.0, 1.0)
w9 = np.arange(-160.0, 160.0, 1.0)
losses = np.zeros([len(w5), len(w9)])
#计算设定区域内每个参数取值所对应的Loss
for i in range(len(w5)):
for j in range(len(w9)):
net.w[5] = w5[i]
net.w[9] = w9[j]
z = net.forward(x)
loss = net.loss(z, y)
losses[i, j] = loss
#使用matplotlib将两个变量和对应的Loss作3D图
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
w5, w9 = np.meshgrid(w5, w9)
ax.plot_surface(w5, w9, losses, rstride=1, cstride=1, cmap='rainbow')
plt.show()对于这种简单情形,我们利用上面的程序,可以在三维空间中画出损失函数随参数变化的曲面图。从图中可以看出有些区域的函数值明显比周围的点小。

需要说明的是:为什么这里我们选择w5和w9来画图?这是因为选择这两个参数的时候,可比较直观的从损失函数的曲面图上发现极值点的存在。其他参数组合,从图形上观测损失函数的极值点不够直观。若选取w2和w6来画图,并没有上图直观

观察上述曲线呈现出“圆滑”的坡度,这正是我们选择以均方误差作为损失函数的原因之一。图6 呈现了只有一个参数维度时,均方误差和绝对值误差(只将每个样本的误差累加,不做平方处理)的损失函数曲线图。
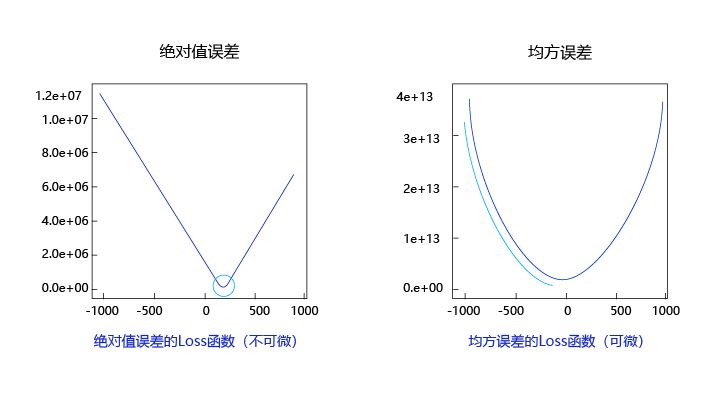
由此可见,均方误差表现的“圆滑”的坡度有两个好处:
- 曲线的最低点是可导的。
- 越接近最低点,曲线的坡度逐渐放缓,有助于通过当前的梯度来判断接近最低点的程度(是否逐渐减少步长,以免错过最低点)。
而绝对值误差是不具备这两个特性的,这也是损失函数的设计不仅仅要考虑“合理性”,还要追求“易解性”的原因。
现在我们要找出一组[w5,w9]的值,使得损失函数最小,实现梯度下降法的方案如下:
- 步骤1:随机的选一组初始值,例如:[w5,w9]=[−100.0,−100.0]
- 步骤2:选取下一个点[w5′,w9′],使得L(w5′,w9′)<L(w5,w9)
- 步骤3:重复步骤2,直到损失函数几乎不再下降。
如何选择[w5′,w9′]是至关重要的,第一要保证L是下降的,第二要使得下降的趋势尽可能的快。微积分的基础知识告诉我们,沿着梯度的反方向,是函数值下降最快的方向,如 图7 所示。简单理解,函数在某一个点的梯度方向是曲线斜率最大的方向,但梯度方向是向上的,所以下降最快的是梯度的反方向。

图7:梯度下降方向示意图
2.4 计算梯度
上面我们讲过了损失函数的计算方法,这里稍微改写,为了使梯度计算更加简洁,引入因子,定义损失函数如下:
其中zi是网络对第iii个样本的预测值:
梯度的定义
可以计算出L对w和b的偏导数:
从导数的计算过程可以看出,因子被消掉了,这是因为二次函数求导的时候会产生因子2,这也是我们将损失函数改写的原因。
下面我们考虑只有一个样本的情况下,计算梯度:
可以计算出:
可以计算出L对w和b的偏导数:
可以通过具体的程序查看每个变量的数据和维度。
x1 = x[0]
y1 = y[0]
z1 = net.forward(x1)
print('x1 {}, shape {}'.format(x1, x1.shape))
print('y1 {}, shape {}'.format(y1, y1.shape))
print('z1 {}, shape {}'.format(z1, z1.shape))打印结果
x1 [0. 0.18 0.07344184 0. 0.31481481 0.57750527 0.64160659 0.26920314 0. 0.22755741 0.28723404 1. 0.08967991], shape (13,) y1 [0.42222222], shape (1,) z1 [115.40486738], shape (1,)
按上面的公式,当只有一个样本时,可以计算某个wj,比如w0的梯度。
gradient_w0 = (z1 - y1) * x1[0]
print('gradient_w0 {}'.format(gradient_w0))打印结果
gradient_w0 [0.]
