









 本文分享了爬取微博超话的实战经验,包括技术难点、分页参数寻找技巧及数据可视化分析,如用户年龄、性别分布等。
本文分享了爬取微博超话的实战经验,包括技术难点、分页参数寻找技巧及数据可视化分析,如用户年龄、性别分布等。
文章目录
Sina_Topic_Spider:
- 内容: 爬取某位明星的微博超话的上万条用户信息,对爬取的结果进行EDA分析与数据可视化,如分析用户年龄,性别分布、粉丝团的地区分布,词云打榜微博内容。
- 详细代码在Github:https://github.com/why19970628/Python_Crawler/tree/master/Sina_topic_spider
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★★☆☆
技术难点总结:
1.爬取微博超话用户信息
1. 查看网页数据
手动进入微博超话页面,改为手机版,过滤请求,只查看异步请求,查看返回数据的格式。
地址:手机版微博超话
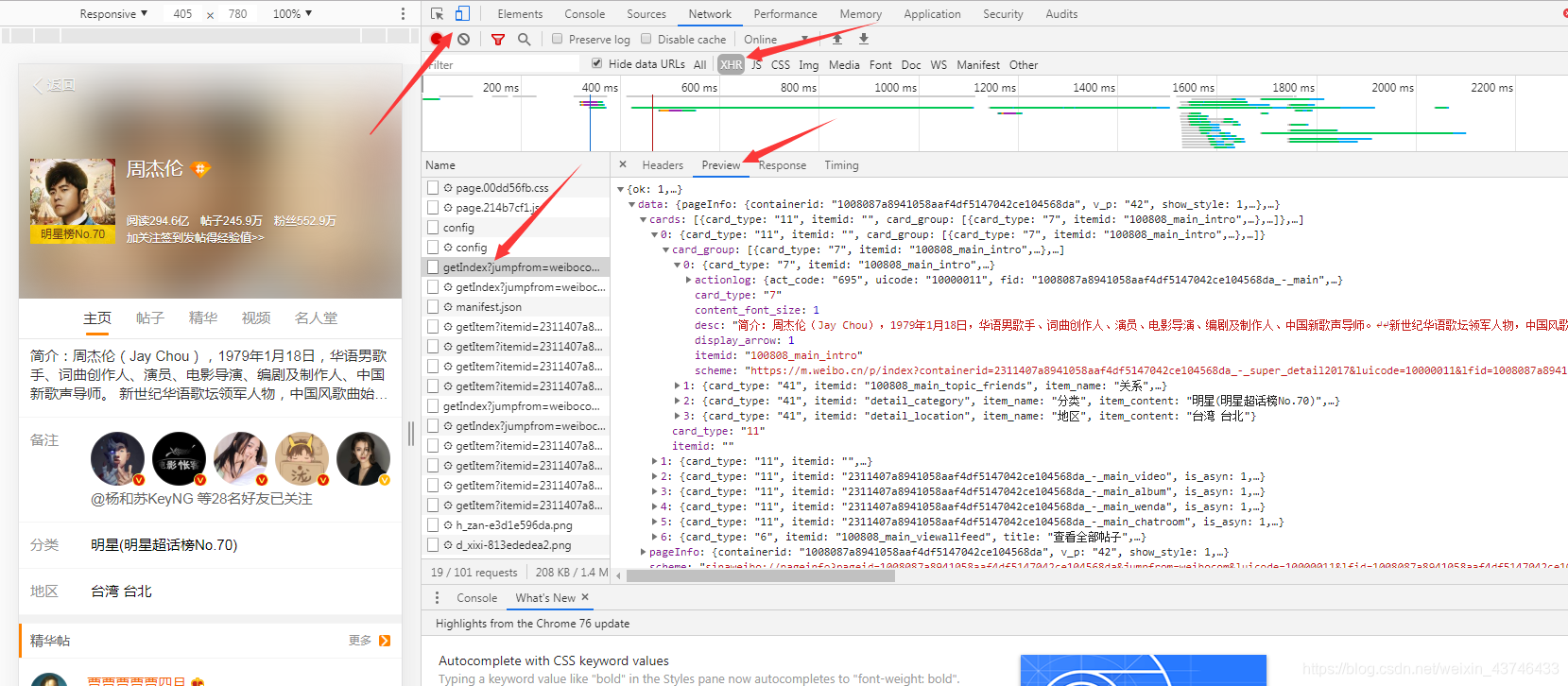
2. 模拟请求数据,提取微博内容。
数据返回的是Josn格式,可以加载放在txt文件中进行筛选数据(遍历)
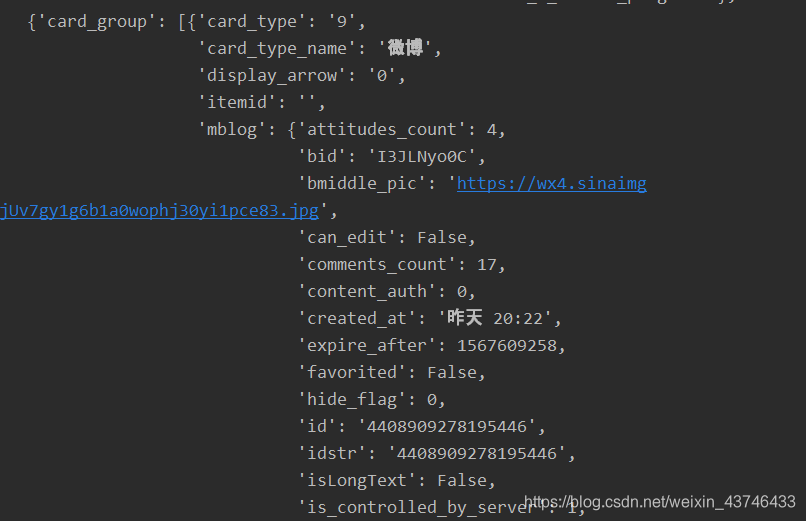
3. 遍寻找分页参数技巧
查找分页参数技巧:比较第一次和第二次请求url,看看有何不同,找出不同的参数!
比较两次请求的URL发现,第二次比第一次请求链接中多了一个:since_id参数,而这个since_id参数就是每条微博的id!
微博分页机制:根据时间分页,每一条微博都有一个since_id,时间越大的since_id越大所以在请求时将since_id传入,则会加载对应话题下比此since_id小的微博,然后又重新获取最小since_id将最小since_id传入,依次请求,这样便实现分页。
了解微博分页机制之后,我们就可以制定我们的分页策略:
我们将上一次请求返回的微博中最小的since_id作为下次请求的参数,这样就等于根据时间倒序分页抓取数据!
def spider_topic:
# 每次请求中最小的since_id,下次请求使用,新浪分页机制
min_since_id = ''
global min_since_id #全局变量
topic_url = 'https://m.weibo.cn/api/container/getIndexjumpfrom=weibocom&containerid=1008087a8941058aaf4df5147042ce104568da_-_feed'
