







在之前的文章 [kubeflow] 从零搭建training-operator项目 中,我们从零搭建了一个简单的training-operator项目,最终就差完成controller的Reconcile函数逻辑。
在上一篇文章 [kubeflow] controller-runtime源码解析 中,我们探究了controller-runtime的运行原理,理解了执行Reconcile函数之前的逻辑是啥样的。
这次从TFJob的Reconcile函数为入口,探究training-operator到底是怎么工作的。
TFJobReconciler
代码架构
现在是2023/8/18,kubeflow/common已经被merge到了training-operator主分支,更有利于源码阅读。我所使用的master分支的版本是855e09。
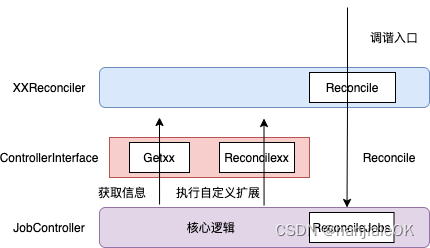
不得不说,第一次看training-operator源码,很头大,文件太多了…哪怕顺着TFJob的Reconcile函数来看,里面的函数调用也是错综复杂。TFJobReconciler,JobController,ControllerInterface这几个结构体怎么你中有我,我中有你,着实把我看蒙了。直到看到这篇文章 tf-operator源码分析,其中的一段话和一张图让我沉思了很久
JobController 类似模板类,实现了核心逻辑,又要留有足够的扩展性
- TFJobReconciler 聚合了 JobController,这样可以使用 JobController.ReconcileJobs 触发Reconcile 核心逻辑
- TFJobReconciler 又实现了ControllerInterface ,JobController 通过 ControllerInterface 实现聚合TFJobReconciler 的效果, 可以调用Get 方法获取信息,也可以调用ReconcileXX 方法执行上层自定义扩展逻辑。
文字和图片均来自 tf-operator源码分析
在那个晚上,这段话和图片我反反复复读了很久,感觉懂了,又感觉没懂。似懂非懂,还差临门一脚。最终我决定简化逻辑,动手运行一下这个“你中有我,我中有你”的代码结构。
有两个基础的go知识点:
- 在go语言中,interface是抽象接口,只定义方法但没有具体实现。如果一个结构体实现了某个interface定义的所有方法,那么我们就说这个结构体是这个interface的具体实现。
- go结构体中可以使用匿名成员,只需指定类型,无需指定名称。该结构体就可以拥有该匿名成员的所有方法。
TFReconciler 的定义和初始化在 pkg/controller.v1/tensorflow/tfjob_controller.go
ControllerInterface 的定义在 pkg/common/interface.go
JobController 的定义和初始化在 pkg/controller.v1/common/job_controller.go
下面这面这段代码就是由TFReconciler,ControllerInterface,JobController三者的关系简化而来。ControllerInterface是抽象接口,定义了4个函数。JobController这个结构体实现了其中两个函数ReconileJobs()和ReconilePods(),TFJobReconiler实现了GetUID()和GetAPI()两个函数。TFJobReconiler结构体中有匿名成员JobController,因此TFJobReconiler拥有JobController实现的两个函数,相当于TFJobReconiler实现了ReconileJobs()和ReconilePods()这两个函数。至此,TFJobReconiler实现了ControllerInterface定义的所有函数,故TFJobReconiler是ControllerInterface。而JobController里的成员Controller恰恰是ControllerInterface类型,因此在main函数中使用TFJobReconiler来初始化JobController。看起来就是“你中有我,我中有你”。
运行这段程序,TFJobReconiler.Reconile()实际调用JobController.ReconileJobs()
jc.Controller.GetAPI()实际调用TFJobReconiler.GetAPI()
jc.Controller.GetUID()实际调用TFJobReconiler.GetUID()
jc.Controller.ReconilePods()实际调用JobController.ReconilePods()
打印结果如下
ReconileJobs...
GetAPI...
GetUID...
ReconilePods... [JobController]
如果把注释部分的代码恢复,即TFJobReconiler本身实现了ReconilePods(),那么jc.Controller.ReconilePods()就会调用TFJobReconiler.ReconilePods()而非JobController.ReconilePods(),相当于被覆盖掉了(有点像C++里面的多态)。
现在是不是可以理解上面那张图了🥹
package main
import "fmt"
type ControllerInterface interface {
ReconileJobs()
ReconilePods()
GetUID()
GetAPI()
}
type JobController struct {
Controller ControllerInterface
}
func (jc *JobController) ReconileJobs() {
fmt.Println("ReconileJobs...")
jc.Controller.GetAPI()
jc.Controller.GetUID()
jc.Controller.ReconilePods()
}
func (jc *JobController) ReconilePods() {
fmt.Println("ReconilePods... [JobController]")
}
type TFJobReconiler struct {
JobController
}
func (r *TFJobReconiler) GetUID() {
fmt.Println("GetUID...")