同样我们可以计算w1的梯度。
gradient_w1 = (z1 - y1) * x1[1]
print('gradient_w1 {}'.format(gradient_w1))打印结果
gradient_w1 [20.69687613]
依次计算w2的梯度。
gradient_w2= (z1 - y1) * x1[2]
print('gradient_w1 {}'.format(gradient_w2))打印结果
gradient_w1 [8.44453726]
聪明的读者可能已经想到,写一个for循环即可计算从w0到w12的所有权重的梯度,该方法读者可以自行实现。
2.5 使用Numpy进行梯度计算
基于Numpy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。计算梯度的代码中直接用(z1−y1)⋅x1,得到的是一个13维的向量,每个分量分别代表该维度的梯度。
gradient_w = (z1 - y1) * x1
print('gradient_w_by_sample1 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))打印结果
gradient_w_by_sample1 [ 0. 20.69687613 8.44453726 0. 36.19824014 66.40308345 73.773623 30.95368902 0. 26.16515307 33.02692999 114.98264516 10.31163346], gradient.shape (13,)
输入数据中有多个样本,每个样本都对梯度有贡献。如上代码计算了只有样本1时的梯度值,同样的计算方法也可以计算样本2和样本3对梯度的贡献。
x2 = x[1]
y2 = y[1]
z2 = net.forward(x2)
gradient_w = (z2 - y2) * x2
print('gradient_w_by_sample2 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))打印结果
gradient_w_by_sample2 [3.94626939e-02 0.00000000e+00 4.38925272e+01 0.00000000e+00 2.89108135e+01 9.16634146e+01 1.30921707e+02 5.83707680e+01 7.27259594e+00 1.92063337e+01 9.25321781e+01 1.67269707e+02 3.42016701e+01], gradient.shape (13,)
可能有的读者再次想到可以使用for循环把每个样本对梯度的贡献都计算出来,然后再作平均。但是我们不需要这么做,仍然可以使用Numpy的矩阵操作来简化运算,如3个样本的情况。
# 注意这里是一次取出3个样本的数据,不是取出第3个样本
x3samples = x[0:3]
y3samples = y[0:3]
z3samples = net.forward(x3samples)
print('x {}, shape {}'.format(x3samples, x3samples.shape))
print('y {}, shape {}'.format(y3samples, y3samples.shape))
print('z {}, shape {}'.format(z3samples, z3samples.shape))打印结果
x [[0.00000000e+00 1.80000000e-01 7.34418420e-02 0.00000000e+00 3.14814815e-01 5.77505269e-01 6.41606591e-01 2.69203139e-01 0.00000000e+00 2.27557411e-01 2.87234043e-01 1.00000000e+00 8.96799117e-02] [2.35922539e-04 0.00000000e+00 2.62405717e-01 0.00000000e+00 1.72839506e-01 5.47997701e-01 7.82698249e-01 3.48961980e-01 4.34782609e-02 1.14822547e-01 5.53191489e-01 1.00000000e+00 2.04470199e-01] [2.35697744e-04 0.00000000e+00 2.62405717e-01 0.00000000e+00 1.72839506e-01 6.94385898e-01 5.99382080e-01 3.48961980e-01 4.34782609e-02 1.14822547e-01 5.53191489e-01 9.87519166e-01 6.34657837e-02]], shape (3, 13) y [[0.42222222] [0.36888889] [0.66 ]], shape (3, 1) z [[115.40486738] [167.63859551] [138.22280208]], shape (3, 1)
上面的x3samples, y3samples, z3samples的第一维大小均为3,表示有3个样本。下面计算这3个样本对梯度的贡献。
gradient_w = (z3samples - y3samples) * x3samples
print('gradient_w {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))打印结果
gradient_w [[0.00000000e+00 2.06968761e+01 8.44453726e+00 0.00000000e+00 3.61982401e+01 6.64030834e+01 7.37736230e+01 3.09536890e+01 0.00000000e+00 2.61651531e+01 3.30269300e+01 1.14982645e+02 1.03116335e+01] [3.94626939e-02 0.00000000e+00 4.38925272e+01 0.00000000e+00 2.89108135e+01 9.16634146e+01 1.30921707e+02 5.83707680e+01 7.27259594e+00 1.92063337e+01 9.25321781e+01 1.67269707e+02 3.42016701e+01] [3.24232421e-02 0.00000000e+00 3.60972657e+01 0.00000000e+00 2.37762868e+01 9.55216698e+01 8.24526785e+01 4.80041878e+01 5.98099139e+00 1.57953113e+01 7.60985714e+01 1.35845904e+02 8.73053104e+00]], gradient.shape (3, 13)
此处可见,计算梯度gradient_w的维度是3×133 ,并且其第1行与上面第1个样本计算的梯度gradient_w_by_sample1一致,第2行与上面第2个样本计算的梯度gradient_w_by_sample2一致,第3行与上面第3个样本计算的梯度gradient_w_by_sample3一致。这里使用矩阵操作,可以更加方便的对3个样本分别计算各自对梯度的贡献。
那么对于有N个样本的情形,我们可以直接使用如下方式计算出所有样本对梯度的贡献,这就是使用Numpy库广播功能带来的便捷。 小结一下这里使用Numpy库的广播功能:
- 一方面可以扩展参数的维度,代替for循环来计算1个样本对从w0到w12的所有参数的梯度。
- 另一方面可以扩展样本的维度,代替for循环来计算样本0到样本403对参数的梯度。
z = net.forward(x)
