






一、环境说明:
1、上位机
主机配置:win10(强制要求win 10)OS专业版 22H2
虚拟化软件:VMware pro 17.0.2;
虚拟机系统:Ubuntu20.04.1(要求>=18.0);x86-64位- 5.15.0-87-generic(分配处理器内核数4个,300GB(gparted可扩容) ,装机);
2、板载A:OrangePi 5 Plus 16GB + Micore SD卡 64GB + camera OV13855
系统版本:Orangepi5plus_1.0.6_debian_bookworm_desktop_xfce_linux5.10.110
注:不建议使用Ubuntu的系统镜像Orangepi5_1.1.6_ubuntu_jammy_desktop_gnome_linux5.10.110,网口默认起不来(踩坑了)。
3、板载B:RK_EVB7_RK3588_LP4XD200P232SDB_V11 + EMMC + 自带camera
系统版本:buildroot (镜像见以下编译)
二、OrangePi基本环境搭建
-
使用官方提供的Debian镜像:Orange Pi 5
Plus(16GB)
用的最新系统:
Orangepi5plus_1.0.6_debian_bookworm_desktop_xfce_linux5.10.110 -
下载 win32diskimager-1.0.0 用于烧录系统(准备一个建议大于32GB的TF卡、一个读卡器。)选择以上iso镜像写入SD卡,报写入成功即可:
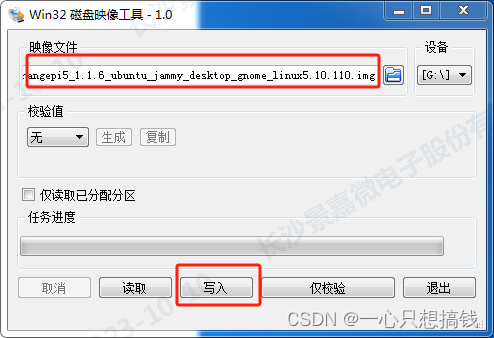
烧录好的SD卡,插到板子上开机就能直接进系统了 -
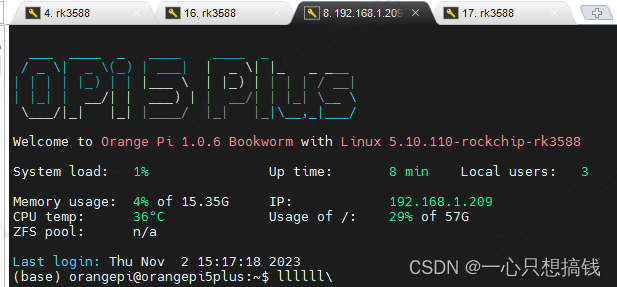
联网+远程连接 :
vi /etc/network/interface 添加静态ip;重启网络服务:systemctl restart NetworkManager.service ;联上网络后安装openssh-server;ssh远程连接:
三、EVB7_RK3588基本环境搭建
参考《Rockchip Linux 软件开发指南》
SDK工程目录介绍
一个通用 Linux SDK ⼯程⽬录包含有 buildroot、debian、app、kernel、u-boot、device、docs、external 等
目录。
app: 存放上层应用 app,主要是 qcamera/qfm/qplayer/settings 等⼀些应⽤程序。
buildroot: 基于 buildroot (2018.02-rc3) 开发的根⽂件系统。
debian: 基于debian 10 开发的根文件系统,支持部分芯片。
device/rockchip: 存放各芯片板级配置和Parameter文件,以及一些编译与打包固件的脚本和预备脚本件。
docs: 存放芯⽚模块开发指导文档、平台支持列表、芯片平台相关文档、Linux开发指南等。
IMAGE: 存放每次生成编译时间、XML、补丁和固件目录。
external: 存放第三方相关仓库,包括音频、视频、网络、recovery 等。
kernel: 存放 kernel 4.4 或 4.19 开发的代码。
prebuilts: 存放交叉编译⼯具链。
rkbin: 存放 Rockchip 相关的 Binary 和工具。
rockdev: 存放编译输出固件。
tools: 存放 Linux 和 Windows 操作系统环境下常用工具。
u-boot:存放基于 v2017.09 版本进行开发的 uboot 代码。
yocto:基于 yocto gatesgarth 3.2 开发的根文件系统,支持部分芯⽚。
- SDK编译
这里以buildroot操作系统为例
(1)依赖包安装
sudo apt-get install repo git ssh make gcc libssl-dev liblz4-tool \
expect g++ patchelf chrpath gawk texinfo chrpath diffstat binfmt-support \
qemu-user-static live-build bison flex fakeroot cmake gcc-multilib g++-multilib