}
func (r *TFJobReconiler) GetAPI() {
fmt.Println("GetAPI...")
}
// This func will override JobController.ReconilePods()
// func (r *TFJobReconiler) ReconilePods() {
// fmt.Println("ReconilePods... [TFJobReconiler]")
// }
func (r *TFJobReconiler) Reconile() {
r.ReconileJobs()
}
func main() {
r := &TFJobReconiler{}
r.JobController = JobController{
Controller: r,
}
r.Reconile()
}
搞懂了上面的,我们再正式开始看代码。
前置知识
介绍完controller-runtime以后,我们要明白一件事,training-operator中Reconciler的实现逻辑很大程度上是在模仿K8s源码中的controller,也就是说,training-operator中Reconciler里面的很多机制都是来自于k8s源码。
第一个要说的是expectation。expecatation最初是replicaset controller中的机制。这部分我参考了 k8s replicaset controller源码分析(3)-expectations 机制分析 这篇文章。
expectation的代码在 pkg/controller.v1/expectation/expectation.go。expectation记录了TFJob对象在某一次调谐中期望创建/删除的pod/service数量。
- pod/service创建/删除完成后,会调用CreationObserved/DeletionObserved,进而调用LowerExpectations,该期望数会相应的减少。
- pod/service期望创建/删除时,会调用ExpectCreations/ExpectDeletions,进而调用RaiseExpectations,该期望数会相应的增加。
当期望创建/删除的pod/service数量小于等于0时,说明上一次调谐中期望创建/删除的pod/service数量已经达到,这种情况下,expectations.SatisfiedExpectations会返回true。如果期望被满足并且TFJob对象的deleteTimestamp为空,才会调用ReconcileJobs继续进行调谐操作,也即pod/service的创建/删除操作。
// ControllerExpectationsInterface is an interface that allows users to set and wait on expectations.
// Only abstracted out for testing.
// Warning: if using KeyFunc it is not safe to use a single ControllerExpectationsInterface with different
// types of controllers, because the keys might conflict across types.
type ControllerExpectationsInterface interface {
GetExpectations(controllerKey string) (*ControlleeExpectations, bool, error)
SatisfiedExpectations(controllerKey string) bool
DeleteExpectations(controllerKey string)
SetExpectations(controllerKey string, add, del int) error
ExpectCreations(controllerKey string, adds int) error
ExpectDeletions(controllerKey string, dels int) error
CreationObserved(controllerKey string)
DeletionObserved(controllerKey string)
RaiseExpectations(controllerKey string, add, del int)
LowerExpectations(controllerKey string, add, del int)
}
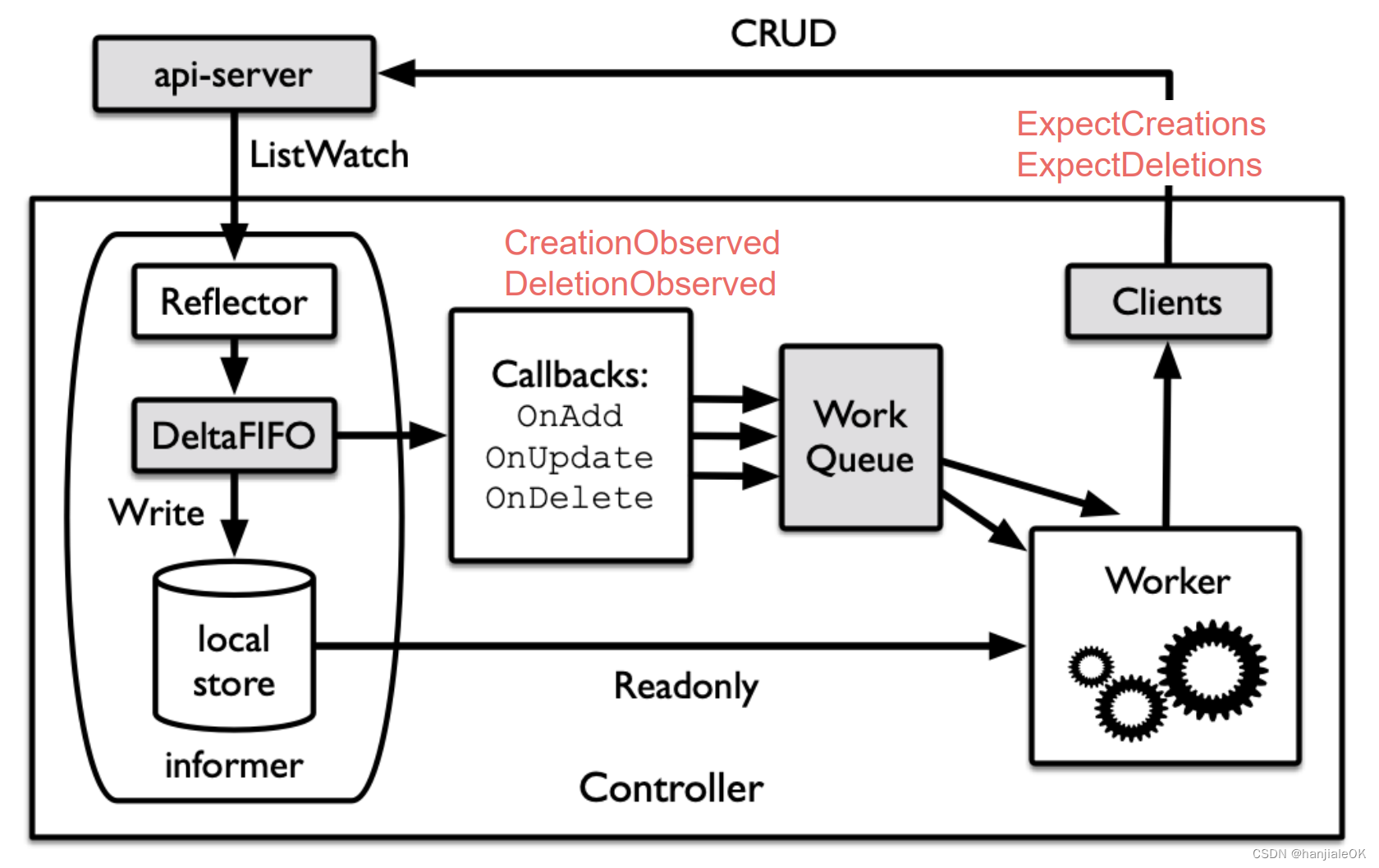
第二个要说的是adopt orphan(孤儿收养),这里涉及到一个k8s ownerReferences基础知识点,可以看看 Kubernetes Controller 如何管理资源 这篇文章了解一下。
k8s 中,资源的 metadata 中有几个对删除比较重要的属性:
- ownerReferences: 保存父资源的信息
- deletionTimestamp: 如果不为空,表明该资源正在被删除中
- finalizers: 当你告诉 Kubernetes 删除一个指定了 Finalizer 的对象时, Kubernetes API 通过填充 .metadata.deletionTimestamp 来标记要删除的对象, 并返回 202 状态码(HTTP “已接受”) 使其进入只读状态。 此时控制平面或其他组件会采取 Finalizer 所定义的行动, 而目标对象仍然处于终止中(Terminating)的状态。 这些行动完成后,控制器会删除目标对象相关的 Finalizer。 当 metadata.finalizers 字段为空时,Kubernetes 认为删除已完成并删除对象。
- ownerReferences.blockOwnerDeletion: 布尔,当前资源是否会阻塞父资源的删除流程,默认为true
Foreground cascading deletion
- 设置资源的 metadata.deletionTimestamp,表明该资源的状态为正在删除中(“deletion in progress”)。