gradient_w = (z - y) * x
print('gradient_w shape {}'.format(gradient_w.shape))
print(gradient_w)打印结果
gradient_w shape (404, 13) [[0.00000000e+00 2.06968761e+01 8.44453726e+00 ... 3.30269300e+01 1.14982645e+02 1.03116335e+01] [3.94626939e-02 0.00000000e+00 4.38925272e+01 ... 9.25321781e+01 1.67269707e+02 3.42016701e+01] [3.24232421e-02 0.00000000e+00 3.60972657e+01 ... 7.60985714e+01 1.35845904e+02 8.73053104e+00] ... [4.37440950e+01 0.00000000e+00 1.91527710e+02 ... 2.21129631e+02 2.73502438e+02 1.40298298e+02] [2.94457614e+01 0.00000000e+00 1.91313328e+02 ... 2.20882114e+02 2.55779093e+02 1.40065873e+02] [7.44978133e+01 0.00000000e+00 1.87191522e+02 ... 2.16123255e+02 2.67310342e+02 1.33065082e+02]]
上面gradient_w的每一行代表了一个样本对梯度的贡献。根据梯度的计算公式,总梯度是对每个样本对梯度贡献的平均值。
我们也可以使用Numpy的均值函数来完成此过程:
# axis = 0 表示把每一行做相加然后再除以总的行数
gradient_w = np.mean(gradient_w, axis=0)
print('gradient_w ', gradient_w.shape)
print('w ', net.w.shape)
print(gradient_w)
print(net.w)打印结果
gradient_w (13,) w (13, 1) [ 5.53780571 10.64543906 75.67827617 17.61268347 63.65268301 80.73011068 123.00673216 31.66093111 51.21598571 68.06824792 96.34753654 148.59539397 51.95466115] [[ 1.76405235e+00] [ 4.00157208e-01] [ 1.59000000e+02] [ 2.24089320e+00] [ 1.86755799e+00] [-9.77277880e-01] [ 1.59000000e+02] [-1.51357208e-01] [-1.03218852e-01] [ 4.10598502e-01] [ 1.44043571e-01] [ 1.45427351e+00] [ 7.61037725e-01]]
我们使用Numpy的矩阵操作方便地完成了gradient的计算,但引入了一个问题,gradient_w的形状是(13,),而w的维度是(13, 1)。导致该问题的原因是使用np.mean函数时消除了第0维。为了加减乘除等计算方便,gradient_w和w必须保持一致的形状。因此我们将gradient_w的维度也设置为(13,1),代码如下:
gradient_w = gradient_w[:, np.newaxis]
print('gradient_w shape', gradient_w.shape)综合上面的剖析,计算梯度的代码如下所示。
z = net.forward(x)
gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_w打印结果
array([[ 4.6555403 ],
[ 19.35268996],
[ 55.88081118],
[ 14.00266972],
[ 47.98588869],
[ 76.87210821],
[ 94.8555119 ],
[ 36.07579608],
[ 45.44575958],
[ 59.65733292],
[ 83.65114918],
[134.80387478],
[ 38.93998153]])
上述代码非常简洁地完成了w的梯度计算。同样,计算b的梯度的代码也是类似的原理。
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
# 此处b是一个数值,所以可以直接用np.mean得到一个标量
gradient_b打印结果
159.47184398759848
将上面计算w和b的梯度的过程,写成Network类的gradient函数,实现方法如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b# 调用上面定义的gradient函数,计算梯度
# 初始化网络
net = Network(13)
# 设置[w5, w9] = [-100., -100.]
net.w[5] = -100.0
net.w[9] = -100.0
z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))point [-100.0, -100.0], loss 7873.345739941161 gradient [-45.87968288123223, -35.50236884482904]
2.6 确定损失函数更小的点
下面我们开始研究更新梯度的方法。首先沿着梯度的反方向移动一小步,找到下一个点P1,观察损失函数的变化。
# 在[w5, w9]平面上,沿着梯度的反方向移动到下一个点P1
# 定义移动步长 eta
eta = 0.1
# 更新参数w5和w9
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
# 重新计算z和loss
z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))打印结果
point [-95.41203171187678, -96.4497631155171], loss 7214.694816482369 gradient [-43.883932999069096, -34.019273908495926]
运行上面的代码,可以发现沿着梯度反方向走一小步,下一个点的损失函数的确减少了。感兴趣的话,大家可以尝试不停的点击上面的代码块,观察损失函数是否一直在变小。
在上述代码中,每次更新参数使用的语句: net.w[5] = net.w[5] - eta * gradient_w5
- 相减:参数需要向梯度的反方向移动。
- eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
大家可以思考下,为什么之前我们要做输入特征的归一化,保持尺度一致?这是为了让统一的步长更加合适。
如 图8 所示,特征输入归一化后,不同参数输出的Loss是一个比较规整的曲线,学习率可以设置成统一的值 ;特征输入未归一化时,不同特征对应的参数所需的步长不一致,尺度较大的参数需要大步长,尺寸较小的参数需要小步长,导致无法设置统一的学习率。
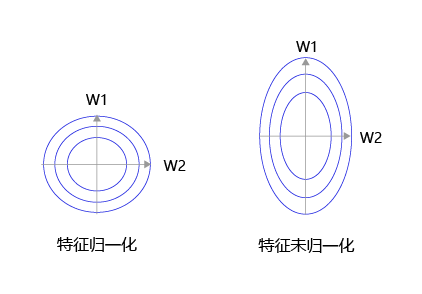
图8:未归一化的特征,会导致不同特征维度的理想步长不同
2.7 代码封装Train函数
将上面的循环计算过程封装在train和update函数中,实现方法如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights,1)
self.w[5] = -100.
self.w[9] = -100.