unzip \
device-tree-compiler python-pip ncurses-dev pyelftools \
注:交叉编译工具链路径
64位系统:buildroot/output/rockchip芯⽚型号/host/bin/aarch64-buildroot-linux-gnu-
(2)全自动编译
$ ./build.sh all # 只编译模块代码(u-Boot,kernel,Rootfs,Recovery)
$ export RK_ROOTFS_SYSTEM=buildroot
$./build.sh
默认保存路径~/rk3588_linux_230904/output/RK3588-EVB7-LP4-V10-LINUX/BUILDROOT/日期/
(3) 其他单模块编译
如 qplayer 模块,相关编译命令如下:
$make qplayer
- 烧录
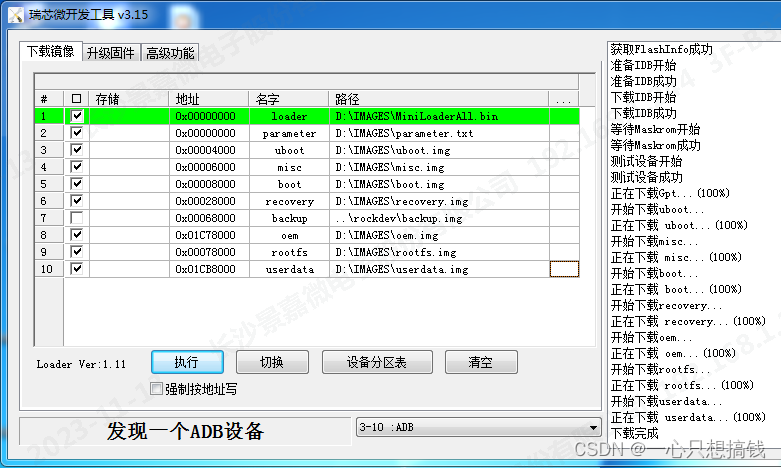
以上保存路径有完整的镜像文件(image),需要烧录至硬件中使用,这里采用windows刷机,SDK 提供 Windows 烧写⼯具(RKDevTool工具版本需要在 V2.84 或以上)
设备烧写需要进入 MASKROM 或 BootROM,前提是烧写模式需要安装 Rockusb 驱动才能正常识别设备,Rockchip USB 驱动安装助手存放在 tools/windows/DriverAssitant_v5.x.zip。支持xp,win7_32,win7_64,win10_32,win10_64 等操作系统。操作见如下:
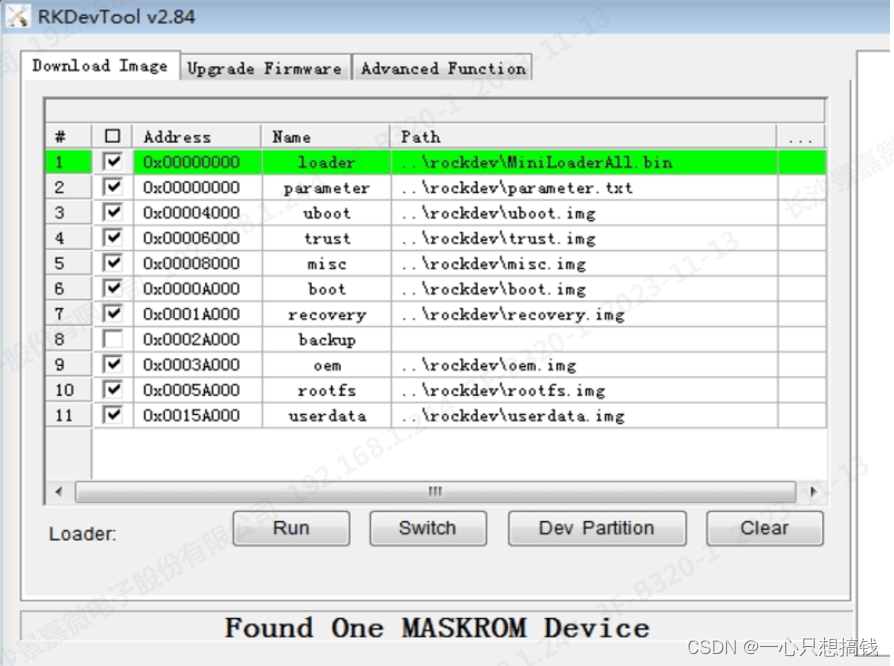
,连接好 USB 下载线(typeC)后,按住按键“MASKROM”不放并按下复位键“RST”后松开,就能进入MASKROM 模式,加载编译生成固件的相应路径后,点击“执行”进行烧写,也可以按 “recovery" 按键不放并按下复位键 “RST” 后松手进入 loader 模式进行烧写,下面是 MASKROM 模式的分区偏移及烧写文件
- 开机
Buildroot默认支持 Wayland 桌环境以及一些 基本的Qt 应用
自测如glmark2、npu、Unixbench等应用,跑分log见如下:
四、训练和模拟测试环境的搭建
1. 安装模块包管理工具(Anaconda)
-
下载 wget https://repo.continuum.io/archive/Anaconda3-2023.09-0-Linux-aarch64.sh
-
安装 bash Anaconda3-2023.09-0-Linux-aarch64.sh #
回车键查看lisence,end后按W键,弹出到 accept lisence terms弹出选择yes;
选择安装路径 /usr/local,选择使用root权限,不然/usr/local下没有新建目录权限:
Anaconda3 will now be installed into this location: /home/codedancing/anaconda3 -
Press ENTER to confirm the location
-
Press CTRL-C to abort the installation
-
Or specify a different location below
-
[/home/codedancing/anaconda3]>>>/home/rk3588/anaconda3
You can undo this by runningconda init --reverse $SHELL? [yes|no]
[no] >>> yes
#选择将conda加入shell环境 -
export PATH=/home/rk3588/anaconda3/bin:$PATH
-
source .bashrc #加环境变量, 用户目录下
-
conda --version #验证功能
-注:添加国内的镜像源,更改镜像源文件.condarc(去掉default)后使用起来会比较快
2. 虚拟环境conda
-
conda create -n rkyolov5 python=3.8 #创建虚拟环境,命名为rkyolov5,将下载相关依赖包
