







- B树和B+树的区别
- B树,也即balance树,是一棵多路自平衡的搜索树。它类似普通的平衡二叉树,不同的一点是B树允许每个节点有更多的子节点。
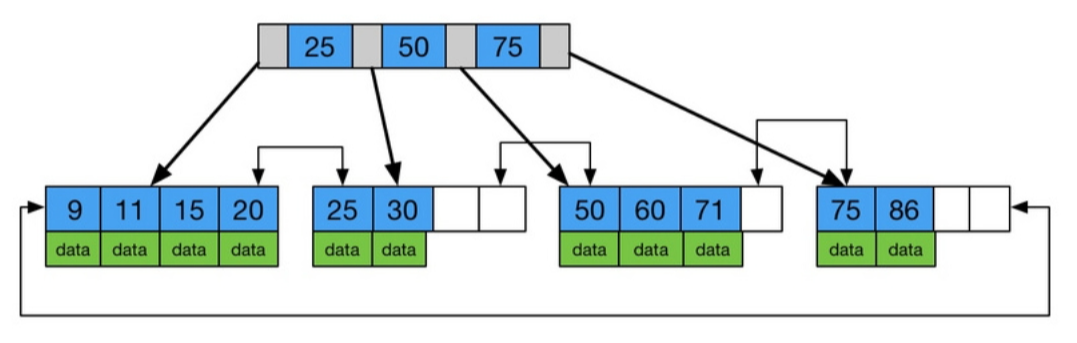
- B+树内节点不存储数据,所有关键字都存储在叶子节点上。
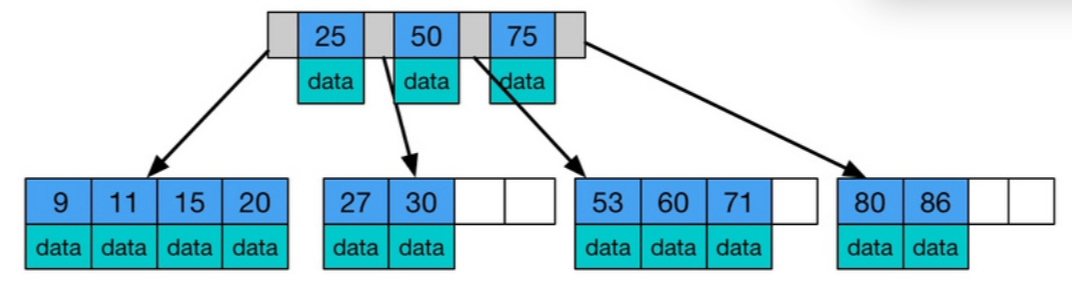
- B树:
B+树:
二叉树理论基础:
1.种类:满二叉树、完全二叉树、二叉搜索树、平衡二叉树。
完全二叉树是最后一行从左到右连续但不一定全满。
二叉搜索树,必须有一定顺序。查询和添加都是O(logn),因为添加就是查询的过程。
平衡二叉搜索树:左右子树高度差的绝对值不超过1。map,set,multimap,multiset底层都是平衡二叉搜索树(是红黑树,红黑树是一种平衡二叉搜索树。)
2.存储方式:链表、数组。
链表,就是val,Treenode* left, Treenode *right
数组,一开始从0开始,左孩子就是2k+1,右孩子就是2k+2
3.遍历方式:
深度优先搜索:前序(中左右)、中序(左中右)、后序(左右中)。一般用递归实现,也可以迭代实现。
广度优先搜索:层序遍历是其中一种。
图的深度优先搜索就对应树的前中后序,图的广度优先搜索就对应树的层序遍历。
1. 二叉树的前,中,后序遍历 - 递归 leetcode144.94.145 20231026
代码随想录又卡了,栈与队列最后那题打着C++已实现的优先队列的旗号实际上是堆,而堆本身又是完全二叉树.....优先队列那题还不是直接拿的priority_queue去实现的,还自定义了它的比较规则,这又引出一个函数对象的概念,总之是无从下手,遂转战二叉树。今天看了看二叉树的理论知识,感觉还行,结果写题的时候又被递归摆了一道,完全忘了return和题干给的函数有什么用。
总之,题干给的preorderTraversal没动,自己重新实现了一个函数,调用之即可。下面两题是类似的。注意在preorder函数中,不能再写一个while循环了,这是写完迭代之后顺手写的错误。
class Solution { public: void preorder(TreeNode* cur, vector<int>& vct) { if(cur == nullptr){ return; } vct.push_back(cur->val); preorder(cur->left,vct); preorder(cur->right,vct); } vector<int> preorderTraversal(TreeNode* root){ vector<int> vct; preorder(root,vct); return vct; } };2. 二叉树的前,中,后序遍历 - 迭代leetcode144.94.145 20231027
迭代分为前后,中两种,理解起来其实还是很困难的,看代码貌似记住了,自己写对了,但是再过几天让我写是绝对写不出来的
前后之所以说是“一种”,因为后序可以由前序倒一下左右,再reverse一下数组就能得到。他们遍历和处理的顺序都是一样的,而中序就不一样了。
下面来看一下具体的代码~
前序,后序在这里就只放前序了:
class Solution { public: vector<int> preorderTraversal(TreeNode* root) { stack<TreeNode*> stk; vector<int> vct; if(root == nullptr) return vct; stk.push(root); while(!stk.empty()){ TreeNode* cur = stk.top(); stk.pop(); vct.push_back(cur->val); if(cur->right !=nullptr) stk.push(cur->right); if(cur->left !=nullptr) stk.push(cur->left); } return vct; } };定义一个stk用于模拟递归,一个vct用户返回数组。因为要先push root进去,所以先得判断一下是否为空。
root被push进去以后,只要栈不为空,就pop栈顶出来,再把刚出的栈顶push到 vct 里面去,然后先往栈里push右边,再往栈里push左边。这样的话,之后vct就会从栈顶开始出,就会先被push_back到vct里面去,而后又是往复的右左栈入,中(栈里元素)左右vct出。
注意,这里push左指针和右指针的时候我都进行了非空判断。后来我又写了一次,忘了加判断,直接往stk里push了空指针,但是用if(cur!=nullptr){}把vct的push_back和两个stk的push括起来了,照样通过,不加则不行。说明可以往栈里面push一个空指针,且stk.top()返回的就是这个空指针。中序