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w5, gradient_w9, eta=0.01):
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
def train(self, x, y, iterations=100, eta=0.01):
points = []
losses = []
for i in range(iterations):
points.append([net.w[5][0], net.w[9][0]])
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
self.update(gradient_w5, gradient_w9, eta)
losses.append(L)
if i % 50 == 0:
print('iter {}, point {}, loss {}'.format(i, [net.w[5][0], net.w[9][0]], L))
return points, losses
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=2000
# 启动训练
points, losses = net.train(x, y, iterations=num_iterations, eta=0.01)
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()打印结果
iter 0, point [-99.54120317118768, -99.64497631155172], loss 7873.345739941161 iter 50, point [-78.9761810944732, -83.65939206734069], loss 5131.480704109405 iter 100, point [-62.4493631356931, -70.67918223434114], loss 3346.754494352463 iter 150, point [-49.17799206644332, -60.12620415441553], loss 2184.906016270654 iter 200, point [-38.53070194231174, -51.533984751788346], loss 1428.4172504483342 iter 250, point [-29.998249130283174, -44.52613603923428], loss 935.7392894242679 iter 300, point [-23.169901624519575, -38.79894318028118], loss 614.7592258739251 iter 350, point [-17.71439280083778, -34.10731848231335], loss 405.53408184471505 iter 400, point [-13.364557220746388, -30.253470630210863], loss 269.0551396220099 iter 450, point [-9.904936677384967, -27.077764259976597], loss 179.9364750604248 iter 500, point [-7.161782280775628, -24.451346444229817], loss 121.65711285489998 iter 550, point [-4.994989383373879, -22.270198517465555], loss 83.46491706360901 iter 600, point [-3.2915916915280783, -20.450337700789422], loss 58.36183370758033 iter 650, point [-1.9605131425212885, -18.923946252536773], loss 41.792808952534 iter 700, point [-0.9283343968114077, -17.636248840494844], loss 30.792614998570482 iter 750, point [-0.13587780041668718, -16.542993494033716], loss 23.43065354742935 iter 800, point [0.4645474092373408, -15.60841945615185], loss 18.449664464381506 iter 850, point [0.9113672926170796, -14.803617811655524], loss 15.030615923519784 iter 900, point [1.2355357562745004, -14.105208963393421], loss 12.639705730905764 iter 950, point [1.4619805189121953, -13.494275706622066], loss 10.928795653764196 iter 1000, point [1.6107694974712377, -12.955502492189021], loss 9.670616807081698 iter 1050, point [1.6980516626374353, -12.476481020835202], loss 8.716602071285436 iter 1100, point [1.7368159644039771, -12.04715001603925], loss 7.969442965176621 iter 1150, point [1.7375034995020395, -11.659343238414994], loss 7.365228465612388 iter 1200, point [1.7085012931271857, -11.306424818680442], loss 6.861819342703047 iter 1250, point [1.6565405824483015, -10.982995030930885], loss 6.431280353078019 iter 1300, point [1.5870180647823104, -10.684652890749808], loss 6.054953198278096 iter 1350, point [1.5042550040699705, -10.407804594738165], loss 5.720248083137862 iter 1400, point [1.4117062100403601, -10.14950894127009], loss 5.418553777303124 iter 1450, point [1.3121285818148223, -9.907352585055445], loss 5.143875665274019 iter 1500, point [1.2077170340724794, -9.67934935975478], loss 4.891947653805328 iter 1550, point [1.1002141124777076, -9.463859017459276], loss 4.659652555766873 iter 1600, point [0.990998385834045, -9.259521632951046], loss 4.444643323159747 iter 1650, point [0.8811557188942747, -9.065204645952335], loss 4.245095084874306 iter 1700, point [0.7715367363576023, -8.87996009965401], loss 4.059542401818773 iter 1750, point [0.662803148565214, -8.702990105791185], loss 3.88677206759292 iter 1800, point [0.5554650931141796, -8.533618947271485], loss 3.7257521401326525 iter 1850, point [0.4499112301277286, -8.371270536496699], loss 3.5755846299900256 iter 1900, point [0.3464329929523944, -8.215450195281456], loss 3.435473657404253 iter 1950, point [0.24524412503452966, -8.065729922139326], loss 3.3047037451160453

2.8 训练扩展到全部参数