注:按照RK3588版本要求使用rknn-toolkit2(rknn-toolkit 旧版不用);Currently only support on Ubuntu 18.04 python 3.6 / Ubuntu 20.04 python 3.8 / Ubuntu 22.04 python 3.10;
-
source activate yolov5_env #激活使用虚拟环境rkyolov5
-
conda config --remove-key channels #删除镜像源
-
conda install pytorch torchvision torchaudio cpuonly -c pytorch #conda安装相关依赖,如pytorch等
-
conda deactivate #退出虚拟环境
3. 下载yolov5
-
https://github.com/ultralytics/yolov5/tree/c5360f6e7009eb4d05f14d1cc9dae0963e949213
(v5.0版本) -
https://github.com/ultralytics/yolov5/tree/v6.0
(V6.0版本,当然v4.0也试过可以的,建议使用V6.0) -
pip3 install -r requirements.txt -i https://mirror.baidu.com/pypi/simple #yolov5的根目录下,使用pip安装一下环境依赖包。
注:建议使用国内百度云的源,rknn if install failed, please change the pip source to ‘https://mirror.baidu.com/pypi/simple’;
4. 标注数据集
- 下载标记软件 labelImg:https://github.com/tzutalin/labelImg #下载后存放目录到yolov5同级下面
- labellmg->data->predefined_classes.txt #文档中可以添加要标准的类别
- pip3 install PyQt5 PyQt5_tools、lxml #按照依赖
- 使用
step 1: 运行pyrcc5 -o resources.py resources.qrc
step 2. 将生成的resources.py拷贝到同级的libs目录下 - 运行: python3 labelImg.py
注:数据集简单来说图像集(.png .jpg)等图片,标注后是图像数据集(.xml)形式labelimg的标注模式分为VOC和YOLO两种,两种模式下生成的标注文件分别为.xml文件和.txt文件,因此在进行标注前需要优先选择好标注的模式。
- 标注得到yolo的TXT文件,例子:
58 0.389578 0.416103 0.038594 0.163146
62 0.127641 0.505153 0.233312 0.222700
注:第一列为目标类别,后面四个数字为[x_center, y_center, w, h],可以看到都是小于1的数字,是因为对应的整张图片的比例,所以就算图像被拉伸放缩,这种txt格式的标签也可以找到相应的目标。
5. 标准的数据集
为了加快进度,采用coco官方提供的数据集文件,说明见如下:
- /coco128/images,存放数据集图片
- /coco128/labels,存放数据集标注信息。
- coco.yaml和coco128.yaml文件,网络上提供的数据集文件,我们在训练自己的数据集的时候,需要借用他的文件修改相应的参数。
- train.py和test.py文件是用于训练网络的,先调试train.py文件中的参数对网络进行训练,然后用detect.py文件,加载训练好的权重,设置需要检测的图像数据运行即可完成测试。
6. 训练自己的数据集
-
训练数据集: python3 train.py --img 640 --batch 1 --epochs 1 --data ./data/coco128.yaml --cfg ./models/yolov5s.yaml --weights ./yolov5s.pt