- 设置资源的 metadata.finalizers 为 “foregroundDeletion”。
- 删除所有 ownerReference.blockOwnerDeletion=true 的子资源
- 删除当前资源
每一个子资源的 ownerReferences 字段里都有一个属性 ownerReferences.blockOwnerDeletion,这是一个
bool, 表明当前资源是否会阻塞父资源的删除流程。删除父资源前,应该把所有标记为阻塞的子资源都删光。在当前资源被删除以前,该资源都通过 apiserver 持续可见。
Orphan deletion
触发 FinalizerOrphanDependents,将所有子资源的 owner 清空,也就是令其成为 orphan。然后再删除当前资源。Background cascading deletion
立刻删除当前资源,然后在后台任务中删除子资源。foreground 和 orphan 删除策略是通过 finalizer 实现的 因为这两个策略有一些删除前必须要做的事情:
- foreground finalizer: 将所有的子资源放入删除事件队列
- orphan finalizer: 将所有的子资源的 owner 设为空
而 background 则就是走标准删除流程:删自己 -> 删依赖。
以上来自 Kubernetes Controller 如何管理资源
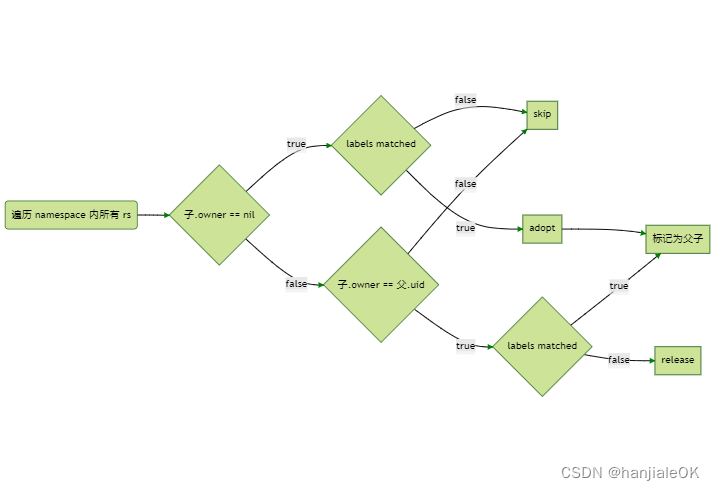
简而言之,一个deployment创建之后,k8s会相应创建一个replicaset和一些pod,replicaset的ownerReference便是deployment,而所有pod的ownerReference是replicaset。采用background方法删除deployment,deployment被删除时,会根据从属关系删除replicaset,replicaset删除时,会根据从属关系删除所有pod。
没有ownerReferences字段的pod被称为orphan(孤儿),可以通过clientset的Pod.Patch()操作把新的ownerReferences注入到pod里面,从而完成adoption(收养)。
这张图来自 Kubernetes Controller 如何管理资源,是replicaset controller的调谐时孤儿收养的逻辑,和下面等会提到的TFJob的孤儿收养逻辑几乎相同。
SetupWithManager
我们先分析TFJobReconciler.SetupWithManager函数,位置在 pkg/controller.v1/tensorflow/tfjob_controller.go。函数的入参是mgr和controllerThreads,前者是k8s的manager,管理着controller,后者决定进行reconcile的线程数。
func (r *TFJobReconciler) SetupWithManager(mgr ctrl.Manager, controllerThreads int) error {
首先是创建controller。
c, err := controller.New(r.ControllerName(), mgr, controller.Options{
Reconciler: r,
MaxConcurrentReconciles: controllerThreads,
})
我们看一下New函数的实现,在controller-runtime@v0.15.0/pkg/controller/controller.go。实际上是调用了NewUnmanaged这个函数,返回一个初始化了的Controller。可以看到TFJobReconcileryong用来初始化成员Do,controllerThreads的值用来初始化MaxConcurrentReconciles。这和上面controller-runtime源码分析部分是对应的。
// New returns a new Controller registered with the Manager. The Manager will ensure that shared Caches have
// been synced before the Controller is Started.
func New(name string, mgr manager.Manager, options Options) (Controller, error) {
c, err := NewUnmanaged(name, mgr, options)
if err != nil {
return nil, err
}
// Add the controller as a Manager components
return c, mgr.Add(c)
}
// NewUnmanaged returns a new controller without adding it to the manager. The
// caller is responsible for starting the returned controller.
func NewUnmanaged(name string, mgr manager.Manager, options Options) (Controller, error) {
// ...
// Create controller with dependencies set
return &controller.Controller{
Do: options.Reconciler,
MakeQueue: func() workqueue.RateLimitingInterface {
return workqueue.NewNamedRateLimitingQueue(options.RateLimiter, name)
},
MaxConcurrentReconciles: options.MaxConcurrentReconciles,
CacheSyncTimeout: options.CacheSyncTimeout,
Name: name,