if min_since_id:
topic_url = topic_url + '&since_id=' + min_since_id #分页
r_since_id = mblog['id'] #遍历获取每页微博id
if min_since_id:
min_since_id = r_since_id if min_since_id > r_since_id else min_since_id
else:
min_since_id = r_since_id
# 5、爬取用户信息不能太频繁,所以设置一个时间间隔
time.sleep(random.randint(3, 6))
# 批量爬取
for i in range(100):
print('第%d页' % (i + 1))
spider_topic()
4. 爬取用户信息
1.用户基本信息网址为 https://weibo.cn/用户id/info ,我们只需拿到用户id就可以得到用户信息。
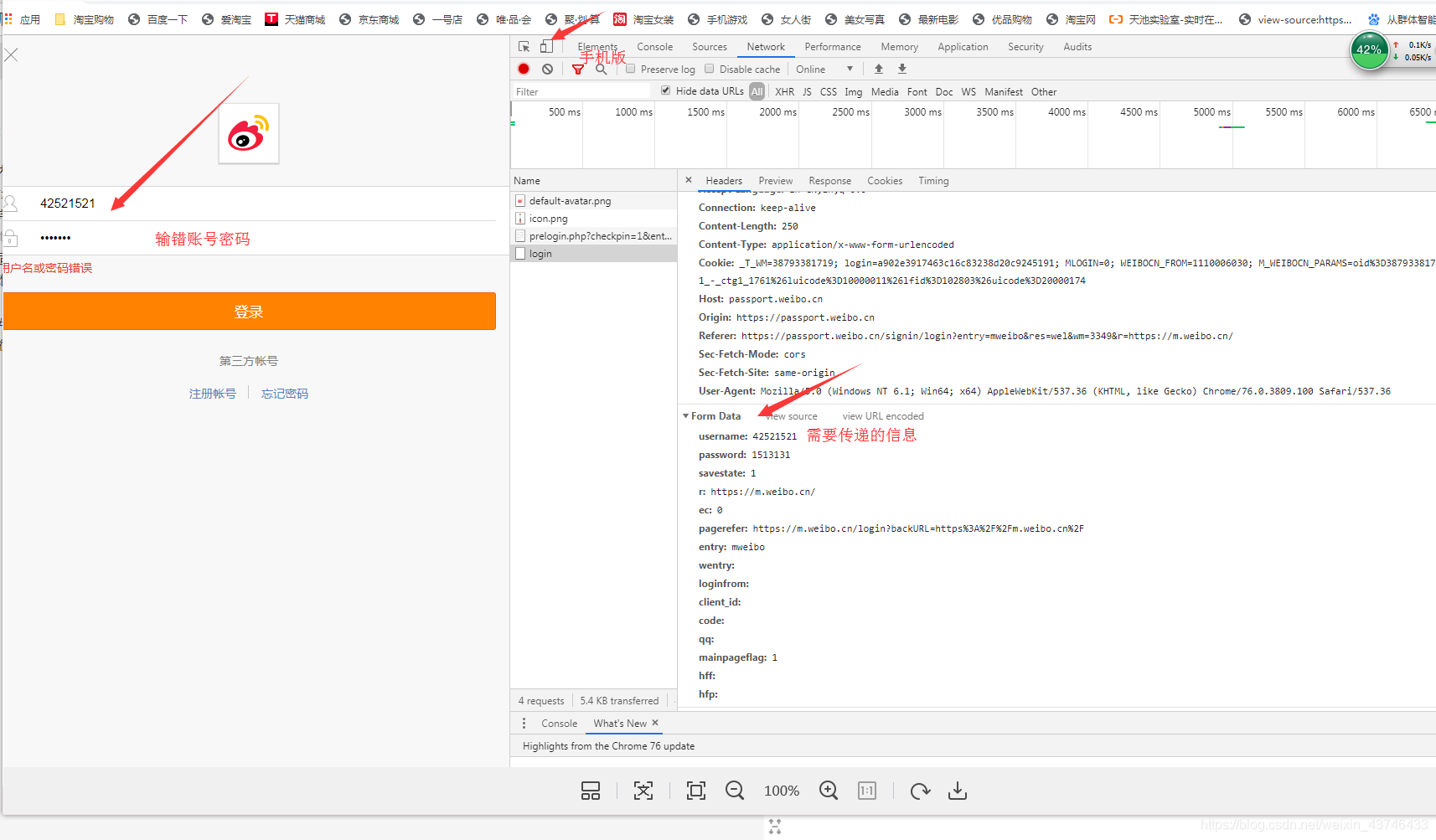
2.访问别人用户信息需要模拟微博登录
需要使用手机版,并且输错账号,获取Form Data传递参数
登录我们使用的是requests.Session()对象,这个对象会自动保存cookies,下次请求自动带上cookies!
3. 爬取用户信息
爬取用户信息不能频繁,响应代码(418),
有些用户没有生日自动添加为空值,
爬取信息的时候一定要加 try- except 防止爬取信息提取错误,代码挂掉
def get_basic_info_list(basic_info_html) -> list:
"""
将html解析提取需要的字段
:param basic_info_html:
:return: ['用户名', '性别', '地区', '生日']
"""
basic_infos = []
basic_info_kvs = basic_info_html[0].split('<br/>')
print(basic_info_kvs)
for basic_info_kv in basic_info_kvs:
if basic_info_kv.startswith('昵称'):
basic_infos.append(basic_info_kv.split(':')[1])
elif basic_info_kv.startswith('性别'):