class Solution { public: vector<int> inorderTraversal(TreeNode* root) { vector<int> vct; stack<TreeNode*> stk; TreeNode* cur = root; while(cur != nullptr || !stk.empty()){ if(cur != nullptr){ stk.push(cur); cur = cur->left;//入栈,然后cur一直到最左边 } else{ cur = stk.top();//已经为空了,就取栈头的成为现在的cur stk.pop(); vct.push_back(cur->val); cur = cur->right; } } return vct; } };而迭代法中序遍历的进栈和处理顺序是不一样的,简单来说,我们要从最左下角的节点开始处理,但是进栈肯定是从root进栈。这样就导致我们需要进root->进root的左节点->一直进左节点,这就是while里面第一个if条件的生成,也就是说,只要这个节点不为空,就进栈,然后现节点变成它的左节点,这个现节点是可能为空的,可能就是一个空节点进入下一个while;而else分支则是为空了,要么是空左节点,要么是空右节点,这个时候如果是空左节点,那么就应该处理中和后了。中现在在栈顶,所以用于处理的cur指针指到stack的top,这个时候执行出栈、vct的push_back操作,然后再把用于处理节点的cur指到右节点;如果是空右节点,栈顶实际上是它的父节点的父节点,也应该指到栈顶,继续处理中和后。(此时,完成了一整个循环,右节点此时相当于还没处理,只是cur指到了,下次再进while循环的时候就会重新判断它是否为空,如果非空是否有左节点,如果为空就回到栈top开始处理中和右)
这一段核对了一下逻辑应该没有大的问题,自己也手写了三四遍递归和迭代了。
3.二叉树的层序遍历
队列,queue进第一层,记录size=1,一个一个进一维vct,queue出第一层,进第二层,一维vct进二维result。
class Solution { public: vector<vector<int>> levelOrder(TreeNode* root) { vector<vector<int>> result; if(root == nullptr) return result; queue<TreeNode*> que; que.push(root); while(!que.empty()){ int size = que.size();// 现在是1 vector<int> vct; while(size--){ //一个一个将que里本层的记录到一个vct里面去,然后删掉que里本层的东西,加入下一层的东西 TreeNode* cur = que.front(); vct.push_back(cur->val); que.pop(); if(cur->left != nullptr) que.push(cur->left); if(cur->right != nullptr) que.push(cur->right); } //把这个vct push_back到二维result里去 result.push_back(vct); } return result; } };23/11/11更新:
经过一段时间的学习,我发现树的大多数题就是深度优先(递归、迭代)、广度优先(层序)。而深度优先里面,递归是方便人能理解的,迭代需要我们使用额外的数据结构(比如栈)才能实现,也有可能需要使用队列。广度优先,也就是层序,需要我们使用que实现,有的题也能用栈。
递归,大部分的题就是让我们在另外一个函数A里面把主要思想实现,比如求某个节点的高度,而主函数里面就是调用这个函数A。而我们在函数A里面,需要根据不同情况使用前序、中序、后序遍历,其中求高度需要用后序,求深度需要用前序,而求深度和高度其实也可以相互转化。下面,是我觉得有必要在之前3个代码之后做的题。
第一个是对称二叉树,这一题让我知道可以传2个参数进去递归,很新鲜
4. 对称二叉树
这个一开始以为跟翻转二叉树一样,但是自己也知道应该是两棵树的比较,具体代码还是看了随想录才知道递归应该传两个参进去。
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: bool isSym(TreeNode* left, TreeNode* right) { if(left == nullptr && right != nullptr) return false; else if(left != nullptr && right == nullptr) return false; else if(left==nullptr&& right==nullptr) return true; else if (left->val != right->val) return false; bool r1 = isSym(left->left,right->right); bool r2 = isSym(left->right,right->left); return r1 && r2; } bool isSymmetric(TreeNode* root) { if(root == nullptr) return true; return isSym(root->left, root->right); } };5.二叉树的所有路径
第二个是二叉树的所有路径,这一题的回溯真的很有意思,大家都说这一题不像个简单题,我也觉得(毕竟隐藏在里面的回溯真的很难搞)。
我在没看答案之前写出了一版跟隐藏所有细节后差不多的代码,但是完全不会处理回溯问题,纠结的点在于vector参数和string参数是不是需要引用,哪里需要加->,->是不是要自己手动回退(pop_back),string里加上的节点值是否要手动回退。
后来看了随想录,解决了我的大部分疑问,但是最后一句“每次都是复制赋值,不用使用引用,否则就无法做到回溯的效果。”还是让我有点懵。后来自己又重新思路。
下面是自己最后的思路:- 首先看主函数,traversal传参root,path,result,之后return的result必须得修改过,所以函数traversal里面对应result的那个形参必须是引用类型。实际上,vector也不回溯,所以不纠结。