LogConstructor: options.LogConstructor,
RecoverPanic: options.RecoverPanic,
LeaderElected: options.NeedLeaderElection,
}, nil
}
回到SetupWithManager函数,下一步是通过Controller.Watch来监控TFJob资源。前面controller-runtime源码分析提到,Kind的Type是kubeflowv1.TFJob{},cache则是引用了manager的Cache,用来提供informer。因为监控的是TFJob资源本身,所以事件处理用的是handler.EnqueueRequestForObject{},这些。断言函数则只有CreateFunc。Controller.Watch其实就是为informer指定监控TFJob资源并注册回调函数。按照流程,informer监控到TFJob资源的增删改变动后,会触发回调函数,首先通过断言函数进行判断,判断为true的事件才会通过EnqueueRequestForObject的处理函数把该TFJob对象转化为reconcile.request{namespace, name}推入工作队列。
// using onOwnerCreateFunc is easier to set defaults
if err = c.Watch(source.Kind(mgr.GetCache(), &kubeflowv1.TFJob{}), &handler.EnqueueRequestForObject{},
predicate.Funcs{CreateFunc: r.onOwnerCreateFunc()},
); err != nil {
return err
}
然后是通过Controller.Watch来监控pod和service资源。eventHandler使用的是EnqueueRequestForOwner,因为监控的资源是pod/service,而我们是想其父资源TFJob的信息推入工作队列。predicates的三个函数都是自定义的,我们等会以OnDependentCreateFunc为例看一看。这里的Controller.Watch其实就是为informer指定监控pod/service资源并注册回调函数。按照流程,informer监控到pod/service资源的增删改变动后,会触发回调函数,首先通过断言函数进行判断,判断为true的事件才会通过EnqueueRequestForOwner的处理函数把pod/service资源所隶属的TFJob对象转化为reconcile.request{namespace, name}推入工作队列。
// eventHandler for owned objects
eventHandler := handler.EnqueueRequestForOwner(mgr.GetScheme(), mgr.GetRESTMapper(), &kubeflowv1.TFJob{}, handler.OnlyControllerOwner())
predicates := predicate.Funcs{
CreateFunc: util.OnDependentCreateFunc(r.Expectations),
UpdateFunc: util.OnDependentUpdateFunc(&r.JobController),
DeleteFunc: util.OnDependentDeleteFunc(r.Expectations),
}
// Create generic predicates
genericPredicates := predicate.Funcs{
CreateFunc: util.OnDependentCreateFuncGeneric(r.Expectations),
UpdateFunc: util.OnDependentUpdateFuncGeneric(&r.JobController),
DeleteFunc: util.OnDependentDeleteFuncGeneric(r.Expectations),
}
// inject watching for job related pod
if err = c.Watch(source.Kind(mgr.GetCache(), &corev1.Pod{}), eventHandler, predicates); err != nil {
return err
}
// inject watching for job related service
if err = c.Watch(source.Kind(mgr.GetCache(), &corev1.Service{}), eventHandler, predicates); err != nil {
return err
}
OnDependentCreateFunc函数非常简单,首先判断这个pod的labels有无"training.kubeflow.org/replica-type"这个键,假设键值为"PS"。metav1.GetControllerOf(e.Object)可以获取该pod所属的TFJob,使用TFJob的namespace/name作为jobkey,继而生成的expectKey就是TFJob-namespace/TFJob-name/ps/pods。因为informer调用回调函数时,事件已经发生,即pod已经创建完成,因此此时通过exp.CreationObserved(expectKey)来降低期望。
// OnDependentCreateFunc modify expectations when dependent (pod/service) creation observed.
func OnDependentCreateFunc(exp expectation.ControllerExpectationsInterface) func(event.CreateEvent) bool {
return func(e event.CreateEvent) bool {
rtype := e.Object.GetLabels()[kubeflowv1.ReplicaTypeLabel]
