









【业务梳理】
背景就是要从上亿条数据中过滤出被封禁的用户,如何处理
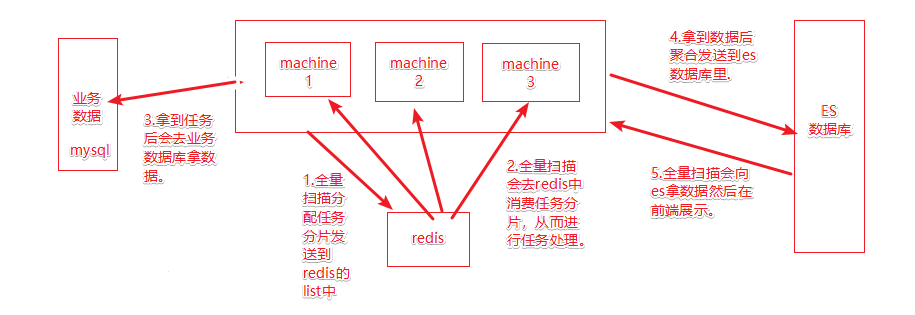
补充在第5部会使用must和mustnot命令过滤数据到前端展示
【实现方式】
本地测试环境,自己搭建了本地的elasticsearch,elasticsearch-head-master和kibana进行本地开发测试,需要加的逻辑主要在向redis拿到任务后去业务数据库中补充相关字段比如被封禁的用户信息,主贴被删的信息等等,然后在运行时发现被封禁的用户信息量在两百万左右,大量的数据信息需要做优化。
一开始主要是采用了将被封禁的用户信息先查出来放到set表中,在发送es时去set表中判断是否在里面从而判断改帖子用户是否被封禁,然后在向es拿数据时来过滤这个字段。在本地运行的时候没有什么问题,但是放到测试机上时,发现测试机的内存不够,明显这不是一个很好的方法。
后来使用了布隆过滤器来降低内存压力。在完成后利用测试数据库进行投毒测验。虽然这样的逻辑都没有问题,但是查询被封禁用户的sql运行的时间实在是太长了。
所以对项目又进行了重新优化,一共两步第一步是对sql进行分表查询的优化,第二步是对将sql查询出来的结果放到redis中,并且用xxl-job定时运行sql把数据存入redis里。在发送es时去redis里判断,系统瞬时丝滑了!
具体优化方案如下:
关于MySQL的like模糊查询优化情况
https://blog.csdn.net/weixin_43744732/article/details/123063007?spm=1001.2014.3001.5501
布隆过滤器总结
https://blog.csdn.net/weixin_43744732/article/details/123066773?spm=1001.2014.3001.5501
Mysql分页查询优化
https://blog.csdn.net/weixin_43744732/article/details/123096227?spm=1001.2014.3001.5501















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