为了能给读者直观的感受,上面演示的梯度下降的过程仅包含w5和w9两个参数,但房价预测的完整模型,必须要对所有参数w和b进行求解。这需要将Network中的update和train函数进行修改。由于不再限定参与计算的参数(所有参数均参与计算),修改之后的代码反而更加简洁。实现逻辑:“前向计算输出、根据输出和真实值计算Loss、基于Loss和输入计算梯度、根据梯度更新参数值”四个部分反复执行,直到到损失函数最小。具体代码如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, x, y, iterations=100, eta=0.01):
losses = []
for i in range(iterations):
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
if (i+1) % 10 == 0:
print('iter {}, loss {}'.format(i, L))
return losses
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=1000
# 启动训练
losses = net.train(x,y, iterations=num_iterations, eta=0.01)
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()打印结果
iter 9, loss 5.143394325795511 iter 19, loss 3.097924194225988 iter 29, loss 2.082241020617026 iter 39, loss 1.5673801618157397 iter 49, loss 1.296620473507743 iter 59, loss 1.1453399043319765 iter 69, loss 1.0530155717435201 iter 79, loss 0.9902292156463153 iter 89, loss 0.9426576903842502 iter 99, loss 0.9033048096880774 iter 109, loss 0.868732003041364 iter 119, loss 0.837229250968144 iter 129, loss 0.807927474161227 iter 139, loss 0.7803677341465796 iter 149, loss 0.7542920908532763 iter 159, loss 0.7295420168915829 iter 169, loss 0.7060090054240883 iter 179, loss 0.6836105084697766 iter 189, loss 0.6622781710179414 iter 199, loss 0.6419520361168637 iter 209, loss 0.6225776517869489 iter 219, loss 0.6041045903195837 iter 229, loss 0.5864856570315078 iter 239, loss 0.5696764374763879 iter 249, loss 0.5536350125932016 iter 259, loss 0.5383217588525027 iter 269, loss 0.5236991929680566 iter 279, loss 0.5097318413761649 iter 289, loss 0.4963861247069634 iter 299, loss 0.48363025234390233 iter 309, loss 0.4714341245401978 iter 319, loss 0.45976924072044867 iter 329, loss 0.44860861316591 iter 339, loss 0.43792668556597936 iter 349, loss 0.4276992560632111 iter 359, loss 0.4179034044959738 iter 369, loss 0.40851742358635523 iter 379, loss 0.39952075384787633 iter 389, loss 0.39089392200622347 iter 399, loss 0.3826184827405131 iter 409, loss 0.37467696356451247 iter 419, loss 0.36705281267772816 iter 429, loss 0.35973034962581096 iter 439, loss 0.35269471861856694 iter 449, loss 0.3459318443621334 iter 459, loss 0.3394283902696658 iter 469, loss 0.3331717189222164 iter 479, loss 0.3271498546584252 iter 489, loss 0.32135144817819605 iter 499, loss 0.31576574305173283 iter 509, loss 0.3103825440311681 iter 519, loss 0.30519218706757245 iter 529, loss 0.30018551094136725 iter 539, loss 0.29535383041913843 iter 549, loss 0.29068891085453674 iter 559, loss 0.28618294415539336 iter 569, loss 0.28182852604338504 iter 579, loss 0.2776186345365534 iter 589, loss 0.27354660958874766 iter 599, loss 0.2696061338236152 iter 609, loss 0.265791214304132 iter 619, loss 0.262096165281848 iter 629, loss 0.258515591873034 iter 639, loss 0.25504437461176843 iter 649, loss 0.2516776548326958 iter 659, loss 0.24841082083874047 iter 669, loss 0.24523949481147192 iter 679, loss 0.2421595204240984 iter 689, loss 0.23916695111922887 iter 699, loss 0.23625803901558054 iter 709, loss 0.2334292244097483 iter 719, loss 0.23067712584097294 iter 729, loss 0.22799853068858242 iter 739, loss 0.22539038627340988 iter 749, loss 0.22284979143604464 iter 759, loss 0.22037398856623475 iter 769, loss 0.2179603560591435 iter 779, loss 0.2156064011754777 iter 789, loss 0.2133097532837386 iter 799, loss 0.2110681574640261 iter 809, loss 0.2088794684539304 iter 819, loss 0.20674164491810018 iter 829, loss 0.20465274402406475 iter 839, loss 0.20261091630783168 iter 849, loss 0.20061440081366638 iter 859, loss 0.1986615204933024 iter 869, loss 0.19675067785062839 iter 879, loss 0.19488035081864621 iter 889, loss 0.19304908885621125 iter 899, loss 0.19125550925273513 iter 909, loss 0.1894982936296714 iter 919, loss 0.18777618462820622 iter 929, loss 0.18608798277314595 iter 939, loss 0.18443254350353405 iter 949, loss 0.18280877436103968 iter 959, loss 0.18121563232764162 iter 969, loss 0.1796521213045923 iter 979, loss 0.1781172897250724 iter 989, loss 0.17661022829336184 iter 999, loss 0.17513006784373505

三、随机梯度下降法( Stochastic Gradient Descent)
在上述程序中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于波士顿房价预测任务数据集而言,样本数比较少,只有404个。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低,通俗地说就是“杀鸡焉用牛刀”。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