if len(rtype) == 0 {
return false
}
//logrus.Info("Update on create function ", ptjr.ControllerName(), " create object ", e.Object.GetName())
if controllerRef := metav1.GetControllerOf(e.Object); controllerRef != nil {
jobKey := fmt.Sprintf("%s/%s", e.Object.GetNamespace(), controllerRef.Name)
var expectKey string
switch e.Object.(type) {
case *corev1.Pod:
expectKey = expectation.GenExpectationPodsKey(jobKey, rtype)
case *corev1.Service:
expectKey = expectation.GenExpectationServicesKey(jobKey, rtype)
default:
return false
}
exp.CreationObserved(expectKey)
return true
}
return true
}
}
下面是检查有没有部署volcano或者scheduler-plugins,从而使用Controller.Watch来监控podgroup资源。
// skip watching volcano PodGroup if volcano PodGroup is not installed
if _, err = mgr.GetRESTMapper().RESTMapping(schema.GroupKind{Group: v1beta1.GroupName, Kind: "PodGroup"},
v1beta1.SchemeGroupVersion.Version); err == nil {
// inject watching for job related volcano PodGroup
if err = c.Watch(source.Kind(mgr.GetCache(), &v1beta1.PodGroup{}), eventHandler, genericPredicates); err != nil {
return err
}
}
// skip watching scheduler-plugins PodGroup if scheduler-plugins PodGroup is not installed
if _, err = mgr.GetRESTMapper().RESTMapping(schema.GroupKind{Group: schedulerpluginsv1alpha1.SchemeGroupVersion.Group, Kind: "PodGroup"},
schedulerpluginsv1alpha1.SchemeGroupVersion.Version); err == nil {
// inject watching for job related scheduler-plugins PodGroup
if err = c.Watch(source.Kind(mgr.GetCache(), &schedulerpluginsv1alpha1.PodGroup{}), eventHandler, genericPredicates); err != nil {
return err
}
}
至此,SetupWithManager函数结束。总结就是创建一个controller,然后调用controller.Watch函数监听TFJob/pod/service资源并注册相应的回调函数。这样informer运行起来后就可以将这些资源的变动转化为reconcile.request推入工作队列。
Reconcile
现在我们看一下最核心的Reconcile函数,入参是ctx和req,后者便是从工作队列中取出的reconcile.request。
func (r *TFJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
下面根据req.NamespacedName从api server里获取这个TFJob资源。正常情况下这个TFJob是可以找到的,因为从工作队列中消费recioncile.request时,这个TFJob已经已经创建好了(informer调用增删改的回调函数时,事件已经发生,然后才会把recioncile.request推入队列)。
tfjob := &kubeflowv1.TFJob{}
err := r.Get(ctx, req.NamespacedName, tfjob)
if err != nil {
logger.Info(err.Error(), "unable to fetch TFJob", req.NamespacedName.String())
return ctrl.Result{}, client.IgnoreNotFound(err)
}
下面就是验证这个TFjob是否合法有效,无需细说。
if err = kubeflowv1.ValidateV1TFJob(tfjob); err != nil {
logger.Error(err, "TFJob failed validation")
r.Recorder.Eventf(tfjob, corev1.EventTypeWarning, commonutil.NewReason(kubeflowv1.TFJobKind, commonutil.JobFailedValidationReason),
"TFJob failed validation because %s", err)
return ctrl.Result{}, err
}
下面是检测expectation是否满足。jobKey的值就是tfjob-namespace/tfjob-name。根据这个jobKey检查对应的pod/service的expectation是否得到满足。
// Check if reconciliation is needed
