







What is Training Operator
Training Operator是一个Kubernetes原生项目,用于对使用各种ML框架(如PyTorch、TensorFlow、XGBoost等)创建的机器学习(ML)模型进行微调和可扩展的分布式训练。
用户可以将HuggingFace、DeepSpeed或Megatron LM等其他ML库与Training Operator集成,以协调他们在Kubernetes上的ML培训。
Training Operator允许您使用Kubernetes工作负载,通过Kubernete自定义资源API或使用Training Operator Python SDK有效地训练您的大型模型。
用户可以使用Training Operator和MPIJob运行高性能计算(HPC)任务,因为它支持在大量用于HPC的Kubernetes上运行消息传递接口(MPI)。
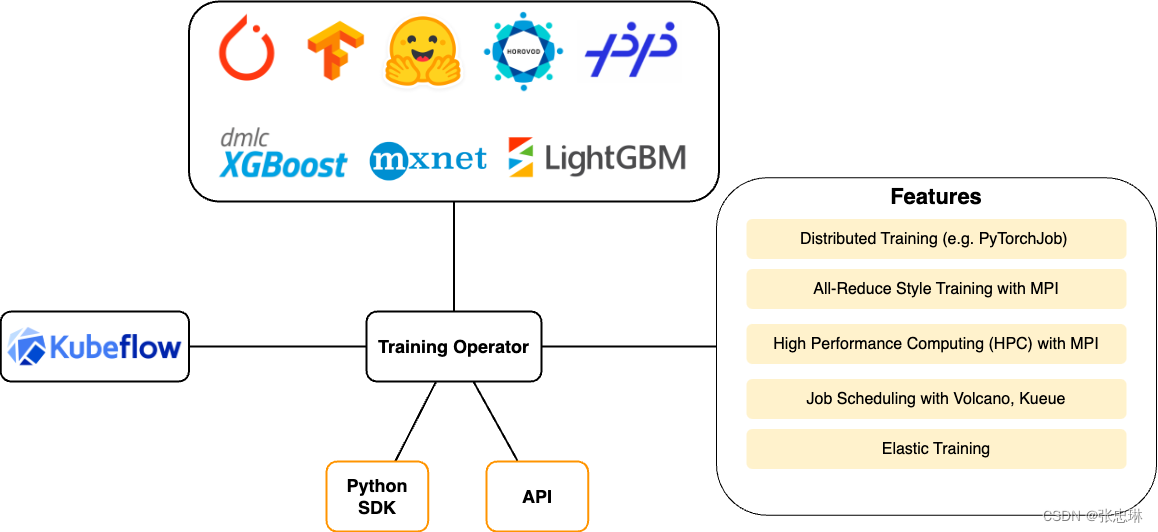
Training Operator负责调度适当的Kubernetes工作负载,以针对不同的ML框架实现各种分布式训练策略。
Why Training Operator
Training Operator解决了AI/ML生命周期中的模型训练和模型微调步骤,如图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