- 然后看traversal函数。这个函数有2种实现方式,一种是传string做path,一种是传vector做path。如果是传vector做path,又分为传path的引用和不传path的引用。如果是传string做path,又分为传path的引用和不传path的引用,底下再分回溯精简和手动实现回溯。
- 在第二点中,如果我们选择path为vector,并且是引用格式,那么逻辑为:path加入本节点->(中)如果是叶子节点则通过一个for循环把这些path串起来to_string。变成一个最终的string类型往vector里面push_back,然后开始(左)向左执行traversal函数,如果执行完了,path得pop_back对应的值再(右)向右执行traversal函数,如果执行完了,path要pop_back对应的值。这样的话,->是不用考虑的。那pop_back逻辑是否正确呢?假设有一个树如下所示,首先path=[1],然后在这个函数里面向左path=[1,2],然后又去了右分支变成了[1,2,5],然后vector里面加了这么一个[1,2,5]。而执行完毕后path这时是引用返回,所以path依然是[1,2,5],但是返回上一级函数之后path立刻里面被pop_back了,所以又变成了[1,2],再返回上一级,依旧是[1,2],又被pop_back了,变成了1,此时再执行右分枝变成[1,2,3],然后vector加上这个[1,2,3]之后return了,此时真正return,函数结束。
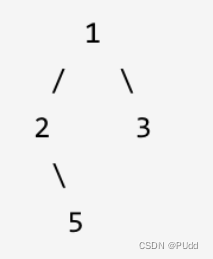
class Solution { private: void traversal(TreeNode* cur, vector<int>& path, vector<string>& result) { path.push_back(cur->val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中 // 这才到了叶子节点 if (cur->left == NULL && cur->right == NULL) { string sPath; for (int i = 0; i < path.size() - 1; i++) { sPath += to_string(path[i]); sPath += "->"; } sPath += to_string(path[path.size() - 1]); result.push_back(sPath); return; } if (cur->left) { // 左 traversal(cur->left, path, result); path.pop_back(); // 回溯 } if (cur->right) { // 右 traversal(cur->right, path, result); path.pop_back(); // 回溯 } } public: vector<string> binaryTreePaths(TreeNode* root) { vector<string> result; vector<int> path; if (root == NULL) return result; traversal(root, path, result); return result; } };如果我们不使用引用,就不用写明面上的回溯了,直接删掉引用,删掉两个pop_back。这是为什么呢?代码随想录讲的是“传值”带来的好处,但是没有具体细说。接下来,继续模拟一下这个过程:
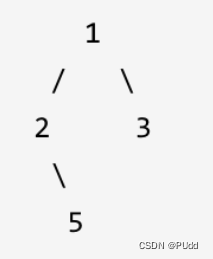
path=[1]
traversal(左,path,result)进入之后,path=[1,2]
进入traversal(右,path, result),进入之后,path=[1,2,5]
开始return。return到的地点是path=[1,2]的函数体的if(cur->right){}里面。关键点在于理解递归返回后 path 的状态:当返回到 if (cur->right) 语句块内部(即在处理右子节点 5 后),此时的 path 就会是 [1, 2]了。因为我们传递的是值而非引用,每次递归调用都是在操作自己的 path 副本,所以在 5 的父节点 2 的层级上,path 保持不变。 一旦退出了这个 if 块 ,就意味着path=[1,2]的递归也走到尽头,接下来回到了第一个节点的right调用部分,path=[1,3]总而言之,因为 path 是按值传递的,所以每个递归层级都有自己的 path 副本,它们彼此独立。这意味着在递归返回时,不需要担心 path 的状态,因为它自然会恢复到适当的状态,这就是为什么不需要 pop_back()。
// 版本二 class Solution { private: void traversal(TreeNode* cur, vector<int> path, vector<string>& result) { path.push_back(cur->val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中 // 这才到了叶子节点 if (cur->left == NULL && cur->right == NULL) { string sPath; for (int i = 0; i < path.size() - 1; i++) { sPath += to_string(path[i]); sPath += "->"; } sPath += to_string(path[path.size() - 1]); result.push_back(sPath); return; } if (cur->left) { // 左 traversal(cur->left, path, result); } if (cur->right) { // 右 traversal(cur->right, path, result); } } public: vector<string> binaryTreePaths(TreeNode* root) { vector<string> result; vector<int> path; if (root == NULL) return result; traversal(root, path, result); return result; } };(混淆:至于全局变量因为局部函数修改而变掉,那是因为从头到尾全局变量的存放只在一个地方,修改都是对一个内存地址的修改)让我们看看以下代码,理清思路
#include <iostream> // 定义全局变量x int x = 10; void modifyGlobalX(int y) { std::cout << "Inside function, before modifying y: " << y << std::endl; // y的初始值 y = 50; // 修改参数y std::cout << "Inside function, after modifying y: " << y << std::endl; // y被修改后的值 std::cout << "Before modifying x: " << x << std::endl; // 修改全局变量x之前 x = 20; // 修改全局变量x std::cout << "After modifying x: " << x << std::endl; // 修改全局变量x之后 } int main() { int y = 30; std::cout << "Initial global x: " << x << std::endl; // 输出全局变量x的初始值 std::cout << "Initial y in main: " << y << std::endl; // 输出主函数中y的初始值 // 调用函数,传递y作为参数 modifyGlobalX(y); // 输出全局变量x和主函数中y的值,看看它们是否被修改 std::cout << "Global x after function call: " << x << std::endl; std::cout << "y in main after function call: " << y << std::endl; return 0; } Result ['Initial global x: 10', 'Initial y in main: 30', 'Inside function, before modifying y: 30', 'Inside function, after modifying y: 50', 'Before modifying x: 10', 'After modifying x: 20', 'Global x after function call: 20', 'y in main after function call: 30']#主要看这里--本题讨论的值传递就是这个亚子!- 在第二点中,如果我们选择path为string
分为传path的引用和不传path的引用——跟上面一样,传引用就要手动pop,但是string类型没法简单的pop一个数字(可能两位数,可能n位数),不传引用就好办,反正还是按值传递,每个递归是每个递归的副本。所以这个地方我们选择不传path的引用。
底下再分回溯精简和手动实现回溯——第一个回溯精简,也就是省略掉了很多东西,也就是我自己刚开始写出来的类似如下的代码。这个代码中,path按值传递所以不需要管,参数是path+"->"所以path更是一点也没变,最终就变成了很简单的样子:
class Solution { private: void traversal(TreeNode* cur, string path, vector<string>& result) { path += to_string(cur->val); // 中 if (cur->left == NULL && cur->right == NULL) { result.push_back(path); return; } if (cur->left) traversal(cur->left, path + "->", result); // 左 if (cur->right) traversal(cur->right, path + "->", result); // 右 } public: vector<string> binaryTreePaths(TreeNode* root) { vector<string> result; string path; if (root == NULL) return result; traversal(root, path, result); return result; } };第二个手动实现回溯,也就是说,把->放出来看看究竟path做了什么变化。
if (cur->left) { path += "->"; traversal(cur->left, path, result); // 左 path.pop_back(); // 回溯 '>' path.pop_back(); // 回溯 '-' }这个时候,path每一层递归都有变化,所以最后返回的时候要想保持原样,当然要把进去之前加上的->给删掉~!因为进一层递归就+一个->,所以出递归自然要减一个!