jobKey, err := common.KeyFunc(tfjob)
if err != nil {
utilruntime.HandleError(fmt.Errorf("couldn't get jobKey for job object %#v: %v", tfjob, err))
}
replicaTypes := util.GetReplicaTypes(tfjob.Spec.TFReplicaSpecs)
needReconcile := util.SatisfiedExpectations(r.Expectations, jobKey, replicaTypes)
if !needReconcile || tfjob.GetDeletionTimestamp() != nil {
logger.Info("reconcile cancelled, job does not need to do reconcile or has been deleted",
"sync", needReconcile, "deleted", tfjob.GetDeletionTimestamp() != nil)
return ctrl.Result{}, nil
}
下面是SatisfiedExpectations函数,可以看出满足的条件是pod或者service其中一个的expectation被满足。至于这里为什么使用|| ?我认为是出于性能上的考虑,如果pod/service很少,那么这里&&或者||没啥区别,但是万一pod/service达到上千规模,那么达到满足&&的条件可能会很久,会导致reconcile间隔很久。但是reconcile间隔太少也不好,会增加api server的压力。因此取个折中。
// SatisfiedExpectations returns true if the required adds/dels for the given mxjob have been observed.
// Add/del counts are established by the controller at sync time, and updated as controllees are observed by the controller
// manager.
func SatisfiedExpectations(exp expectation.ControllerExpectationsInterface, jobKey string, replicaTypes []kubeflowv1.ReplicaType) bool {
satisfied := false
for _, rtype := range replicaTypes {
// Check the expectations of the pods.
expectationPodsKey := expectation.GenExpectationPodsKey(jobKey, string(rtype))
satisfied = satisfied || exp.SatisfiedExpectations(expectationPodsKey)
// Check the expectations of the services.
expectationServicesKey := expectation.GenExpectationServicesKey(jobKey, string(rtype))
satisfied = satisfied || exp.SatisfiedExpectations(expectationServicesKey)
}
return satisfied
}
下面是就是expectation.SatisfiedExpectations函数。满足条件主要有两种,一是Fulfilled,就是add和del期望均得到满足,即值均小于等于零,二是reconcile时间超时。
// SatisfiedExpectations returns true if the required adds/dels for the given controller have been observed.
// Add/del counts are established by the controller at sync time, and updated as controllees are observed by the controller
// manager.
func (r *ControllerExpectations) SatisfiedExpectations(controllerKey string) bool {
if exp, exists, err := r.GetExpectations(controllerKey); exists {
if exp.Fulfilled() {
log.Debugf("Controller expectations fulfilled %#v", exp)
return true
} else if exp.isExpired() {
log.Debugf("Controller expectations expired %#v", exp)
return true
} else {
log.Debugf("Controller still waiting on expectations %#v", exp)
return false
}
} else if err != nil {
log.Debugf("Error encountered while checking expectations %#v, forcing sync", err)
} else {
// When a new controller is created, it doesn't have expectations.
// When it doesn't see expected watch events for > TTL, the expectations expire.
// - In this case it wakes up, creates/deletes controllees, and sets expectations again.