- mini-batch:每次迭代时抽取出来的一批数据被称为一个mini-batch。
- batch_size:一个mini-batch所包含的样本数目称为batch_size。
- epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
下面结合程序介绍具体的实现过程,涉及到数据处理和训练过程两部分代码的修改。
3.1 数据处理代码修改
数据处理需要实现拆分数据批次和样本乱序(为了实现随机抽样的效果)两个功能。
# 获取数据
train_data, test_data = load_data()
train_data.shape打印结果
(404, 14)
train_data中一共包含404条数据,如果batch_size=10,即取前0-9号样本作为第一个mini-batch,命名train_data1。
train_data1 = train_data[0:10]
train_data1.shape(10, 14)
使用train_data1的数据(0-9号样本)计算梯度并更新网络参数。
net = Network(13)
x = train_data1[:, :-1]
y = train_data1[:, -1:]
loss = net.train(x, y, iterations=1, eta=0.01)
loss[4.497480200683046]
再取出10-19号样本作为第二个mini-batch,计算梯度并更新网络参数。
train_data2 = train_data[10:20]
x = train_data2[:, :-1]
y = train_data2[:, -1:]
loss = net.train(x, y, iterations=1, eta=0.01)
loss[5.849682302465982]
按此方法不断的取出新的mini-batch,并逐渐更新网络参数。
接下来,将train_data分成大小为batch_size的多个mini_batch,如下代码所示:将train_data分成 个 mini_batch,其中前40个mini_batch,每个均含有10个样本,最后一个mini_batch只含有4个样本。
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
print('total number of mini_batches is ', len(mini_batches))
print('first mini_batch shape ', mini_batches[0].shape)
print('last mini_batch shape ', mini_batches[-1].shape)total number of mini_batches is 41 first mini_batch shape (10, 14) last mini_batch shape (4, 14)
另外,这里是按顺序读取mini_batch,而SGD里面是随机抽取一部分样本代表总体。为了实现随机抽样的效果,我们先将train_data里面的样本顺序随机打乱,然后再抽取mini_batch。随机打乱样本顺序,需要用到np.random.shuffle函数,下面先介绍它的用法。
说明:
通过大量实验发现,模型对最后出现的数据印象更加深刻。训练数据导入后,越接近模型训练结束,最后几个批次数据对模型参数的影响越大。为了避免模型记忆影响训练效果,需要进行样本乱序操作。
# 新建一个array
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
print('before shuffle', a)
np.random.shuffle(a)
print('after shuffle', a)before shuffle [ 1 2 3 4 5 6 7 8 9 10 11 12] after shuffle [ 7 2 11 3 8 6 12 1 4 5 10 9]
多次运行上面的代码,可以发现每次执行shuffle函数后的数字顺序均不同。 上面举的是一个1维数组乱序的案例,我们再观察下2维数组乱序后的效果。
# 新建一个array
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
a = a.reshape([6, 2])
print('before shuffle\n', a)
np.random.shuffle(a)
print('after shuffle\n', a)before shuffle [[ 1 2] [ 3 4] [ 5 6] [ 7 8] [ 9 10] [11 12]] after shuffle [[ 1 2] [ 3 4] [ 5 6] [ 9 10] [11 12] [ 7 8]]
观察运行结果可发现,数组的元素在第0维被随机打乱,但第1维的顺序保持不变。例如数字2仍然紧挨在数字1的后面,数字8仍然紧挨在数字7的后面,而第二维的[3, 4]并不排在[1, 2]的后面。将这部分实现SGD算法的代码集成到Network类中的train函数中,最终的完整代码如下。
# 获取数据
train_data, test_data = load_data()
# 打乱样本顺序
np.random.shuffle(train_data)
# 将train_data分成多个mini_batch
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
# 创建网络
net = Network(13)
# 依次使用每个mini_batch的数据
for mini_batch in mini_batches:
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
loss = net.train(x, y, iterations=1)3.2 训练过程代码修改
将每个随机抽取的mini-batch数据输入到模型中用于参数训练。训练过程的核心是两层循环:
- 第一层循环,代表样本集合要被训练遍历几次,称为“epoch”,代码如下:
for epoch_id in range(num_epochs):
- 第二层循环,代表每次遍历时,样本集合被拆分成的多个批次,需要全部执行训练,称为“iter (iteration)”,代码如下:
for iter_id,mini_batch in emumerate(mini_batches):
在两层循环的内部是经典的四步训练流程:前向计算->计算损失->计算梯度->更新参数,这与大家之前所学是一致的,代码如下:
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x) #前向计算
loss = self.loss(a, y) #计算损失
gradient_w, gradient_b = self.gradient(x, y) #计算梯度
self.update(gradient_w, gradient_b, eta) #更新参数将两部分改写的代码集成到Network类中的train函数中,最终的实现如下。
import numpy as np
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
#np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
N = x.shape[0]
gradient_w = 1. / N * np.sum((z-y) * x, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = 1. / N * np.sum(z-y)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epochs, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epochs):
# 在每轮迭代开始之前,将训练数据的顺序随机打乱
# 然后再按每次取batch_size条数据的方式取出
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据
mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
#print(self.w.shape)