basic_infos.append(basic_info_kv.split(':')[1])
elif basic_info_kv.startswith('地区'):
area = basic_info_kv.split(':')[1]
# 如果地区是其他的话,就添加空
if '其他' in area or '海外' in area:
basic_infos.append('')
continue
# 浙江 杭州,这里只要省
if ' ' in area:
area = area.split(' ')[0]
basic_infos.append(area)
elif basic_info_kv.startswith('生日'):
try:
birthday = basic_info_kv.split(':')[1]
# 19xx 年和20xx 带年份的才有效,只有月日或者星座的数据无效
if birthday.startswith('19') or birthday.startswith('20'):
# 只要前三位,如198、199、200分别表示80后、90后和00后,方便后面数据分析
basic_infos.append(birthday[:3])
else:
basic_infos.append('')
except:
if len(basic_infos) < 4:
basic_infos.append('')
else:
pass
# 有些用户的生日是没有的,所以直接添加一个空字符
if len(basic_infos) < 4:
basic_infos.append('')
return basic_infos
5. 保存文件
for card in card_group:
# 创建保存数据的列表,最后将它写入csv文件
sina_columns = []
mblog = card['mblog']
# 2.2、解析用户信息
user = mblog['user']
# 爬取用户信息,微博有反扒机制,频率太快就请求就返回418
try:
basic_infos = spider_user_info(user['id'])
#print(basic_infos)
except:
print('用户信息爬取失败!id=%s' % user['id'])
continue
# 把用户信息放入列表
sina_columns.append(user['id'])
sina_columns.extend(basic_infos)
.....