// When it has satisfied expectations and no controllees need to be created/destroyed > TTL, the expectations expire.
// - In this case it continues without setting expectations till it needs to create/delete controllees.
log.Debugf("Controller %v either never recorded expectations, or the ttl expired.", controllerKey)
}
// Trigger a sync if we either encountered and error (which shouldn't happen since we're
// getting from local store) or this controller hasn't established expectations.
return true
}
// Fulfilled returns true if this expectation has been fulfilled.
func (e *ControlleeExpectations) Fulfilled() bool {
// TODO: think about why this line being atomic doesn't matter
return atomic.LoadInt64(&e.add) <= 0 && atomic.LoadInt64(&e.del) <= 0
}
回到,如果expecattion被满足或者上次reconcile超时,那么会再次进行reconcile!
// Set default priorities to tfjob
r.Scheme.Default(tfjob)
// Use common to reconcile the job related pod and service
err = r.ReconcileJobs(tfjob, tfjob.Spec.TFReplicaSpecs, tfjob.Status, &tfjob.Spec.RunPolicy)
if err != nil {
logrus.Warnf("Reconcile Tensorflow Job error %v", err)
return ctrl.Result{}, err
}
ReconcileJobs的代码在pkg/controller.v1/common/job.go。调谐的第一步是重置期望,因为既然执行本次调谐,说明之前的期望已经满足。
// Reset expectations
// 1. Since `ReconcileJobs` is called, we expect that previous expectations are all satisfied,
// and it's safe to reset the expectations
// 2. Reset expectations can avoid dirty data such as `expectedDeletion = -1`
// (pod or service was deleted unexpectedly)
if err = jc.ResetExpectations(jobKey, replicas); err != nil {
log.Warnf("Failed to reset expectations: %v", err)
}
下面是是清点已经存在的pods/services,收养符合要求的孤儿。
pods, err := jc.Controller.GetPodsForJob(job)
if err != nil {
log.Warnf("GetPodsForJob error %v", err)
return err
}
services, err := jc.Controller.GetServicesForJob(job)
if err != nil {
log.Warnf("GetServicesForJob error %v", err)
return err
}
这张图来自 Kubernetes Controller 如何管理资源,是replicaset controller的调谐时孤儿收养的逻辑,和TFJob的孤儿收养逻辑几乎相同。
下面是运行podgroup的同步,在podgroup被调度器调度为Inqueue状态前,需要阻塞pod的创建。这里先暂时按下不表。
syncReplicas := true
pg, err := jc.SyncPodGroup(metaObject, pgSpecFill)
if err != nil {
log.Warnf("Sync PodGroup %v: %v", jobKey, err)
syncReplicas = false
}
// Delay pods creation until PodGroup status is Inqueue
if jc.PodGroupControl.DelayPodCreationDueToPodGroup(pg) {
log.Warnf("PodGroup %v unschedulable", jobKey)
syncReplicas = false
}
下面开始对pods和services进行调谐,两者的逻辑差不多。TFJob中的pod角色一般是PS和Worker,使用for循环对每一种角色的pods/services进行调谐。
// Diff current active pods/services with replicas.
for rtype, spec := range replicas {
err := jc.Controller.ReconcilePods(metaObject, &jobStatus, pods, rtype, spec, replicas)
if err != nil {
log.Warnf("ReconcilePods error %v", err)
return err
}
err = jc.Controller.ReconcileServices(metaObject, services, rtype, spec)
if err != nil {
log.Warnf("ReconcileServices error %v", err)
return err
}
}
下面是ReconcilePods函数,位置在pkg/controller.v1/common/pod.go。首先是对上文中ReconcileJobs时清点的pods进行处理。
// GetPodSlices will return enough information here to make decision to add/remove/update resources.
//
// For example, let's assume we have pods with replica-index 0, 1, 2
// If replica is 4, return a slice with size 4. [[0],[1],[2],[]], a pod with replica-index 3 will be created.
//
// If replica is 1, return a slice with size 3. [[0],[1],[2]], pod with replica-index 1 and 2 are out of range and will be deleted.
podSlices := jc.GetPodSlices(pods, numReplicas, logger)
下面就是GetPodSlices函数,位置在pkg/core/pod.go。这个函数非常有用。入参中的pods就是上文中ReconcileJobs时清点的pods,replicas是该pod角色类型对应的总副本数。podSlices是一个二维数组,第一维是pod的index值,第二维是该index值对应的pod的数量。CalculatePodSliceSize会计算出 max(当前已存在的pod中index+1,replicas) 作为podSlices的第一维的大小。GetPodSlices比那里pods来统计那些index已经存在以及对应的pod数量。
// GetPodSlices returns a slice, which element is the slice of pod.