6.左叶子之和
第三题是404.左叶子之和
这道题我以为自己用的是层序遍历,随想录说其实是迭代——fine。
用迭代法,在写判断“为左节点”的时候犯了难。因为我们无法通过当前节点获取父结点的信息,所以无法知道自己是什么节点。后来经过帮助,直到可以直接在if(node->left)里面进一步判断if(node->left->left&&node->left->right),只要左节点为叶结点,那么在这里就加上左节点的值。
而这一题让我加进来的意义在于这个递归,本来以为遵循传统的后序遍历肯定可以,但是这一题的规则让代码不太好写/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: //再看看深度优先怎么做。 int sumOfLeftLeaves(TreeNode* root) { if(root == nullptr) return 0; //没关系,真正的左节点为空的情况已经在下面被考虑到了 if(!root->left && !root->right) return 0; int leftsum = sumOfLeftLeaves(root->left); //这里考虑到了,值在这里被加上,父节点的时候就已经把下面左叶子节点值加上了 if(root->left && !root->left->left && !root->left->right) leftsum = root->left->val; int rightsum = sumOfLeftLeaves(root->right); int sum = leftsum + rightsum; return sum; } };7.从中序与后序遍历序列构造二叉树
这个题主要困难在于不熟悉题就写不出来第一次递归。其实看过一遍答案之后还是比较好理解的。
首先,主函数是判断为空则返回,不空则进行递归,并且由于这个递归函数是有返回值的,所以直接返回这个递归函数。
然后,考虑递归函数的写法。
递归函数最终返回的一定是一个TreeNode* 类型的根节点,所以我们在其中递归来递归去,其实就是往这个根节点的左右挂靠子树。而子树的诞生需要的依然是这个递归函数,参数依然是两个vector——一个中序vector,一个后序vector。左子树需要两个vector(root->left = traversal(vct1,vct2)),右子树也需要两个vector(root->right = traversal(vct3,vct4)),所以一个递归函数中我们需要产生4个vector,这就需要我们通过后序序列的末尾元素去切割。切割的具体方法很简单,就是去中序里遍历查有没有跟后序末尾元素相等的,有就记录一下位置,然后申请4个vector,分别存中序前部分,中序后部分,后序前部分,后序后部分。
其中细节就是vct.size() ==0、==1时的处理,以及返回值(那肯定是middle)class Solution { public: TreeNode* traversal(vector<int>& inorder, vector<int>& postorder){//&???????????? if(inorder.size() == 0) return nullptr; // 提取后序的最后一个元素 int back_ele_postorder = postorder[postorder.size() - 1]; TreeNode* middle = new TreeNode(back_ele_postorder); if(inorder.size() == 1)// 叶子结点 return middle; // temp 为 中序的根节点的序号 int temp; for (int i = 0; i < inorder.size(); ++i){ if(back_ele_postorder == inorder[i]){ temp = i; break; } } // 找中序进行切割 vector<int> inorder_front(inorder.begin(), inorder.begin() + temp); vector<int> inorder_back(inorder.begin() + temp + 1, inorder.end()); // 找后序进行切割 vector<int> postorder_front(postorder.begin(), postorder.begin() + temp); vector<int> postorder_back(postorder.begin() + temp, postorder.end() - 1); middle -> left = traversal(inorder_front, postorder_front); middle -> right = traversal(inorder_back, postorder_back); return middle; } TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { if(inorder.size() == 0) return nullptr; return traversal(inorder, postorder); } };二叉树部分完结,但是仍然感觉有些地方并不熟练。















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