def save_columns_to_csv(columns, encoding='utf-8'):
"""
将数据保存到csv中
数据格式为:'用户id', '用户名', '性别', '地区', '生日', '微博id', '微博内容'
:param columns: ['用户id', '用户名', '性别', '地区', '生日', '微博id', '微博内容']
:param encoding:
:return:
"""
with open(CSV_FILE_PATH, 'a', encoding=encoding,newline="") as csvfile:
csv_write = csv.writer(csvfile)
csv_write.writerow(columns)
2.数据可视化


代码:
import csv
import collections
import jieba.analyse
from pyecharts import options as opts
from pyecharts.globals import SymbolType
from pyecharts.charts import Pie, Bar, Map, WordCloud
# 新浪话题数据保存文件
CSV_FILE_PATH = 'sina_topic.csv'
# 需要清洗的词
STOP_WORDS_FILE_PATH = 'stop_words.txt'
def read_csv_to_dict(index) -> dict:
"""
读取csv数据
数据格式为:'用户id', '用户名', '性别', '地区', '生日', '微博id', '微博内容'
:param index: 读取某一列 从0开始
:return: dic属性为key,次数为value
"""
with open(CSV_FILE_PATH, 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
column = [columns[index] for columns in reader]
dic = collections.Counter(column)
# 删除空字符串
if '' in dic:
dic.pop('')
print(dic)
return dic
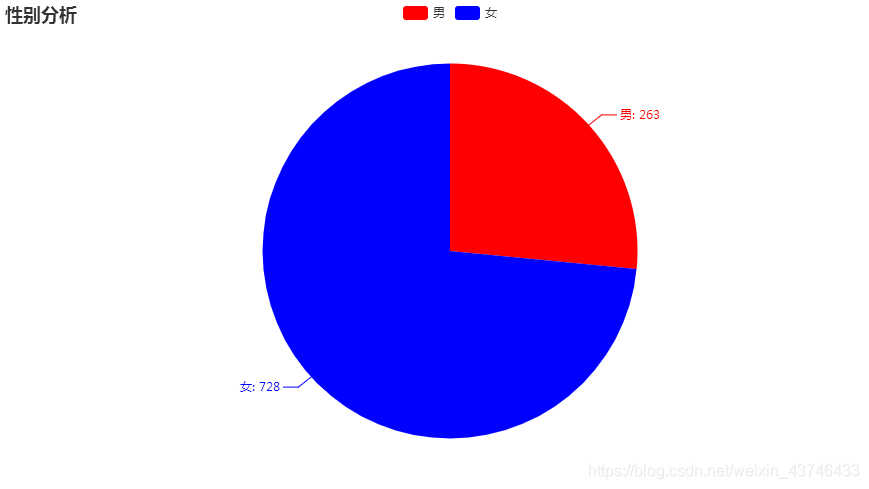
def analysis_gender():
"""
分析性别
:return:
"""
# 读取性别列
dic = read_csv_to_dict(2)#Counter({'女': 728, '男': 263})
# 生成二维数组
gender_count_list = [list(z) for z in zip(dic.keys(), dic.values())]# z [('男', 263), ('女', 728)]
print(gender_count_list)#[['男', 263], ['女', 728]]
pie = (
Pie()
.add("", gender_count_list)
.set_colors(["red", "blue"])
.set_global_opts(title_opts=opts.TitleOpts(title="性别分析"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('gender.html')
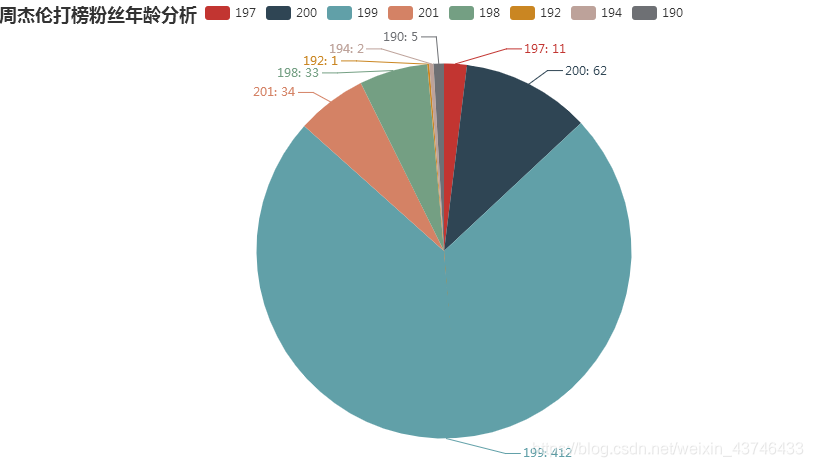
def analysis_age():
"""
分析年龄
:return:
"""
dic = read_csv_to_dict(4)