注“–cfg ./models/yolov5s.yaml --weights ./yolov5s.pt” #表示过传递匹配的权重文件从预训练的检查点进行训练,避免从0开始训练 -
部分训练完成后的打印可见如下:
YOLOv5s summary: 214 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs
Transferred 229/349 items from yolov5s.pt
Results saved to runs/train/exp6
#注 :runs/train/exp6 文件夹中best.pt是训练几百轮后所得到的最好的权重,last.pt是最后一轮训练所得到的权重; -
采用best.pt重复步骤7检测一下
结果: 出现不能检测到人脸的问题,出现了欠拟合的情况:由于机器学习到的特征太少(见以上参数,共128张,仅迭代数据集1次),导致区分标准太粗糙,不能准确识别。导致模型发生了欠拟合。所以还是要调整好训练的迭代轮次和数据集;
注1参数配置说明:从训练脚本train.py中parse_opt()可知常用的传参:
–epochs:训练过程中整个数据集将被迭代的次数
–batch-size:-1为自动,一次看完多少张图片才进行权重更新,梯度下降的mini-batch
–cfg:存储模型结构的配置文件
–data:存储训练、测试数据的文件
–imgsz:输入图片宽高
–weights:权重文件路径,如yolov5s.pt
–name: 重命名save to project/name
–device:选择cuda device
注2:当batch和epochs过高时,训练会自动kill,dmesg报错信息:Out of memory: Killed process,一方原因是虚拟机没有分配GPU资源,只用cpu跑,一方面可能计算量过大超过gpu cuda的内存大小;
7. 目标检测测试
- yolov5的pt权重的官方下载地址: https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt
- 加载并测试 训练好的或直接使用官方的权重: python3 detect.py --source inference/images/ --weights ./yolov5s.pt
- 结果见如下,正常识别出了people & tie:

常用参数说明:
–weights # 选用训练的权重
–source # 检测数据,可以是图片/视频路径,也可以是’0’(电脑自带摄像头),也可以是rtsp等视频流
–imgsz #指定推理图片分辨率,默认640
–half # 半精度检测(FP16)
五、模型转换
目标是: 将yolov5训练得到的pt模型或直接从官方down的pt模型,转换为rknn模型,并将rknn模型部署在搭载RK3588的板子上,用于NPU的推理,基本步骤见:
- 通过yolov5原有权重加数据集后进行训练得到理想的pt模型;
- pt模型经过yolov5工程中的export.py脚本转换为onnx模型;
- 再将onnx模型使用rknn-toolkit2工具转换为rknn模型;
- 在板子上使用rknpu2工具调用rknn模型,实现NPU推理加速。
1、转换模型
介绍:是为用户提供在 PC、Rockchip NPU 平台上进行模型转换、推理和性能评估的开发套件,用户通过该工具提供的 Python 接口可以便捷地完成各种操作。RKNN-Toolkit2 目前版本只适用系统Ubuntu18.04(x64)及以上,
(1)安装 RKNN-Toolkit2:
- 下载:https://github.com/rockchip-linux/rknn-toolkit2
#readme中有指出使用自带docker环境的rknn-toolkit包,但我们这边使用conda自己创建的环境运行,注:采用的是release版本工具:rknn-toolkit2-1.5.2 - 同上创建虚拟环境:conda create -n rkyolov5 python=3.8 #要求3.8版本,也可以用以上创建的虚拟环境,不用重复操作
- 安装相关依赖:~/rknn-toolkit2-1.5.2/doc$ pip3 install -r