#print(self.b)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epochs=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()Epoch 0 / iter 0, loss = 1.0281 Epoch 0 / iter 1, loss = 0.5048 Epoch 0 / iter 2, loss = 0.6382 Epoch 0 / iter 3, loss = 0.5168 Epoch 0 / iter 4, loss = 0.1951 Epoch 1 / iter 0, loss = 0.6281 Epoch 1 / iter 1, loss = 0.4611 Epoch 1 / iter 2, loss = 0.4520 Epoch 1 / iter 3, loss = 0.3961 Epoch 1 / iter 4, loss = 0.1381 Epoch 2 / iter 0, loss = 0.5642 Epoch 2 / iter 1, loss = 0.4250 Epoch 2 / iter 2, loss = 0.4480 Epoch 2 / iter 3, loss = 0.3881 Epoch 2 / iter 4, loss = 0.1884 Epoch 3 / iter 0, loss = 0.3921 Epoch 3 / iter 1, loss = 0.5582 Epoch 3 / iter 2, loss = 0.3759 Epoch 3 / iter 3, loss = 0.3849 Epoch 3 / iter 4, loss = 0.1425 Epoch 4 / iter 0, loss = 0.3821 Epoch 4 / iter 1, loss = 0.4382 Epoch 4 / iter 2, loss = 0.3864 Epoch 4 / iter 3, loss = 0.4314 Epoch 4 / iter 4, loss = 0.0471 Epoch 5 / iter 0, loss = 0.4264 Epoch 5 / iter 1, loss = 0.3829 Epoch 5 / iter 2, loss = 0.3179 Epoch 5 / iter 3, loss = 0.4149 Epoch 5 / iter 4, loss = 0.1581 Epoch 6 / iter 0, loss = 0.3148 Epoch 6 / iter 1, loss = 0.3532 Epoch 6 / iter 2, loss = 0.4195 Epoch 6 / iter 3, loss = 0.3272 Epoch 6 / iter 4, loss = 1.2465 Epoch 7 / iter 0, loss = 0.3166 Epoch 7 / iter 1, loss = 0.2810 Epoch 7 / iter 2, loss = 0.4126 Epoch 7 / iter 3, loss = 0.3309 Epoch 7 / iter 4, loss = 0.2255 Epoch 8 / iter 0, loss = 0.2555 Epoch 8 / iter 1, loss = 0.3678 Epoch 8 / iter 2, loss = 0.3342 Epoch 8 / iter 3, loss = 0.3806 Epoch 8 / iter 4, loss = 0.0570 Epoch 9 / iter 0, loss = 0.3532 Epoch 9 / iter 1, loss = 0.3973 Epoch 9 / iter 2, loss = 0.1945 Epoch 9 / iter 3, loss = 0.2839 Epoch 9 / iter 4, loss = 0.1604 Epoch 10 / iter 0, loss = 0.3414 Epoch 10 / iter 1, loss = 0.2774 Epoch 10 / iter 2, loss = 0.3439 Epoch 10 / iter 3, loss = 0.2103 Epoch 10 / iter 4, loss = 0.0959 Epoch 11 / iter 0, loss = 0.3004 Epoch 11 / iter 1, loss = 0.2497 Epoch 11 / iter 2, loss = 0.2827 Epoch 11 / iter 3, loss = 0.2987 Epoch 11 / iter 4, loss = 0.0316 Epoch 12 / iter 0, loss = 0.2509 Epoch 12 / iter 1, loss = 0.2535 Epoch 12 / iter 2, loss = 0.2944 Epoch 12 / iter 3, loss = 0.2889 Epoch 12 / iter 4, loss = 0.0547 Epoch 13 / iter 0, loss = 0.2792 Epoch 13 / iter 1, loss = 0.2137 Epoch 13 / iter 2, loss = 0.2427 Epoch 13 / iter 3, loss = 0.2986 Epoch 13 / iter 4, loss = 0.3861 Epoch 14 / iter 0, loss = 0.3261 Epoch 14 / iter 1, loss = 0.2123 Epoch 14 / iter 2, loss = 0.1837 Epoch 14 / iter 3, loss = 0.2968 Epoch 14 / iter 4, loss = 0.0620 Epoch 15 / iter 0, loss = 0.2402 Epoch 15 / iter 1, loss = 0.2823 Epoch 15 / iter 2, loss = 0.2574 Epoch 15 / iter 3, loss = 0.1833 Epoch 15 / iter 4, loss = 0.0637 Epoch 16 / iter 0, loss = 0.1889 Epoch 16 / iter 1, loss = 0.1998 Epoch 16 / iter 2, loss = 0.2031 Epoch 16 / iter 3, loss = 0.3219 Epoch 16 / iter 4, loss = 0.1373 Epoch 17 / iter 0, loss = 0.2042 Epoch 17 / iter 1, loss = 0.2070 Epoch 17 / iter 2, loss = 0.2651 Epoch 17 / iter 3, loss = 0.2137 Epoch 17 / iter 4, loss = 0.0138 Epoch 18 / iter 0, loss = 0.1794 Epoch 18 / iter 1, loss = 0.1575 Epoch 18 / iter 2, loss = 0.2554 Epoch 18 / iter 3, loss = 0.2531 Epoch 18 / iter 4, loss = 0.2192 Epoch 19 / iter 0, loss = 0.1779 Epoch 19 / iter 1, loss = 0.2072 Epoch 19 / iter 2, loss = 0.2140 Epoch 19 / iter 3, loss = 0.2513 Epoch 19 / iter 4, loss = 0.0673 Epoch 20 / iter 0, loss = 0.1634 Epoch 20 / iter 1, loss = 0.1887 Epoch 20 / iter 2, loss = 0.2515 Epoch 20 / iter 3, loss = 0.1924 Epoch 20 / iter 4, loss = 0.0926 Epoch 21 / iter 0, loss = 0.1583 Epoch 21 / iter 1, loss = 0.2319 Epoch 21 / iter 2, loss = 0.1550 Epoch 21 / iter 3, loss = 0.2092 Epoch 21 / iter 4, loss = 0.1959 Epoch 22 / iter 0, loss = 0.2414 Epoch 22 / iter 1, loss = 0.1522 Epoch 22 / iter 2, loss = 0.1719 Epoch 22 / iter 3, loss = 0.1829 Epoch 22 / iter 4, loss = 0.2748 Epoch 23 / iter 0, loss = 0.1861 Epoch 23 / iter 1, loss = 0.1830 Epoch 23 / iter 2, loss = 0.1606 Epoch 23 / iter 3, loss = 0.2351 Epoch 23 / iter 4, loss = 0.1479 Epoch 24 / iter 0, loss = 0.1678 Epoch 24 / iter 1, loss = 0.2080 Epoch 24 / iter 2, loss = 0.1471 Epoch 24 / iter 3, loss = 0.1747 Epoch 24 / iter 4, loss = 0.1607 Epoch 25 / iter 0, loss = 0.1162 Epoch 25 / iter 1, loss = 0.2067 Epoch 25 / iter 2, loss = 0.1692 Epoch 25 / iter 3, loss = 0.1757 Epoch 25 / iter 4, loss = 0.0125 Epoch 26 / iter 0, loss = 0.1707 Epoch 26 / iter 1, loss = 0.1898 Epoch 26 / iter 2, loss = 0.1409 Epoch 26 / iter 3, loss = 0.1501 Epoch 26 / iter 4, loss = 0.1002 Epoch 27 / iter 0, loss = 