// It gives enough information to caller to make decision to up/down scale resources.
func GetPodSlices(pods []*v1.Pod, replicas int, logger *log.Entry) [][]*v1.Pod {
podSlices := make([][]*v1.Pod, CalculatePodSliceSize(pods, replicas))
for _, pod := range pods {
index, err := utillabels.ReplicaIndex(pod.Labels)
if err != nil {
logger.Warningf("Error obtaining replica index from Pod %s/%s: %v", pod.Namespace, pod.Name, err)
continue
}
if index < 0 || index >= replicas {
logger.Warningf("The label index is not expected: %d, pod: %s/%s", index, pod.Namespace, pod.Name)
}
podSlices[index] = append(podSlices[index], pod)
}
return podSlices
}
// CalculatePodSliceSize compare max pod index with desired replicas and return larger size
func CalculatePodSliceSize(pods []*v1.Pod, replicas int) int {
size := 0
for _, pod := range pods {
index, err := utillabels.ReplicaIndex(pod.Labels)
if err != nil {
continue
}
size = MaxInt(size, index)
}
// size comes from index, need to +1 to indicate real size
return MaxInt(size+1, replicas)
}
遍历刚刚统计的podSlices,
- 如果index对应的pod数量大于1,说明pod超过预期。
- 如果index对应的pod数量等于0,说明需要创建pod。
- 如果index对应的pod数量等于1,检查index是否超过范围,如果超过则需要删除pod,增加pod的del expectation。检查pod的状态和退出码。
for index, podSlice := range podSlices {
if len(podSlice) > 1 {
logger.Warningf("We have too many pods for %s %d", rt, index)
} else if len(podSlice) == 0 {
logger.Infof("Need to create new pod: %s-%d", rt, index)
// check if this replica is the master role
masterRole = jc.Controller.IsMasterRole(replicas, rType, index)
err = jc.createNewPod(job, rt, index, spec, masterRole, replicas)
if err != nil {
return err
}
} else {
// Check the status of the current pod.
pod := podSlice[0]
// check if the index is in the valid range, if not, we should kill the pod
if index < 0 || index >= numReplicas {
err = jc.PodControl.DeletePod(pod.Namespace, pod.Name, runtimeObject)
if err != nil {
return err
}
// Deletion is expected
jc.Expectations.RaiseExpectations(expectationPodsKey, 0, 1)
}
// ...
下面是createNewPod函数,这里是创建pod前给注入和podgroup相关的Annotations。
// if gang-scheduling is enabled:
// 1. if user has specified other scheduler, we report a warning without overriding any fields.
// 2. if no SchedulerName is set for pods, we set the SchedulerName to gang-scheduler-name.
if jc.Config.EnableGangScheduling() {
if isCustomSchedulerSet(replicas, jc.PodGroupControl.GetSchedulerName()) {
errMsg := "Another scheduler is specified when gang-scheduling is enabled and it will not be overwritten"
logger.Warning(errMsg)
jc.Recorder.Event(runtimeObject, v1.EventTypeWarning, podTemplateSchedulerNameReason, errMsg)
}
jc.PodGroupControl.DecoratePodTemplateSpec(podTemplate, metaObject, rt)
}
创建pod前,增加pod的add expectation。对pod失败的情况进行处理;
- 如果失败,且原因是超时,k8s会自动重试,最终创建成功后,informer会收到通知,触发回调函数从而降低期望。
- 如果其他原因失败,informer不会收到通知,需要手动降低期望,等待下次调谐。
// Creation is expected when there is no error returned
// We use `RaiseExpectations` here to accumulate expectations since `SetExpectations` has no such kind of ability
expectationPodsKey := expectation.GenExpectationPodsKey(jobKey, rt)
jc.Expectations.RaiseExpectations(expectationPodsKey, 1, 0)
controllerRef := jc.GenOwnerReference(metaObject)
err = jc.PodControl.CreatePodsWithControllerRef(metaObject.GetNamespace(), podTemplate, runtimeObject, controllerRef)
if err != nil && errors.IsTimeout(err) {
// Pod is created but its initialization has timed out.
// If the initialization is successful eventually, the
// controller will observe the creation via the informer.
// If the initialization fails, or if the pod keeps
// uninitialized for a long time, the informer will not
// receive any update, and the controller will create a new
// pod when the expectation expires.
return nil
} else if err != nil {
// Since error occurred(the informer won't observe this pod),
// we decrement the expected number of creates
// and wait until next reconciliation
jc.Expectations.CreationObserved(expectationPodsKey)
return err
}
创建pod前,增加pod的del expectation。对pod失败的情况进行处理;

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