requirements_cp38-1.5.2.txt -i https://mirror.baidu.com/pypi/simple - 安装工具包:pip3 install rknn_toolkit2-1.5.2+b642f30c-cp38-cp38-linux_x86_64.whl -i https://mirror.baidu.com/pypi/simple
#这里看起来是半开源的,脚本这些还需要通过whl来装,down下来的rknn_toolkit2-1.5.2确实有源码 - 检测是否安装成功,导入相关包即可python3 -> from rknn.api import RKNN
- 采用example里面的用例集成验证一下环境:
~/rknn-toolkit2-1.5.2/examples/onnx/yolov5$ python3 test.py
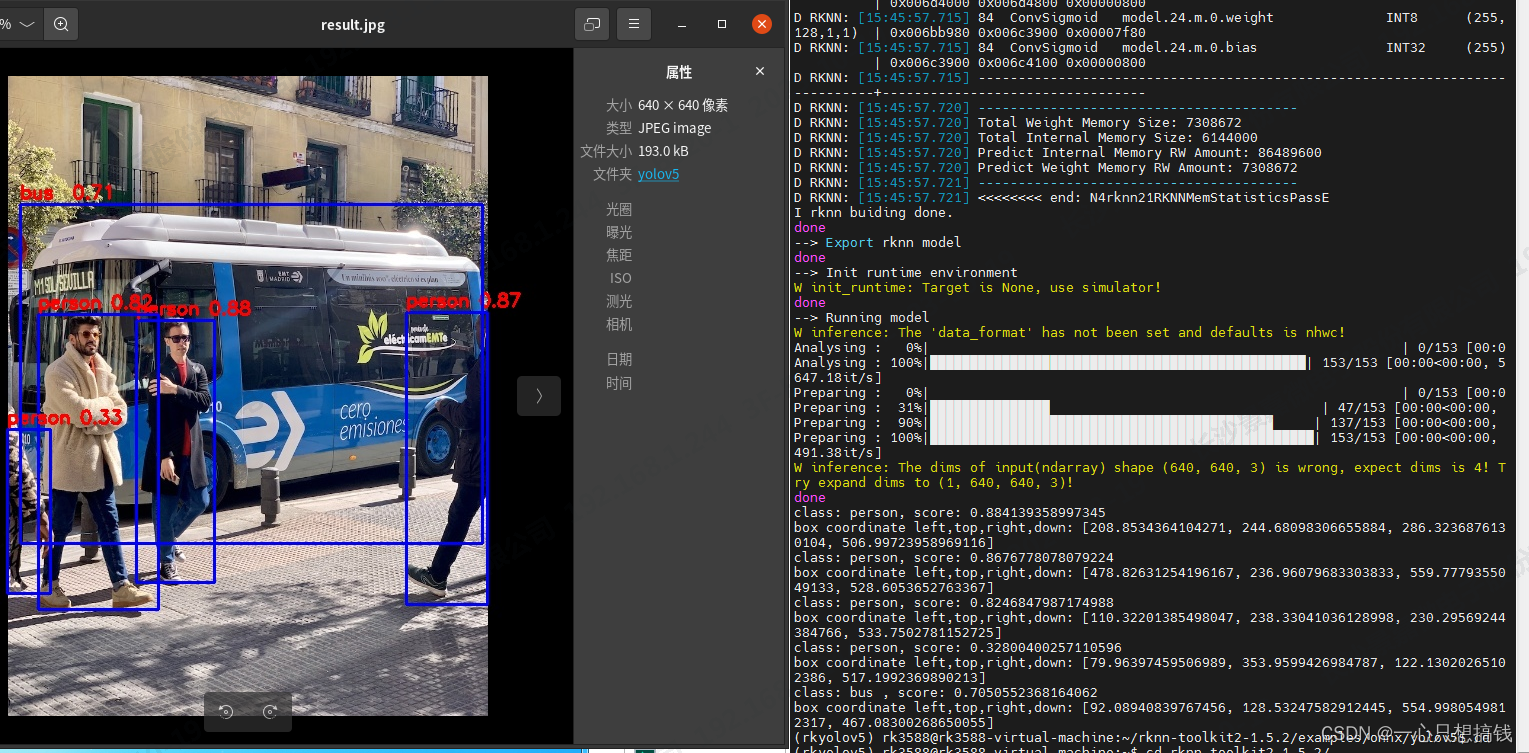
注:区分RKNN Toolkit Lite2文件是提供于板卡端使用的模型转换软件,rknn-toolkit2-1.5.2是在模拟环境下使用验证;
(2)把yolov5s.pt转换为yolov5s.onnx
- 先安装包:~/yolov5-v5$ pip3 install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
#target可指定安装至虚拟环境,不然默认的环境优先级较高 - 转换:
转换前需修改models/yolo.py,修改Detect类中的forward函数,转换时需要修改如下部分,注意在训练时和Detect验证检测时需要改回原状态,否则容易出现过拟合的问题。
# def forward(self, x):
# z = [] # inference output
# for i in range(self.nl):
# x[i] = self.m[i](x[i]) # conv
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
#
# if not self.training: # inference
# if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
# self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
#
# y = x[i].sigmoid()
# if self.inplace:
# y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
# xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
# y = torch.cat((xy, wh, y[..., 4:]), -1)
# z.append(y.view(bs, -1, self.no))
#
# return x if self.training else (torch.cat(z, 1), x)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x
~/yolov5-v5$ python export.py --weights yolov5s.pt --img 640 --batch 1 --include onnx --opset 11
#会对应生成的yolov5s.onnx文件 ,opset是onnx的版本
(3)将onnx转换为rknn文件
修改examples/onnx/myolov5/test.py文件
- onnx路径、rknn保存路径、img测试图片路径、类别数等
~/rknn-toolkit2-1.5.2/examples/onnx/yolov5_test$ python3 test.py #官方rknn工具执行检测测试
出现检测异常:

注:
该问题出现的情况1是 onnx转换后未更改回yolo的detect函数,直接detect会出现的异常
识别到过多的目标框+score不在0-1范围内,置信度超过1,
提高置信度阈值,加NMS?
(4)按rk已有模型进行推理
参考https://github.com/airockchip/rknn_model_zoo ,大致步骤见如下:
步骤1. 获取模型
使用 airockchip 组织下的 yolov5/yolov6 /yolov7/ yolov8/ YOLOX / 仓库,根据仓库里的 README_rkopt_manual.md 提示,进行模型训练、模型导出。获取 torchscript / onnx 格式的模型。(ppyoloe 等待整理补充)
对于获取 ONNX 格式 的 ppyoloe 模型,请参考文档
或下载已经提供的RKNN模型,获取 网盘https://eyun.baidu.com/enterprise/share/link?cid=8272257679089781337&uk=2751701137&sid=202211118572878233#sharelink/path=%2F(密码:rknn) ,
链接中的具体位置为rknn_model_zoo/models/CV/object_detection/yolo/{YOLO}/deploy_models/{toolkit}/{platform}
步骤2. 模型转换
参考 RKNN_model_convert 说明,将步骤1获取的 torchscript / onnx 格式的模型转为 RKNN 模型。
在连板调试功能可以正常使用的情况下,转换脚本除了转出模型,会调用 rknn.eval_perf 接口获取 RKNN 模型推理性能、计算 RKNN 模型与原模型的推理结果相似度(基于cos距离)。
步骤3. 使用 Python demo 测试 RKNN/ torchscript/ onnx模型
参考 RKNN_python_demo 说明,测试 RKNN/ torchscript/ onnx 格式的 yolo 模型在图片上推理结果并绘图。
RK1808/ RV1109/ RV1126/RK3399pro 请使用 RKNN_toolkit_1 版本
RK3562/ RK3566/ RK3568/ RK3588/ RK3562/ RV1103/ RV1106 请使用 RKNN_toolkit_2 版本
六、推理检测
1. orangepi 板端进行图片推理检测
:~/rknpu2_1.5.2_20230825/examples/rknn_yolov5_demo/install/rknn_yolov5_demo_Linux$ ./rknn_yolov5_demo ./yolov5s_relu.rknn ./model/mans.jpeg

img width = 1440, img height = 1080
once run use 38.829000 ms
loop count = 10 , average run 21.729600 ms
2. orangepi 板端进行视频推理检测
-
先转换视频格式为H264或H265:
(yolov5)orangepi@orangepi5plus:~/rknpu2_1.5.2_20230825/examples/rknn_yolov5_demo/install/rknn_yolov5_demo_Linux$ ffmpeg -i lightweghtbaby.mp4 -vcodec h264 lightweghtbaby.h264
或
ffmpeg -i bridge_1280.mp4 -codec copy -bsf: h264_mp4toannexb -f h264 bridge_1280.h264 -
运行检测
(yolov5)orangepi@orangepi5plus:~/rknpu2_1.5.2_20230825/examples/rknn_yolov5_demo/install/rknn_yolov5_demo_Linux$ ./rknn_yolov5_video_demo ./model/RK3588/yolov5s-640-640.rknn ./lightweghtbaby.h264 264
默认float16的。
视频格式:1920x1080
once run use 18.748000 ms
七、未解决报错
- 转换模型报错:
E inference: The input(ndarray) shape (1, 320, 320, 3) is wrong, expect ‘nhwc’ like (1, 640, 640, 3)!