0.1590 Epoch 27 / iter 1, loss = 0.1801 Epoch 27 / iter 2, loss = 0.1578 Epoch 27 / iter 3, loss = 0.1257 Epoch 27 / iter 4, loss = 0.7750 Epoch 28 / iter 0, loss = 0.1573 Epoch 28 / iter 1, loss = 0.1224 Epoch 28 / iter 2, loss = 0.1353 Epoch 28 / iter 3, loss = 0.1862 Epoch 28 / iter 4, loss = 0.5305 Epoch 29 / iter 0, loss = 0.1981 Epoch 29 / iter 1, loss = 0.1114 Epoch 29 / iter 2, loss = 0.1414 Epoch 29 / iter 3, loss = 0.1856 Epoch 29 / iter 4, loss = 0.0268 Epoch 30 / iter 0, loss = 0.0984 Epoch 30 / iter 1, loss = 0.1528 Epoch 30 / iter 2, loss = 0.1637 Epoch 30 / iter 3, loss = 0.1532 Epoch 30 / iter 4, loss = 0.0846 Epoch 31 / iter 0, loss = 0.1433 Epoch 31 / iter 1, loss = 0.1643 Epoch 31 / iter 2, loss = 0.1202 Epoch 31 / iter 3, loss = 0.1215 Epoch 31 / iter 4, loss = 0.2182 Epoch 32 / iter 0, loss = 0.1567 Epoch 32 / iter 1, loss = 0.1420 Epoch 32 / iter 2, loss = 0.1073 Epoch 32 / iter 3, loss = 0.1496 Epoch 32 / iter 4, loss = 0.0846 Epoch 33 / iter 0, loss = 0.1420 Epoch 33 / iter 1, loss = 0.1369 Epoch 33 / iter 2, loss = 0.0962 Epoch 33 / iter 3, loss = 0.1480 Epoch 33 / iter 4, loss = 0.0687 Epoch 34 / iter 0, loss = 0.1234 Epoch 34 / iter 1, loss = 0.1028 Epoch 34 / iter 2, loss = 0.1407 Epoch 34 / iter 3, loss = 0.1528 Epoch 34 / iter 4, loss = 0.0390 Epoch 35 / iter 0, loss = 0.1113 Epoch 35 / iter 1, loss = 0.1289 Epoch 35 / iter 2, loss = 0.1733 Epoch 35 / iter 3, loss = 0.0892 Epoch 35 / iter 4, loss = 0.0456 Epoch 36 / iter 0, loss = 0.1358 Epoch 36 / iter 1, loss = 0.0782 Epoch 36 / iter 2, loss = 0.1475 Epoch 36 / iter 3, loss = 0.1294 Epoch 36 / iter 4, loss = 0.0442 Epoch 37 / iter 0, loss = 0.1136 Epoch 37 / iter 1, loss = 0.0954 Epoch 37 / iter 2, loss = 0.1542 Epoch 37 / iter 3, loss = 0.1262 Epoch 37 / iter 4, loss = 0.0452 Epoch 38 / iter 0, loss = 0.1277 Epoch 38 / iter 1, loss = 0.1361 Epoch 38 / iter 2, loss = 0.1103 Epoch 38 / iter 3, loss = 0.0920 Epoch 38 / iter 4, loss = 0.4119 Epoch 39 / iter 0, loss = 0.1054 Epoch 39 / iter 1, loss = 0.1165 Epoch 39 / iter 2, loss = 0.1334 Epoch 39 / iter 3, loss = 0.1240 Epoch 39 / iter 4, loss = 0.0672 Epoch 40 / iter 0, loss = 0.1218 Epoch 40 / iter 1, loss = 0.0982 Epoch 40 / iter 2, loss = 0.1077 Epoch 40 / iter 3, loss = 0.1062 Epoch 40 / iter 4, loss = 0.4781 Epoch 41 / iter 0, loss = 0.1541 Epoch 41 / iter 1, loss = 0.1049 Epoch 41 / iter 2, loss = 0.0979 Epoch 41 / iter 3, loss = 0.1042 Epoch 41 / iter 4, loss = 0.0397 Epoch 42 / iter 0, loss = 0.0996 Epoch 42 / iter 1, loss = 0.1031 Epoch 42 / iter 2, loss = 0.1294 Epoch 42 / iter 3, loss = 0.0980 Epoch 42 / iter 4, loss = 0.1135 Epoch 43 / iter 0, loss = 0.1521 Epoch 43 / iter 1, loss = 0.1088 Epoch 43 / iter 2, loss = 0.1089 Epoch 43 / iter 3, loss = 0.0775 Epoch 43 / iter 4, loss = 0.1444 Epoch 44 / iter 0, loss = 0.0827 Epoch 44 / iter 1, loss = 0.0875 Epoch 44 / iter 2, loss = 0.1428 Epoch 44 / iter 3, loss = 0.1002 Epoch 44 / iter 4, loss = 0.0352 Epoch 45 / iter 0, loss = 0.0917 Epoch 45 / iter 1, loss = 0.1193 Epoch 45 / iter 2, loss = 0.0933 Epoch 45 / iter 3, loss = 0.1044 Epoch 45 / iter 4, loss = 0.0064 Epoch 46 / iter 0, loss = 0.1020 Epoch 46 / iter 1, loss = 0.0913 Epoch 46 / iter 2, loss = 0.0882 Epoch 46 / iter 3, loss = 0.1170 Epoch 46 / iter 4, loss = 0.0330 Epoch 47 / iter 0, loss = 0.0696 Epoch 47 / iter 1, loss = 0.0996 Epoch 47 / iter 2, loss = 0.0948 Epoch 47 / iter 3, loss = 0.1109 Epoch 47 / iter 4, loss = 0.5095 Epoch 48 / iter 0, loss = 0.0929 Epoch 48 / iter 1, loss = 0.1220 Epoch 48 / iter 2, loss = 0.1150 Epoch 48 / iter 3, loss = 0.0917 Epoch 48 / iter 4, loss = 0.0968 Epoch 49 / iter 0, loss = 0.0732 Epoch 49 / iter 1, loss = 0.0808 Epoch 49 / iter 2, loss = 0.0896 Epoch 49 / iter 3, loss = 0.1306 Epoch 49 / iter 4, loss = 0.1896

观察上述Loss的变化,随机梯度下降加快了训练过程,但由于每次仅基于少量样本更新参数和计算损失,所以损失下降曲线会出现震荡。
说明:
由于房价预测的数据量过少,所以难以感受到随机梯度下降带来的性能提升。
四、总结
本节我们详细介绍了如何使用Numpy实现梯度下降算法,构建并训练了一个简单的线性模型实现波士顿房价预测,可以总结出,使用神经网络建模房价预测有三个要点:
- 构建网络,初始化参数w和b,定义预测和损失函数的计算方法。
- 随机选择初始点,建立梯度的计算方法和参数更新方式。
- 从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。














 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









