






前言:哦豁,又让我学到了

最近,我们可爱的产品同学又提了一个新的需求,想要自己做一个敏感词库,那么问题来了,敏感词检测由后端来实现还是前端来实现呢,经过友善的激烈讨论,决定由前端用DFA算法来实现(又被我学到了)。
一、什么是DFA算法
DFA是一种计算模型,数据源是一个有限个集合,通过当前状态和事件来确定下一个状态,即 状态+事件=下一状态,由此逐步构建一个有向图,其中的节点就是状态,所以在DFA算法中只有查找和判断,没有复杂的计算,从而提高算法效率。
二、实现逻辑
我们要先构造数据结构,把敏感词转换成树结构,比如我们现在有个敏感词库['你好', '你好呀', '好呀'],如下图:
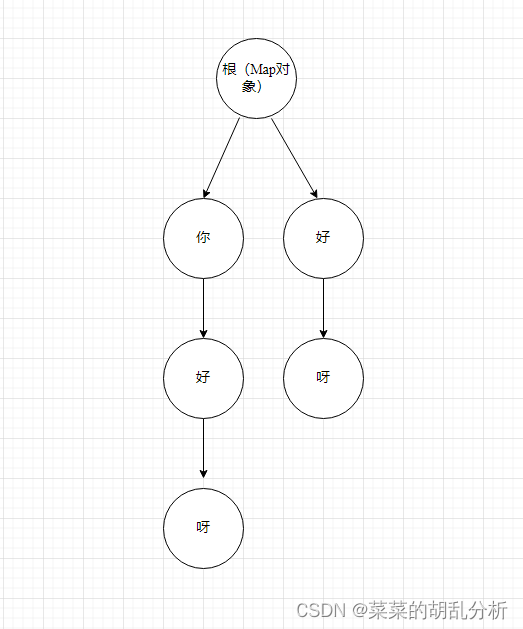
每个文字是一个节点,连续的节点组成一个词,我们可以使用对象或者Map来构建树,这里采用Map构建节点,每个节点中有个状态标识,用来表示当前节点是不是最后一个,每条链路必须要有个终点节点,如下图:
先从文本的第一个字开始检查,比如大家好呀,第一个字大,在树的第一层找不到这个节点,那么继续找第二个字,到了好的时候,第二层节点找到了,那么接着下一层节点中查找呀,同时判断这个节点是不是结尾节点,若是结尾节点,则匹配成功了,反之继续匹配。
同时,这里还有个注意点,如果是这种['你好','你好呀']的特殊情况,这时候'你好'尾节点为false,过滤不了,所以需要在生成Map的时候判断当前的字符,是不是最后一个,若是最后一个就赋值一个标志位。
三、代码实现
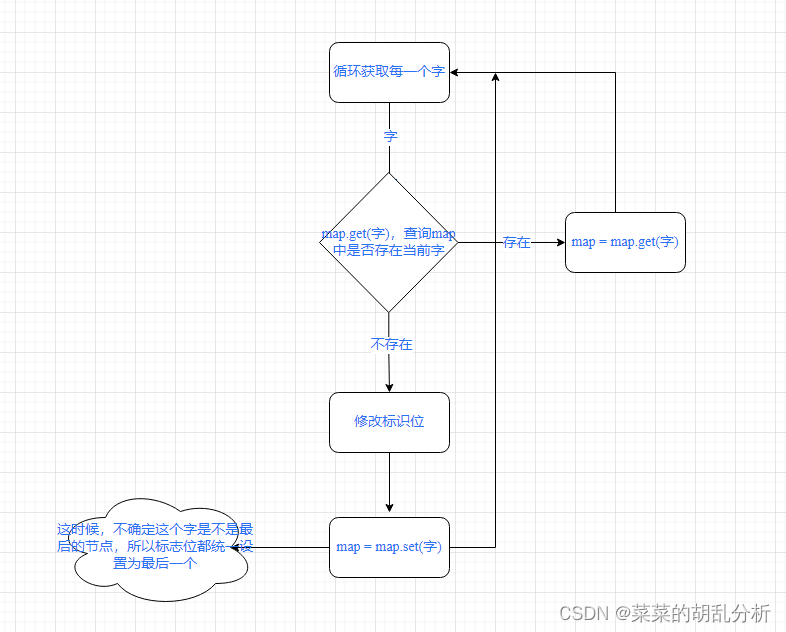
构造敏感词库树,如下图:
makeSensitiveMap(sensitiveWordList) {
// 构造根节点
const result = new Map();
for (const word of sensitiveWordList) {
let map = result;
for (let i = 0; i < word.length; i++) {
// 依次获取字
const char = word.charAt(i);
// 判断是否存在
if (map.get(char)) {
// 获取下一层节点
map = map.get(char);
} else {
// 将当前节点设置为非结尾节点
if (map.get("laster") === true) {
map.set("laster", false);
}
const item = new Map();
// 新增节点默认为结尾节点
item.set("laster", true);
map.set(char, item);
map = map.get(char);
}
// 判断当前的字符,是不是最后一个,若是最后一个就赋值一个标志位
if (word.length === i + 1) {
map.set("lastDigit", true);
}
}
}
return result;
},最终生成的Map结构如下图:

查找敏感词,如下图:
// 检查敏感词是否存在
checkSensitiveWord(sensitiveMap, txt, index) {
let currentMap = sensitiveMap;
let flag = false;
let sensitiveWord = ""; //记录过滤出来的敏感词
for (let i = index; i < txt.length; i++) {
const word = txt.charAt(i);
currentMap = currentMap.get(word);
if (currentMap) {
sensitiveWord += word;
if (currentMap.get("laster") || currentMap.get("lastDigit")) {
// 表示已到词的结尾
flag = true;
break;
}
} else {
break;
}
}
return {
flag,
sensitiveWord
};
},
// 判断文本中是否存在敏感词
filterSensitiveWord(txt, sensitiveMap) {
let matchResult = {
flag: false,
sensitiveWord: ""
};
// 过滤掉除了中文、英文、数字之外的
const txtTrim = txt.replace(
/[^\u4e00-\u9fa5\u0030-\u0039\u0061-\u007a\u0041-\u005a]+/g,
""
);
for (let i = 0; i < txtTrim.length; i++) {
matchResult = this.checkSensitiveWord(sensitiveMap, txtTrim, i);
this.setData({ matchResult });
if (matchResult.flag) {
console.log(`sensitiveWord:${matchResult.sensitiveWord}`);
break;
}
}
return matchResult;
}要是有不对的地方欢迎大家指正,谢谢
需要demo的高手,可以关注公众号回复dnf bye bye


















 4627
4627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









