






<<Pytorch推理及范式>>第二节课作业
必做题
1.从torchvision中加载resnet18模型结构,并载入预训练好的模型权重 ‘resnet18-5c106cde.pth’ (在物料包的weights文件夹中)。
import torch
# 加载模型结构
import torchvision.models as models
model = models.resnet18()
# 读取预训练好的模型权重
pretrained_state_dict = torch.load('./weights/resnet18-5c106cde.pth')
# 将读取的权重载入model
model.load_state_dict(pretrained_state_dict, strict=True)
# 模型放置CPU
model.to(torch.device('cpu'))
# 模型变为推理状态
model.eval()
# 构建项目推理时需要的输入大小的单精度tensor,并放置到模型所在设备
inputs = torch.ones([1, 3, 224, 224]).type(torch.float32).to(torch.device('cpu'))
# 生成onnx
torch.onnx.export(model, inputs, './weights/resnet18.onnx', verbose=False)
2.将(1)中加载好权重的resnet18模型,保存成onnx文件。
resnet18模型的onnx文件大小为44.6MB
3.以torch.rand([1,3,224,224]).type(torch.float32)作为输入,求resnet18的模型计算量和参数量。
Model的参数量和计算量分别为:1.82 GFLOPs and 11.69M Parameters
4.以torch.rand([1,3,448,448]).type(torch.float32)作为输入,求resnet18的模型计算量和参数量。
Model的参数量和计算量分别为: 7.27 GFLOPs and 11.69M Parameters
思考题
1.比较必做题中的(3)和(4)的结果,有什么规律?
模型结构固定时,模型的参数量就固定了,不会随着输入的变化而变化。而计算量与推理过程中的输入有关,输入图片尺寸越大,模型的计算量也更大。
2.尝试用netron可视化resnet18的onnx文件

3.model作为torch.nn.Module的子类,除了用 model.state_dict()查看网络层外,还可以用model.named_parameters()和model.parameters()。它们三儿有啥不同?
(1)model.named_parameters(),迭代打印model.named_parameters()将会打印每一次迭代元素的名字和param
for name, param in model.named_parameters():
print(name,param.requires_grad)
param.requires_grad=False
(2)model.parameters(),迭代打印model.parameters()将会打印每一次迭代元素的param而不会打印名字,这是他和named_parameters的区别,两者都可以用来改变requires_grad的属性
for param in model.parameters():
print(param.requires_grad)
param.requires_grad=False
(3)model.state_dict().items() 每次迭代打印该选项的话,会打印所有的name和param,但是这里的所有的param都是requires_grad=False,没有办法改变requires_grad的属性,所以改变requires_grad的属性只能通过上面的两种方式。
for name, param in model.state_dict().items():
print(name,param.requires_grad=True)
改变了requires_grad之后要修改optimizer的属性
optimizer = optim.SGD(
filter(lambda p: p.requires_grad, model.parameters()), #只更新requires_grad=True的参数
lr=cfg.TRAIN.LR,
momentum=cfg.TRAIN.MOMENTUM,
weight_decay=cfg.TRAIN.WD,
nesterov=cfg.TRAIN.NESTEROV
)
因此,再实际使用时,如果想研究模型的各种参数,可以用model.state_dict(),而如果在做迁移学习时,训练初期可用model.namedParameters()将指定层的require_grad改为False。
4.加载模型权重时用的model.load_state_dict(字典, strict=True),里面的strict参数什么情况下要赋值False?
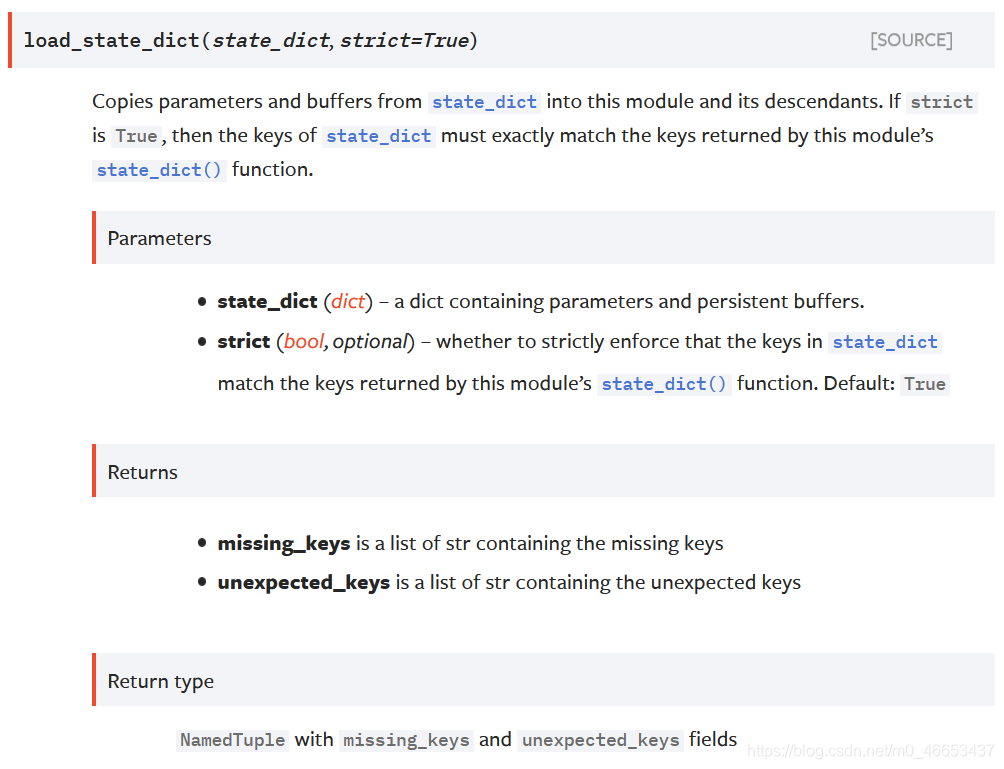
从函数接收的参数state_dict中将参数和缓冲拷贝到当前这个模块及其子模块中. 如果函数接受的参数strict是True,那么state_dict的关键字必须确切地严格地和 该模块的state_dict()函数返回的关键字相匹配。
strict (布尔类型, 可选) – 该参数用来指明是否需要强制严格匹配,在实际迁移学习时,由于任务不同,模型最后的输出也不同,因此,可以将strict设为False,让模型只加载没有改变的Backbone的参数。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