W inference: ===================== WARN(8) =====================
E rknn-toolkit2 version: 1.5.2+b642f30c
Traceback (most recent call last):
File “test.py”, line 289, in
outputs = rknn.inference(inputs=[img])
File “/home/rk3588/anaconda3/envs/rkyolov5/lib/python3.8/site-packages/rknn/api/rknn.py”, line 305, in inference
return self.rknn_base.inference(inputs=inputs, data_format=data_format,
File “rknn/api/rknn_base.py”, line 2598, in rknn.api.rknn_base.RKNNBase.inference
File “rknn/api/simulator.py”, line 545, in rknn.api.simulator.Simulator.inference
File “rknn/api/simulator.py”, line 507, in rknn.api.simulator.Simulator._get_inputs
File “rknn/api/rknn_utils.py”, line 254, in rknn.api.rknn_utils.get_input_img
File “rknn/api/rknn_log.py”, line 112, in rknn.api.rknn_log.RKNNLog.e
ValueError: The input(ndarray) shape (1, 320, 320, 3) is wrong, expect ‘nhwc’ like (1, 640, 640, 3)!
def inference(self, inputs, data_format=None, inputs_pass_through=None, get_frame_id=False):
“”"
Run model inference
:param inputs: Input ndarray List.
:param data_format: Data format list, current support: ‘nhwc’, ‘nchw’, default is ‘nhwc’, only valid for 4-dims input. default is None.
:param inputs_pass_through: The pass_through flag (0 or 1: 0 meas False, 1 means True) list. default is None.
:param get_frame_id: Whether need get output/input frame id when using async mode,it can be use in camera demo. default is False.
:return: Output ndarray list
“”"
return self.rknn_base.inference(inputs=inputs, data_format=data_format,
inputs_pass_through=inputs_pass_through, get_frame_id=get_frame_id)
packages in environment at /home/orangepi/anaconda3/envs/yolov5:
Name Version Build Channel
_libgcc_mutex 0.1 main https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
_openmp_mutex 5.1 51_gnu https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
aiocache 0.12.2 pypi_0 pypi
aiocqhttp 1.4.4 pypi_0 pypi
aiofiles 23.2.1 pypi_0 pypi
anyio 4.0.0 pypi_0 pypi
blinker 1.6.3 pypi_0 pypi
botlib 0.0.0 pypi_0 pypi
ca-certificates 2023.08.22 hd43f75c_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
certifi 2023.7.22 pypi_0 pypi
click 8.1.7 pypi_0 pypi
cmake 3.27.7 pypi_0 pypi
eog 1 pypi_0 pypi
exceptiongroup 1.1.3 pypi_0 pypi
flask 3.0.0 pypi_0 pypi
flatbuffers 23.5.26 pypi_0 pypi
h11 0.14.0 pypi_0 pypi
h2 4.1.0 pypi_0 pypi
hpack 4.0.0 pypi_0 pypi
httpcore 0.18.0 pypi_0 pypi
httpx 0.25.0 pypi_0 pypi
hypercorn 0.14.4 pypi_0 pypi
hyperframe 6.0.1 pypi_0 pypi
idna 3.4 pypi_0 pypi
importlib-metadata 6.8.0 pypi_0 pypi
itsdangerous 2.1.2 pypi_0 pypi
jinja2 3.1.2 pypi_0 pypi
keras 2.13.1 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
libclang 16.0.6 pypi_0 pypi
libffi 3.4.4 h419075a_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
libgcc-ng 11.2.0 h1234567_1 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
libgomp 11.2.0 h1234567_1 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