# 生成柱状图
sorted_dic = {}
for key in sorted(dic):
sorted_dic[key] = dic[key]
print(sorted_dic)
bar = (
Bar()
.add_xaxis(list(sorted_dic.keys()))
.add_yaxis("周杰伦打榜粉丝年龄分析", list(sorted_dic.values()))
.set_global_opts(
yaxis_opts=opts.AxisOpts(name="数量"),
xaxis_opts=opts.AxisOpts(name="年龄"),
)
)
bar.render('age_bar.html')
# 生成饼图
age_count_list = [list(z) for z in zip(dic.keys(), dic.values())]
pie = (
Pie()
.add("", age_count_list)
.set_global_opts(title_opts=opts.TitleOpts(title="周杰伦打榜粉丝年龄分析"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('age-pie.html')
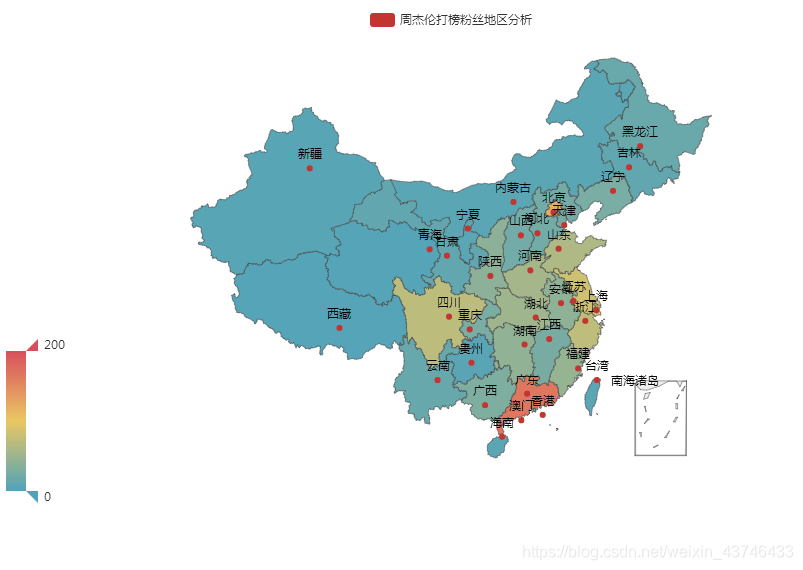
def analysis_area():
"""
分析地区
:return:
"""
dic = read_csv_to_dict(3)
area_count_list = [list(z) for z in zip(dic.keys(), dic.values())]
print(area_count_list)
map = (
Map()
.add("周杰伦打榜粉丝地区分析", area_count_list, "china")
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=200),
)
)
map.render('area.html')
def analysis_sina_content():
"""
分析微博内容
:return:
"""
# 读取微博内容列
dic = read_csv_to_dict(6)
# Counter({'我太难了': 3, '超话粉丝大咖': 2,
# 数据清洗,去掉无效词
jieba.analyse.set_stop_words(STOP_WORDS_FILE_PATH)
# 词数统计
words_count_list = jieba.analyse.textrank(' '.join(dic.keys()), topK=50, withWeight=True)
print(words_count_list)
#('杭州', 1.0), ('演唱会', 0.9047694519491188), ('抢到', 0.4155709853243528),
# 生成词云
word_cloud = (
WordCloud()
.add("", words_count_list, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="周杰伦打榜微博内容分析"))
)
word_cloud.render('word_cloud.html')
if __name__ == '__main__':
#analysis_gender()
#analysis_age()
analysis_area()
#analysis_sina_content()

















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