libstdcxx-ng 11.2.0 h1234567_1 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
markupsafe 2.1.3 pypi_0 pypi
ncurses 6.4 h419075a_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
nonebot 1.9.1 pypi_0 pypi
numpy 1.24.3 pypi_0 pypi
oauthlib 3.2.2 pypi_0 pypi
opencv-python 4.8.1.78 pypi_0 pypi
openssl 3.0.11 h2f4d8fa_2 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
packaging 23.2 pypi_0 pypi
pip 23.3 py38hd43f75c_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
priority 2.0.0 pypi_0 pypi
protobuf 4.24.4 pypi_0 pypi
pyasn1 0.5.0 pypi_0 pypi
python 3.8.18 h4bb2201_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
quart 0.19.3 pypi_0 pypi
readline 8.2 h998d150_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
setuptools 68.0.0 py38hd43f75c_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
six 1.16.0 pypi_0 pypi
sniffio 1.3.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
tensorboard-data-server 0.7.2 pypi_0 pypi
tensorflow-estimator 2.13.0 pypi_0 pypi
tensorflow-io-gcs-filesystem 0.34.0 pypi_0 pypi
termcolor 2.3.0 pypi_0 pypi
tk 8.6.12 h241ca14_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
tomli 2.0.1 pypi_0 pypi
typing-extensions 4.5.0 pypi_0 pypi
urllib3 2.0.7 pypi_0 pypi
werkzeug 3.0.0 pypi_0 pypi
wheel 0.41.2 py38hd43f75c_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
wrapt 1.15.0 pypi_0 pypi
wsproto 1.2.0 pypi_0 pypi
xz 5.4.2 h998d150_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
zipp 3.17.0 pypi_0 pypi
zlib 1.2.13 h998d150_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
(yolov5) orangepi@orangepi5plus:~/anaconda3/envs$ pip list
Package Version
absl-py 2.0.0
aiocache 0.12.2
aiocqhttp 1.4.4
aiofiles 23.2.1
anyio 4.0.0
astunparse 1.6.3
blinker 1.6.3
botlib 0.0.0
cachetools 5.3.1
certifi 2023.7.22
charset-normalizer 3.3.1
click 8.1.7
cmake 3.27.7
eog 1
exceptiongroup 1.1.3
Flask 3.0.0
flatbuffers 23.5.26
gast 0.4.0
google-auth 2.23.3
google-auth-oauthlib 1.0.0
google-pasta 0.2.0
grpcio 1.59.0
h11 0.14.0
h2 4.1.0
h5py 3.10.0
hpack 4.0.0
httpcore 0.18.0
httpx 0.25.0
hypercorn 0.14.4
hyperframe 6.0.1
idna 3.4
importlib-metadata 6.8.0
itsdangerous 2.1.2
Jinja2 3.1.2
keras 2.13.1
libclang 16.0.6
markdown 3.5
MarkupSafe 2.1.3
nonebot 1.9.1
numpy 1.24.3
oauthlib 3.2.2
opencv-python 4.8.1.78
opt-einsum 3.3.0
packaging 23.2
pip 23.3
priority 2.0.0
protobuf 4.24.4
pyasn1 0.5.0
pyasn1-modules 0.3.0
Quart 0.19.3
requests 2.31.0
requests-oauthlib 1.3.1
rsa 4.9
setuptools 68.0.0
six 1.16.0
sniffio 1.3.0
tensorboard 2.13.0
tensorboard-data-server 0.7.2
tensorflow 2.13.1
tensorflow-cpu-aws 2.13.1
tensorflow-estimator 2.13.0
tensorflow-io-gcs-filesystem 0.34.0
termcolor 2.3.0
tomli 2.0.1
typing_extensions 4.5.0
urllib3 2.0.7
Werkzeug 3.0.0
wheel 0.41.2
wrapt 1.15.0
wsproto 1.2.0
zipp 3.17.0














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









